

In my last post I mapped out how one could test the reliability of a single stock strategy (for the S&P 500 Index) using synthetic data generated by the new algorithm I developed.
As this piece of research follows a similar path, I won’t repeat all those details here. The key point addressed in this post is that not only are we able to generate consistent open/high/low/close prices for individual stocks, we can do so in a way that preserves the correlations between related securities. In other words, the algorithm not only replicates the time series properties of individual stocks, but also the cross-sectional relationships between them. This has important applications for the development of portfolio strategies and portfolio risk management.
KO-PEP Pair
To illustrate this I will use synthetic daily data to develop a pairs trading strategy for the KO-PEP pair.
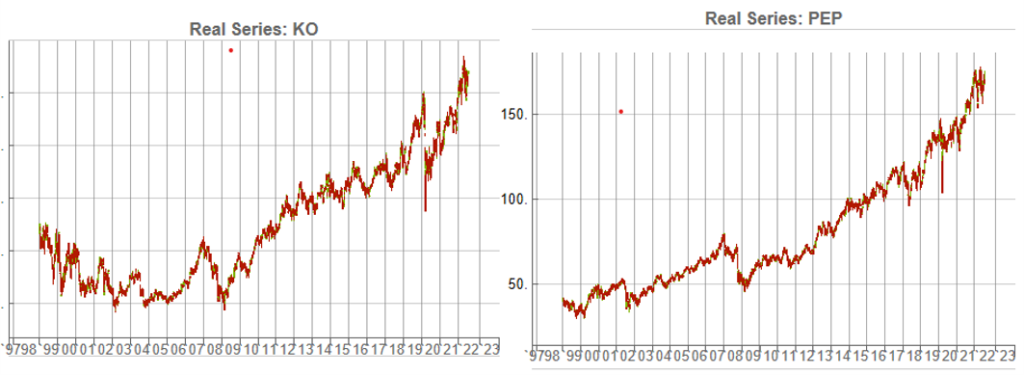
The two price series are highly correlated, which potentially makes them a suitable candidate for a pairs trading strategy.
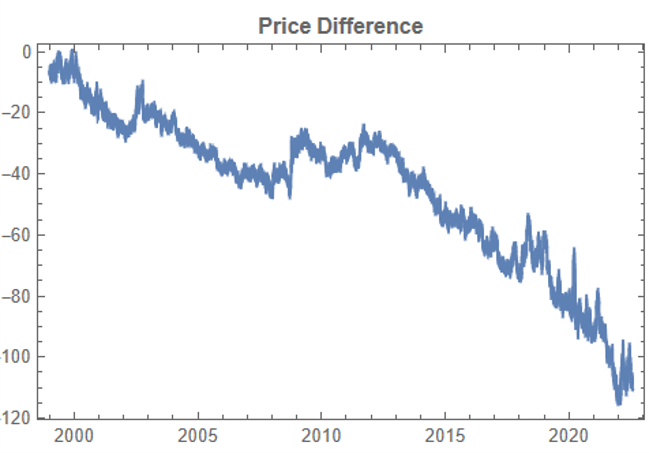
There are numerous ways to trade a pairs spread such as dollar neutral or beta neutral, but in this example I am simply going to look at trading the price difference. This is not a true market neutral approach, nor is the price difference reliably stationary. However, it will serve the purpose of illustrating the methodology.
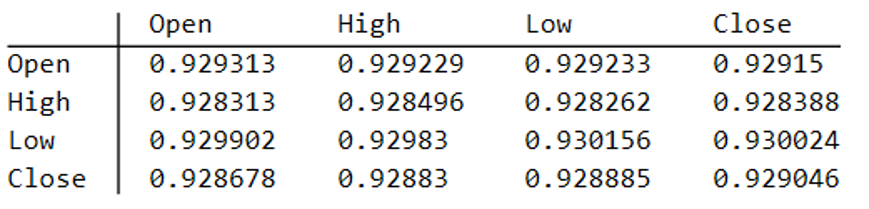
Obviously it is crucial that the synthetic series we create behave in a way that replicates the relationship between the two stocks, so that we can use it for strategy development and testing. Ideally we would like to see high correlations between the synthetic and original price series as well as between the pairs of synthetic price data.
