An extract from the chapter on pairs trading from my forthcoming book Equity Analytics
Pairs-Trading-1Pairs Trading in the Equities Entity Store


QUANTITATIVE RESEARCH AND TRADING
The latest theories, models and investment strategies in quantitative research and trading
An extract from the chapter on pairs trading from my forthcoming book Equity Analytics
Pairs-Trading-1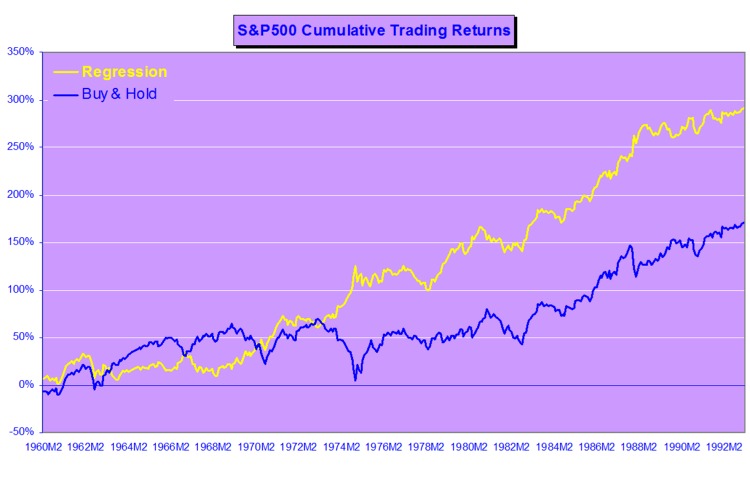
The presentation in this post covers a number of important topics in forecasting, including:
Also included are a number of detailed worked examples, including:
Forecasting 2011 - Time Series

One of the most highly desired properties of any financial model or investment strategy, by investors and managers alike, is robustness. I would define robustness as the ability of the strategy to deliver a consistent results across a wide range of market conditions. It, of course, by no means the only desirable property – investing in Treasury bills is also a pretty robust strategy, although the returns are unlikely to set an investor’s pulse racing – but it does ensure that the investor, or manager, is unlikely to be on the receiving end of an ugly surprise when market conditions adjust.
Robustness is not the same thing as low volatility, which also tends to be a characteristic highly prized by many investors. A strategy may operate consistently, with low volatility in certain market conditions, but behave very differently in other. For instance, a delta-hedged short-volatility book containing exotic derivative positions. The point is that empirical researchers do not know the true data-generating process for the markets they are modeling. When specifying an empirical model they need to make arbitrary assumptions. An example is the common assumption that assets returns follow a Gaussian distribution. In fact, the empirical distribution of the great majority of asset process exhibit the characteristic of “fat tails”, which can result from the interplay between multiple market states with random transitions. See this post for details:
http://jonathankinlay.com/2014/05/a-quantitative-analysis-of-stationarity-and-fat-tails/
In statistical arbitrage, for example, quantitative researchers often make use of cointegration models to build pairs trading strategies. However the testing procedures used in current practice are not sufficient powerful to distinguish between cointegrated processes and those whose evolution just happens to correlate temporarily, resulting in the frequent breakdown in cointegrating relationships. For instance, see this post:
http://jonathankinlay.com/2017/06/statistical-arbitrage-breaks/
We are, of course, not the first to suggest that empirical models are misspecified:
“All models are wrong, but some are useful” (Box 1976, Box and Draper 1987).
Martin Feldstein (1982: 829): “In practice all econometric specifications are necessarily false models.”
Luke Keele (2008: 1): “Statistical models are always simplifications, and even the most complicated model will be a pale imitation of reality.”
Peter Kennedy (2008: 71): “It is now generally acknowledged that econometric models are false and there is no hope, or pretense, that through them truth will be found.”
During the crash of 2008 quantitative Analysts and risk managers found out the hard way that the assumptions underpinning the copula models used to price and hedge credit derivative products were highly sensitive to market conditions. In other words, they were not robust. See this post for more on the application of copula theory in risk management:
http://jonathankinlay.com/2017/01/copulas-risk-management/
We interpret model misspecification as model uncertainty. Robustness tests analyze model uncertainty by comparing a baseline model to plausible alternative model specifications. Rather than trying to specify models correctly (an impossible task given causal complexity), researchers should test whether the results obtained by their baseline model, which is their best attempt of optimizing the specification of their empirical model, hold when they systematically replace the baseline model specification with plausible alternatives. This is the practice of robustness testing.

