

A challenge was posted recently on LinkedIn to provide an algorithm to determine the longest palindrome in a specified string. It proved to be fairly straightforward to handle the problem in a single line of Mathematica code, as follows:
teststring = "ItellyoumadamthecatisnotacivicanimalalthoughtisdeifiedinEgypt";nlargest = 5;TakeLargestBy[Cases[StringCases[teststring, __, Overlaps -> All], _?PalindromeQ], StringLength, nlargest] // Flatten
which produces the n largest palindromes, in this case:
{"deified", "acivica", "madam", "civic", "eifie"}My offering was fairly quickly superseded by a faster and more elegant solution from another Mathematica aficionado:
MaximalBy[StringCases[teststring, x : Repeated[_, {2, \[Infinity]}]
/; PalindromeQ[x], Overlaps -> True], StringLength, nlargest]
The Code
I have written previously about some of the new developments in programming languages, for example:
http://jonathankinlay.com/2014/12/just-time-programming-grows-up/
http://jonathankinlay.com/2015/02/comparison-programming-languages/
The joy of high-level, functional programming languages like Mathematica is that they often allow complex tasks to be accomplished easily, or at least in very few lines of code, compared to procedural languages like C, C++, Java or Python. The latter would probably require at least a dozen lines of code to achieve what Mathematica is able to accomplish in just one: see, for example, the table below, which compares the relative verbosity of various programming languages, including Mathematica.
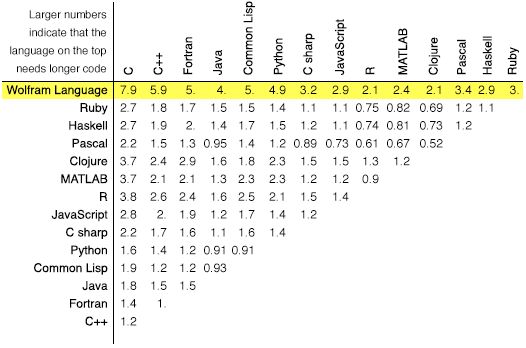
Source: Wolfram Research

We can compare “tokens,” or any string of letters and numbers that are not interrupted by a number or punctuation. This lets us classify length in terms of “units of syntax,” which, while it isn’t perfect, gives us a clearer picture of the number of different elements required to build a function or program. Below, the Wolfram Language appears to, on average, increase in token count at a slower rate than Python. Using FindFit, we can estimate that a typical Python program that requires x tokens can be written in the Wolfram Language with 3.48![]() tokens, meaning a Python program that requires 1,000 tokens would require just 110 tokens in the Wolfram Language.
tokens, meaning a Python program that requires 1,000 tokens would require just 110 tokens in the Wolfram Language.
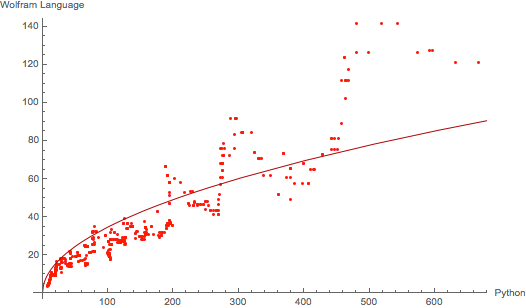
Source: Wolfram Research
So what is the message here?
For now, let me skate over the question of execution speed, typically the foremost objection that arises at this stage of the endless argument about interpreted vs. compiled programming languages. I promise to return to that topic very shortly. Instead let me first point out an often underestimated obstacle one faces in programming in Mathematica: the idiom. It can sometimes take as long to figure out the correct programming method in a single line of Mathematica code as it might take to code an algorithm more prosaically in a relatively verbose language like Java. And even after you have successfully achieved the goal, you are left with the challenge of understanding your own code when you return to it, perhaps months (or years) later. Even worse, you may have to disentangle the complex prose of another Mathematica programmer.
On the plus side, one of the great advantages of languages like Mathematica is that programs are largely a compilation of functions. So one assembles programs piece by piece, testing the functionality of each component function before adding another layer of complexity. Reverse engineering a Mathematica program – no matter how complex – follows roughly the same process, in reverse: in the above code you would first try to understand what the function MaximalBy does, then StringCases, then PalindromeQ (that one is fairly obvious!). The nature of functional programming languages makes it straightforward to assemble complex pieces of code from relatively simple sub-components, and also to reverse the process to dis-assemble them. The interpretative nature of the language is helpful here, too, since one can (unit) test each component on the fly, something that is much more tedious to do in a compiled language.
The Algorithm
In everyday usage we often conflate the terms “algorithm” and “code”. The code given above is an implementation of an algorithm, but it is not the algorithm itself. An algorithm is a recipe or sequence of steps that will produce a specified result. It can be written down as a series of instructions, in English or any other language, just as easily as a computer language and can be executed manually, if necessary. During WWII, before the advent of modern computers, large teams of women were employed to do just that:

In the case of the present example the algorithm runs something like this:
- Examine every substring of the string
- Test each substring to see if it is a palindrome
- Add any that are palindromes to the list
- Sort the list of substrings by string length
- Pick the n longest substrings
In principle, there is nothing to prevent us executing the algorithm by hand, except possibly time and boredom. Computer code is just a very much more convenient and efficient means of execution. But this usefulness can give rise to a kind of mental laziness, in which we focus on the problem of producing the most elegant computer code, rather than the most efficient algorithm. We have, in essence, got the problem turned around: we should first think about the algorithm and only then begin to think about how we might implement it. Not proceeding in that logical fashion risks producing solutions that are distinctly sub-optimal, whatever the efficiency and elegance of the implemented code.
In this case, we have used a “brute force” algorithm that examines every substring for possible palindromes. This is highly inefficient, scaling with the square of the number of characters n in the string, i.e. O(n^2). To see this, consider the 4-character string “abcd”. There are a total of 10 substrings:
- 4 single character substrings: {a, b, c, d}
- 3 two-character substrings: {ab, bc, cd}
- 2 three-character substrings {abc, bcd}
- 1 four-character string {abcd}
In general, for a string of length n, there are:
- n single-character substrings,
- (n-1) 2-character substrings,
. . . . . . . . . . . . ,
- 2 substrings length n-1
- and a single string length n.
So the total number of substrings is:
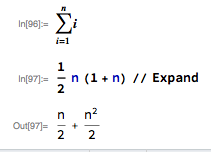
Let’s demonstrate the inefficiency of the algorithm using Virgil’s Aeneid as our source of palindromes – perhaps not the smartest choice, given the nature of poetry!
Aeneid = ExampleData[{"Text", "AeneidEnglish"}]; StringLength[Aeneid] 606071 teststring = StringTake[Aeneid, 1000]; nlargest = 20; StringTake[teststring, 100] I Arms, and the man I sing, who, forc'd by fate, And haughty Juno's unrelenting hate, Expell'dMaximalBy[StringCases[teststring, x : Repeated[_, {2, \[Infinity]}] /; PalindromeQ[x], Overlaps -> True], StringLength, nlargest] // Timing{12.1068, {" I ", " I ", "ele", "t t", "a a", "t t", "ivi", "g g", " O ", "ses", "ovo", " a ", "s s", "h h", "ese", "exe", "t t", "awa", "t t", "s s"}
It takes a full 12 seconds to find the 20 largest palindromes in only the first 1,000 characters of the 600,00 character text.
If we double the length of the test string, the execution time increases by a factor of over 4x:
teststring = StringTake[Aeneid, 2000];MaximalBy[StringCases[teststring, x : Repeated[_, {2, \[Infinity]}] /; PalindromeQ[x], Overlaps -> True], StringLength, nlargest] // Timing{56.4254, {" I ", " I ", "ele", "t t", "a a", "t t", "ivi", "g g"," O ", "ses", "ovo", " a ", "s s", "h h", "ese", "exe", "t t", "awa", "t t", "s s"}
Improving the Algorithm
It is clear that even if we succeed in speeding up the code, the inefficiency of the algorithm will render it useless for all but the shortest strings – scanning the entire Aeneid for palindromes would take the algorithm at least 100 hours!
Fortunately, in 1975 Glenn Manacher came up with a much smarter algorithm that scales linearly with the length of the string, which you can read about here. In essence his approach exploits the symmetry in palindromes to reduce the search time.
An implementation of Manacher’s algorithm in Mathematica is given below. The code executes extremely quickly, taking only around a quarter of a second to scan the entire 600,000 character text of the Aeneid to find the longest palindrome (“man nam”).
AbsoluteTiming[findLongestPalindrome[Aeneid]] (* {0.236135, "man nam"} *)
A large part of the speed enhancement is due to the much greater efficiency of Manacher’s algorithm. Notice, too, however, that further significant speed gains are made by compiling the Mathematica code via C, which Mathematica is able to do as standard.
Doc, note: I dissent. A fast never prevents a fatness. I diet on cod
– Mathematician Peter Hilton

Conclusion
The lessons here are, firstly, to focus on the problem of the algorithm rather than the code, clearly distinguishing between the two.
Secondly, the complex idiom of functional programming languages like Mathematica can complicate the task of programming an algorithm, or understanding code written by others. On the other hand, the brevity of the language makes it easier to get an overview of the functionality of a program, while the functional structure makes the process of assembling – or disassembling – complex programs at least logically coherent.
Finally, it is important to understand that modern interpreted functional languages like Mathematica are a great deal more viable as production systems than they ever used to be, thanks to the introduction of capabilities to produce compiled code.
Appendix – Manacher Palindrome Algorithm Mathematica Code
findLongestPalindrome[""] = "";
findLongestPalindrome[s_String] :=
FromCharacterCode @ findLongestPalindromeList[ToCharacterCode @ s];
findLongestPalindromeList = Compile[{{s, _Integer, 1}},
Module[{s2, p, c, r, n, m, i2, len, cc},
s2 = Riffle[s, -1, {1, -1, 2}];
p = ConstantArray[0, Length[s2]];
c = 1; r = 1; m = 1; n = 1; len = 0; cc = 1;
Do[
If[i > r,
p[[i]] = 0; m = i - 1; n = i + 1,
i2 = 2 c - i;
If[p[[i2]] < (r - i),
p[[i]] = p[[i2]]; m = 0,
p[[i]] = r - i; n = r + 1; m = 2 i - n
]
];
If[OddQ[m],p[[i]]++; m--; n++];
While[m > 0 && n <= Length[s2] && s2[[m]] == s2[[n]],
p[[i]] += 2; m -= 2; n += 2;
];
If[(i + p[[i]]) > r,
c = i; r = i + p[[i]];
];
If[len < p[[i]],
len = p[[i]]; cc = i;
],
{i,2,Length[s2]}
];
s[[Quotient[cc - len + 1, 2] ;; Quotient[cc + len - 1, 2]]]
]
]