We begin by using the algorithm to generate 100 synthetic daily price series for KO and PEP and examine their properties.
Correlations
As we saw previously, the algorithm is able to generate synthetic data with correlations to the real price series ranging from below zero to close to 1.0:
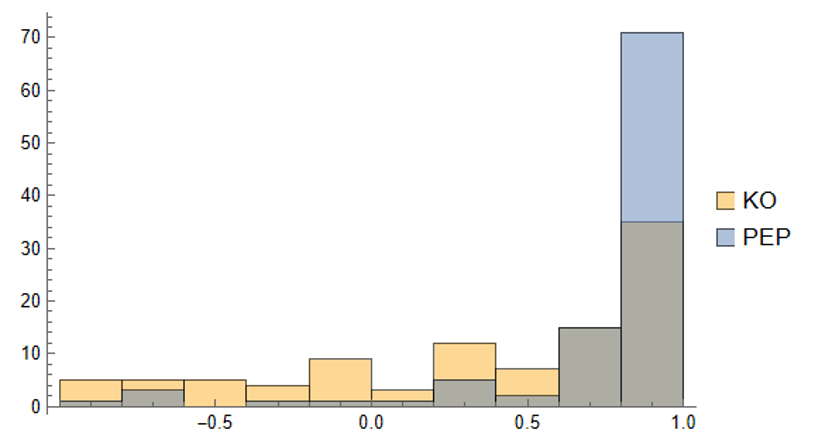
The crucial point, however, is that the algorithm has been designed to also preserve the cross-sectional correlation between the pairs of synthetic KO-PEP data, just as in the real data series:
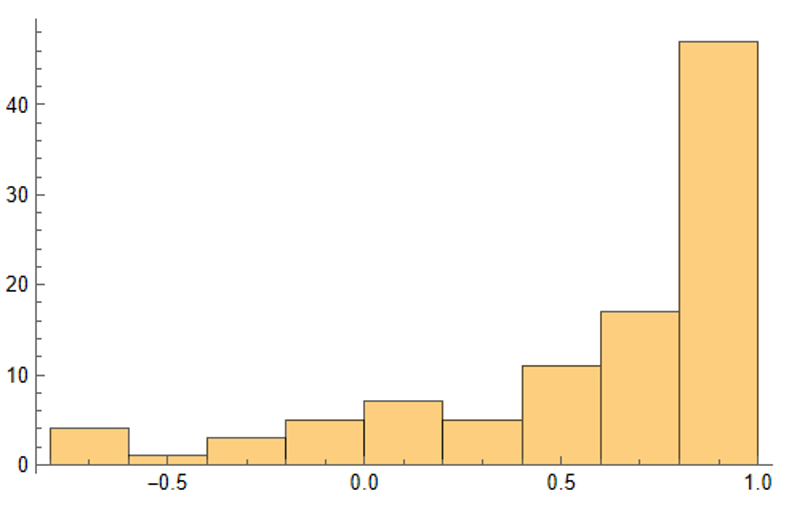
Some examples of highly correlated pairs of synthetic data are shown in the plots below:
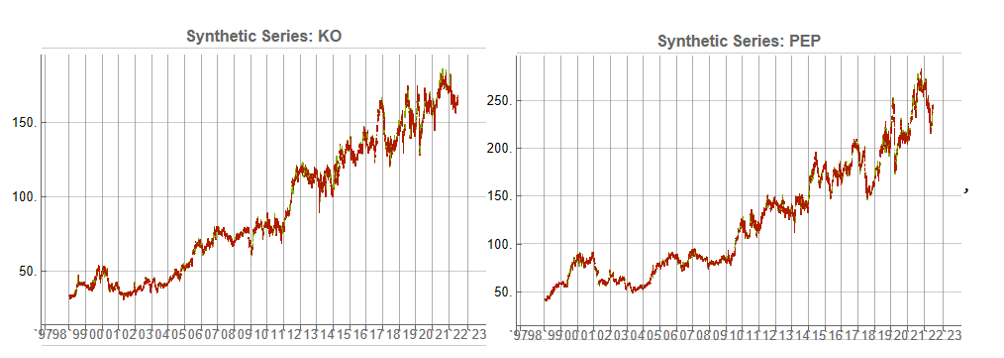
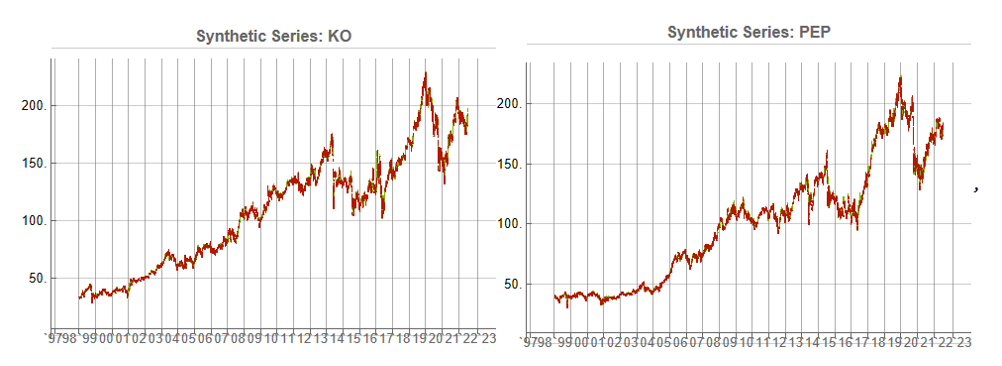
In addition to correlation, we might also want to consider the price differences between the pairs of synthetic series, since the strategy will be trading that price difference, in the simple approach adopted here. We could, for example, select synthetic pairs for which the divergence in the price difference does not become too large, on the assumption that the series difference is stationary. While that approach might well be reasonable