Robustness testing analyzes the uncertainty of models and tests whether estimated effects of interest are sensitive to changes in model specifications. The uncertainty about the baseline model’s estimated effect size shrinks if the robustness test model finds the same or similar point estimate with smaller standard errors, though with multiple robustness tests the uncertainty likely increases. The uncertainty about the baseline model’s estimated effect size increases of the robustness test model obtains different point estimates and/or gets larger standard errors. Either way, robustness tests can increase the validity of inferences.
Robustness testing replaces the scientific crowd by a systematic evaluation of model alternatives.
In the literature, robustness has been defined in different ways:
Robustness is the share of the probability density distribution of the baseline model that falls within the 95-percent confidence interval of the baseline model. In formulaeic terms:
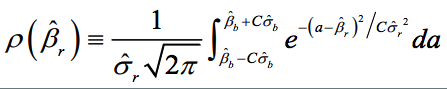
Model variation tests change one or sometimes more model specification assumptions and replace with an alternative assumption, such as:
The functional form test examines the baseline model’s functional form assumption against a higher-order polynomial model. The two models should be nested to allow identical functional forms. As an example, we analyze the ‘environmental Kuznets curve’ prediction, which suggests the existence of an inverse u-shaped relation between per capita income and emissions.
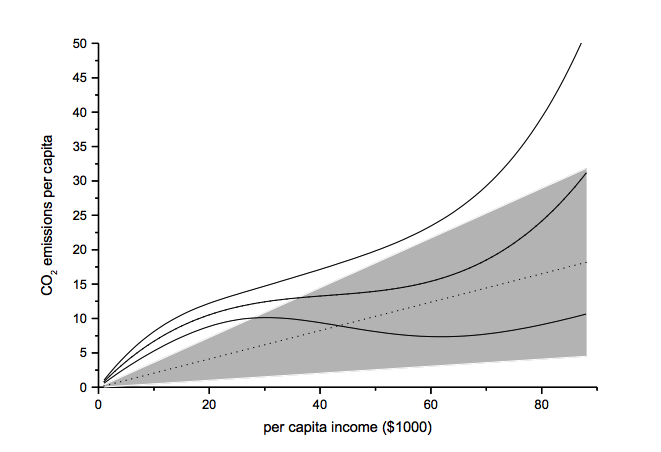
Note: grey-shaded area represents confidence interval of baseline model
Another example of functional form testing is given in this review of Yield Curve Models:
http://jonathankinlay.com/2018/08/modeling-the-yield-curve/
Random permutation tests change specification assumptions repeatedly. Usually, researchers specify a model space and randomly and repeatedly select model from this model space. Examples:
We use Monte Carlo simulation to test the sensitivity of the performance of our Quantitative Equity strategy to changes in the price generation process and also in model parameters:
http://jonathankinlay.com/2017/04/new-longshort-equity/
Structured permutation tests change a model assumption within a model space in a systematic way. Changes in the assumption are based on a rule, rather than random. Possibilities here include:
The jackknife robustness test is a structured permutation test that systematically excludes one or more observations from the estimation at a time until all observations have been excluded once. With a ‘group-wise jackknife’ robustness test, researchers systematically drop a set of cases that group together by satisfying a certain criterion – for example, countries within a certain per capita income range or all countries on a certain continent. In the example, we analyse the effect of earthquake propensity on quake mortality for countries with democratic governments, excluding one country at a time. We display the results using per capita income as information on the x-axes.
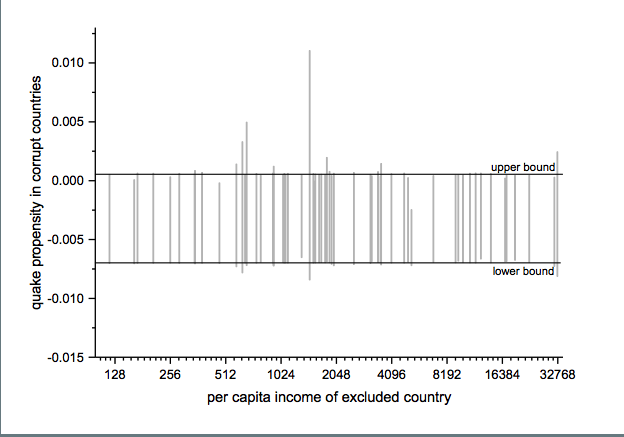
Upper and lower bound mark the confidence interval of the baseline model.
Robustness limit tests provide a way of analyzing structured permutation tests. These tests ask how much a model specification has to change to render the effect of interest non-robust. Some examples of robustness limit testing approaches:
For an example of limit testing, see this post on a review of the Lognormal Mixture Model:
http://jonathankinlay.com/2018/08/the-lognormal-mixture-variance-model/
Robustness tests have become an integral part of research methodology. Robustness tests allow to study the influence of arbitrary specification assumptions on estimates. They can identify uncertainties that otherwise slip the attention of empirical researchers. Robustness tests offer the currently most promising answer to model uncertainty.
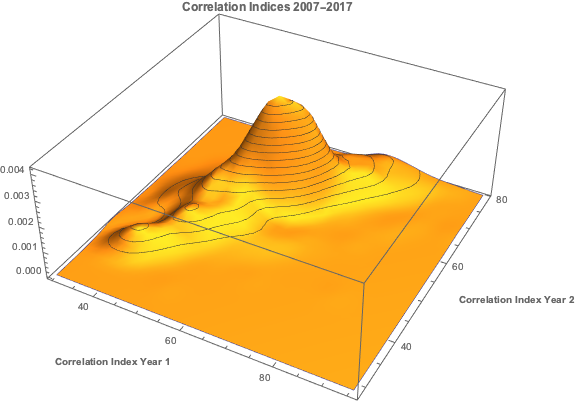
In a previous post I looked at ways of modeling the relationship between the CBOE VIX Index and the Year 1 and Year 2 CBOE Correlation Indices:
http://jonathankinlay.com/2017/08/modeling-volatility-correlation/
The question was put to me whether the VIX and correlation indices might be cointegrated.
Let’s begin by looking at the pattern of correlation between the three indices:
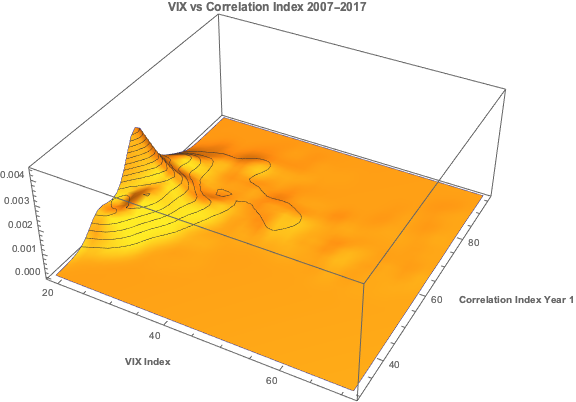
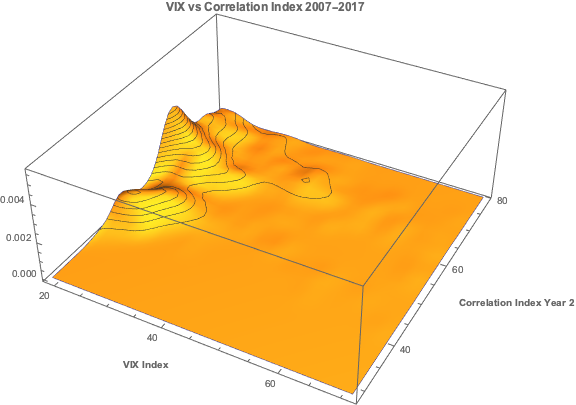
If you recall from my previous post, we were able to fit a linear regression model with the Year 1 and Year 2 Correlation Indices that accounts for around 50% in the variation in the VIX index. While the model certainly has its shortcomings, as explained in the post, it will serve the purpose of demonstrating that the three series are cointegrated. The standard Dickey-Fuller test rejects the null hypothesis of a unit root in the residuals of the linear model, confirming that the three series are cointegrated, order 1.