in other situations, here an assumption of stationarity would be perhaps closer to wishful thinking than reality. Instead we can use of selection of synthetic pairs with high levels of cross-correlation, as we all high levels of correlation with the real price data. We can also select for high correlation between the price differences for the real and synthetic price series.
Strategy Development & WFO Testing
Once again we follow the procedure for strategy development outline in the previous post, except that, in addition to a selection of synthetic price difference series we also include 14-day correlations between the pairs. We use synthetic daily synthetic data from 1999 to 2012 to build the strategy and use the data from 2013 onwards for testing/validation. Eventually, after 50 generations we arrive at the result shown in the figure below:
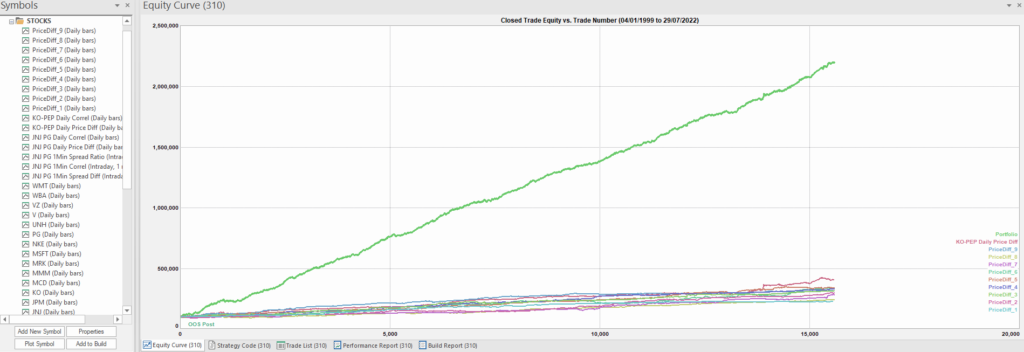
As before, the equity curve for the individual synthetic pairs are shown towards the bottom of the chart, while the aggregate equity curve, which is a composition of the results for all none synthetic pairs is shown above in green. Clearly the results appear encouraging.