We can attempt to take the modeling a little further by fitting a VAR model. We begin by splitting the data into an in-sample period from Jan 2007 to Dec 2015 and an out-of-sample test period from Jan 2016 to Aug 2017. We then fit a vector autoregression model to the in-sample data:
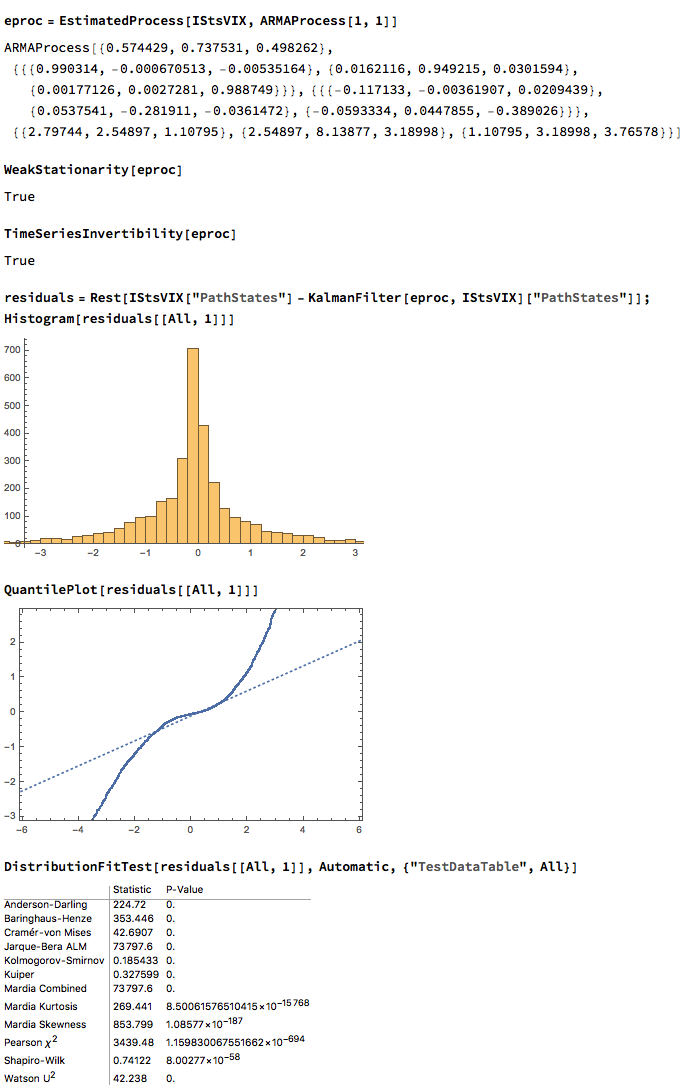
When we examine how the model performs on the out-of-sample data, we find that it fails to pick up on much of the variation in the series – the forecasts are fairly flat and provide quite poor predictions of the trends in the three series over the period from 2016-2017:
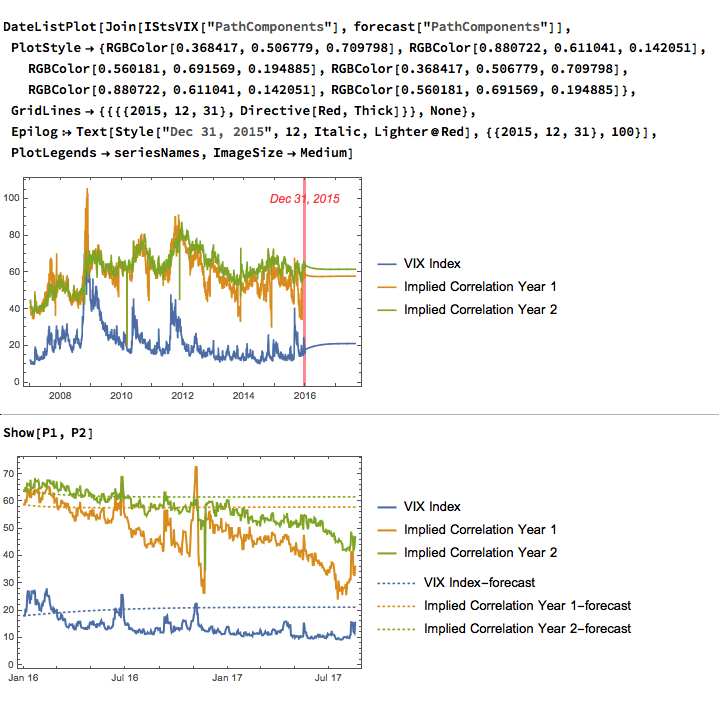
The VIX and Correlation Indices are not only highly correlated, but also cointegrated, in the sense that a linear combination of the series is stationary.
One can fit a weakly stationary VAR process model to the three series, but the fit is quite poor and forecasts from the model don’t appear to add much value. It is conceivable that a more comprehensive model involving longer lags would improve forecasting performance.