As a final step we apply the WFO analysis procedure described in the previous post to test the performance of the strategy on the real data series, using a variable number in-sample and out-of-sample periods of differing size. The results of the WFO cluster test are as follows:
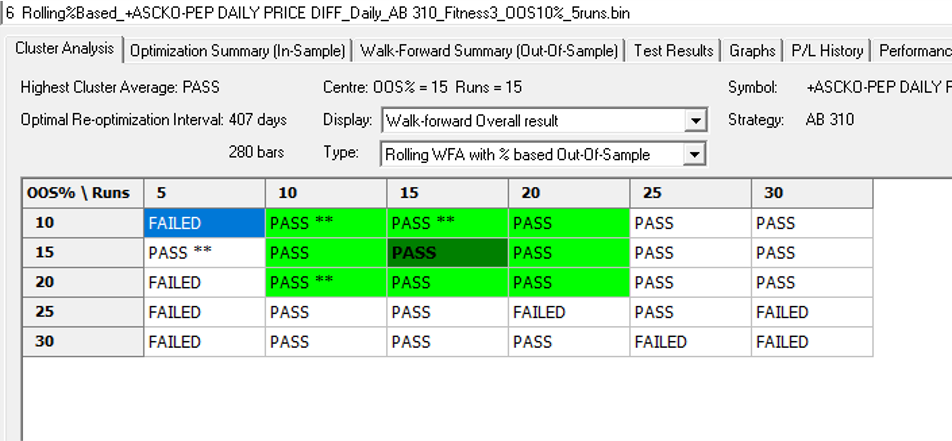
The results are no so unequivocal as for the strategy developed for the S&P 500 index, but would nonethless be regarded as acceptable, since the strategy passes the great majority of the tests (in addition to the tests on synthetic pairs data).
The final results appear as follows:
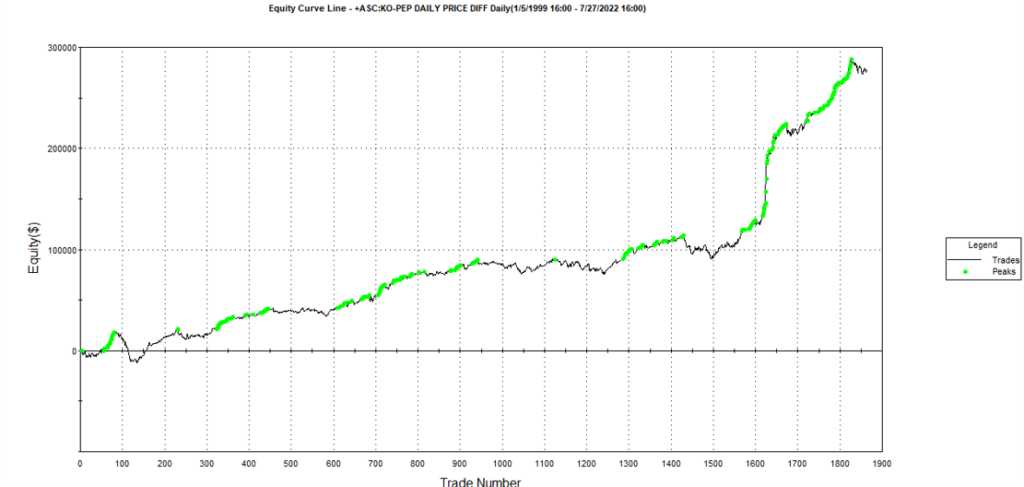
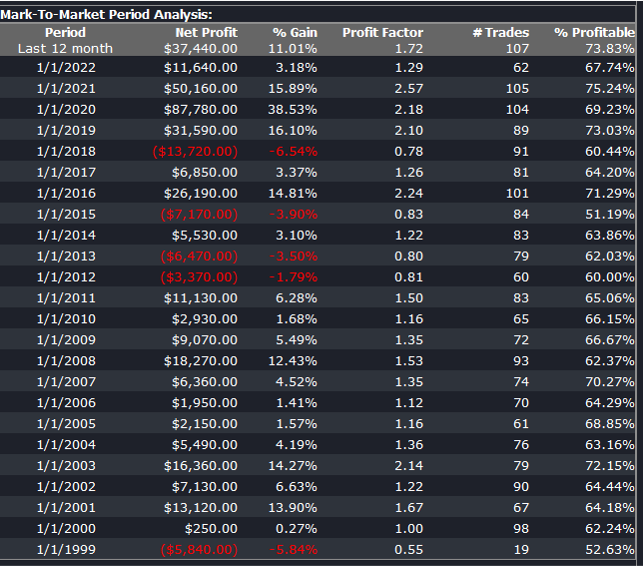
Conclusion
We have demonstrated how the algorithm can be used to generate synthetic price series the preserve not only the important time series properties, but also the cross-sectional properties between series for correlated securities. This important feature has applications in the development of statistical arbitrage strategies, portfolio construction methodology and in portfolio risk management.