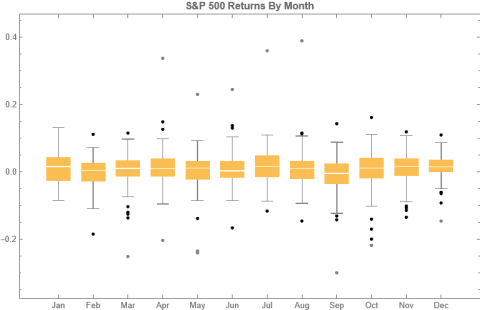
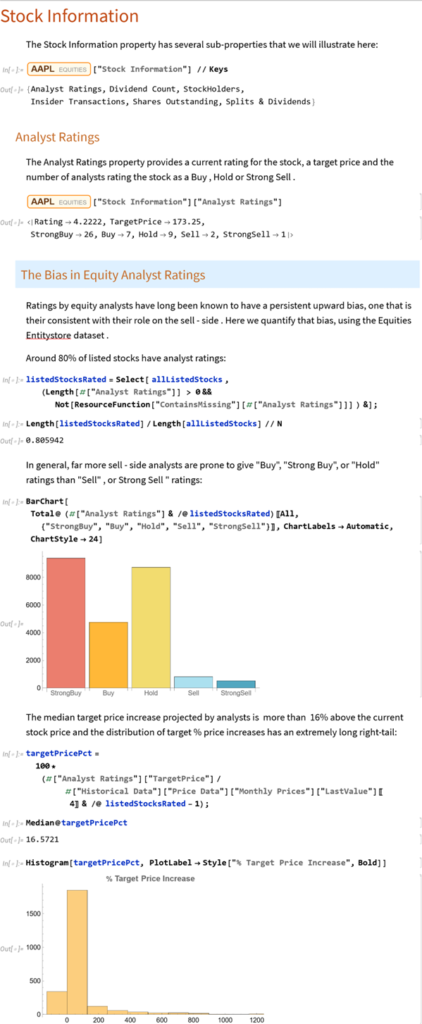
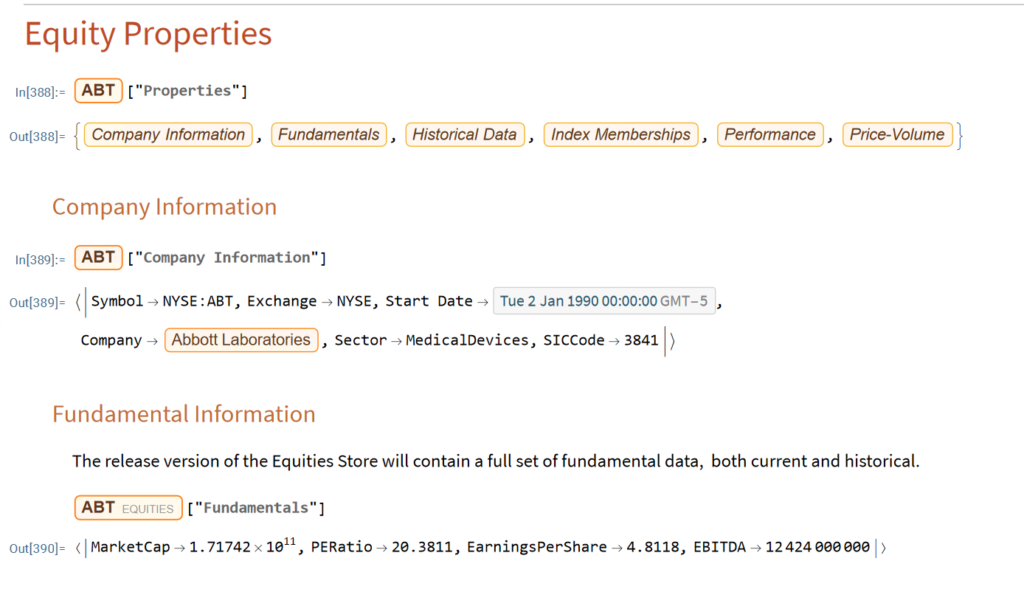
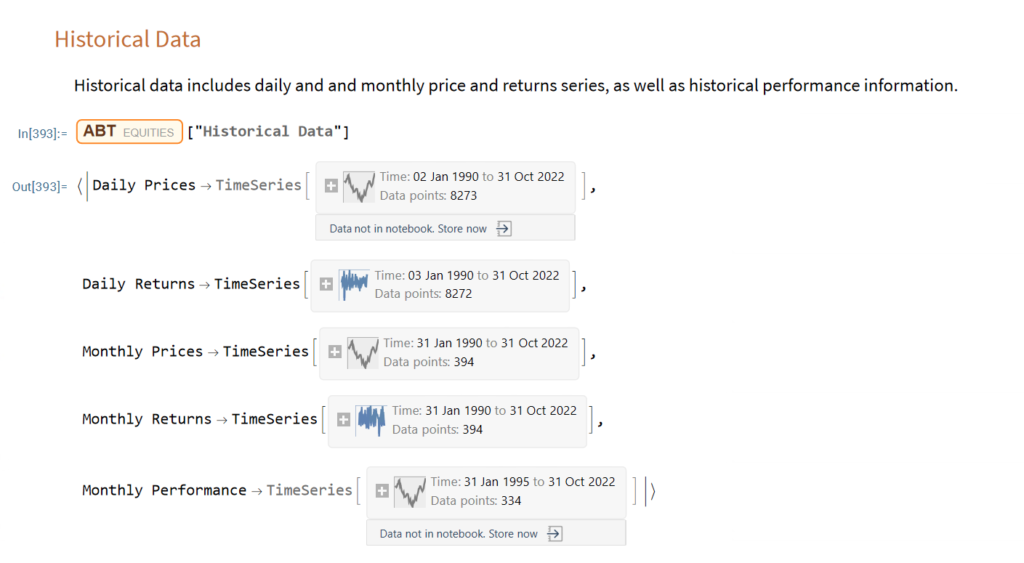
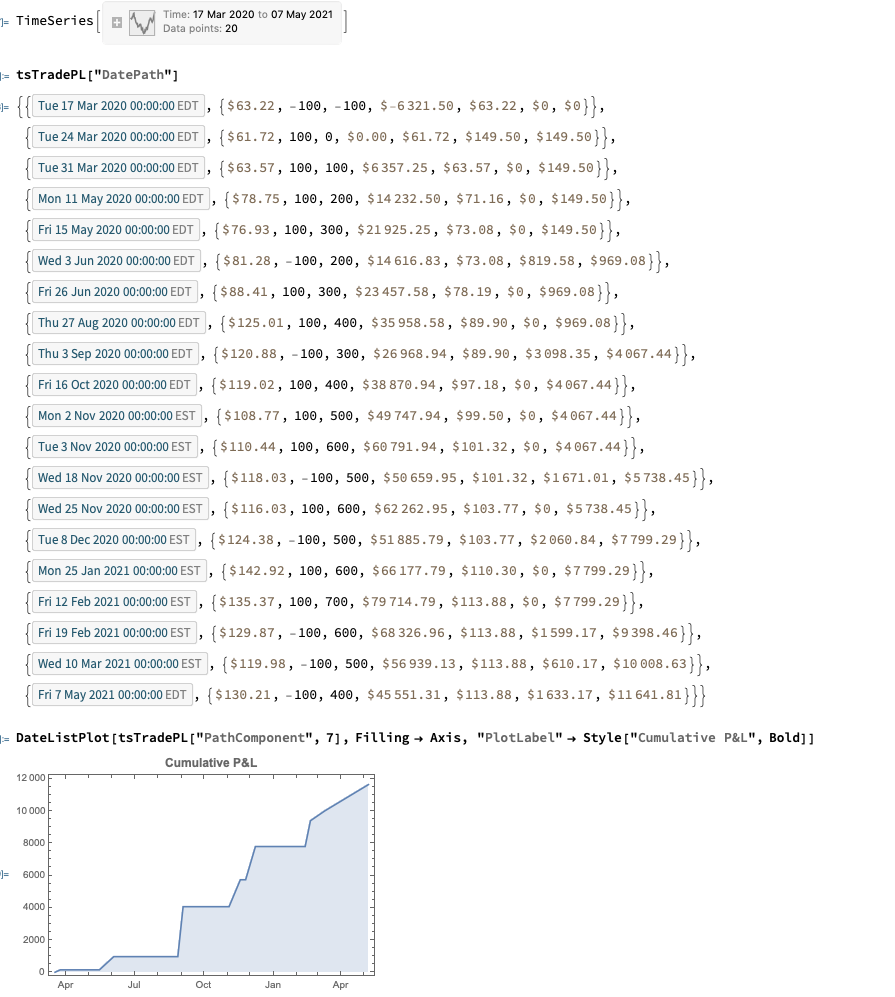
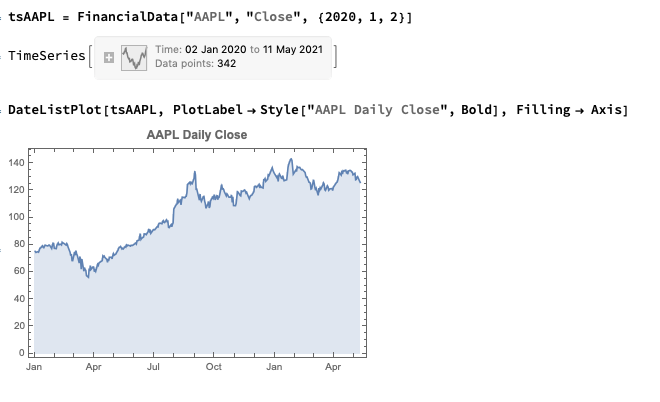
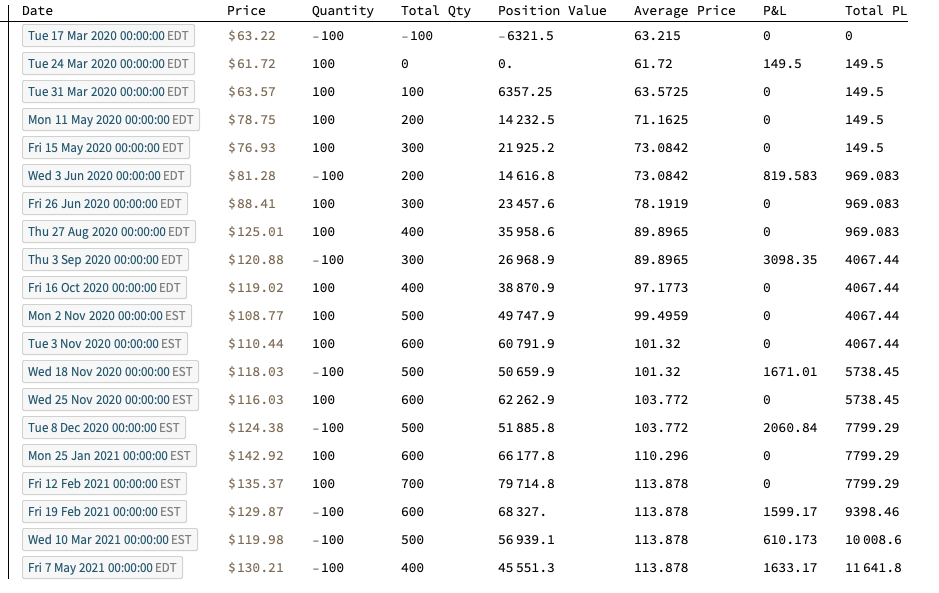
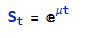Python vs. Wolfram Language
As an avid user of both Python and Wolfram Language for technical computing, I’m often asked how they compare. Python’s strengths as an open-source language are clear:
- Ubiquity – With millions of users, Python has become ubiquitous across fields like data science, ML engineering, web development, and scientific research. This massive adoption fuels continuous enhancement of its tools.
- Comprehensive capabilities – Python’s expansive ecosystem of 200,000+ libraries spans everything from numerical computing to web frameworks to industrial automation. It is a versatile, widely-supported language for building end-to-end applications.
- Approachability – Python’s straightforward syntax, multitude of online resources, and abundance of machine learning libraries like TensorFlow and PyTorch make it highly accessible for new programmers and non-CS domain experts alike.
- Interoperability – Python integrates smoothly with everything from SQL and NoSQL databases to enterprise IT environments and microcontrollers like Raspberry Pi. This flexibility enables diverse production deployments.
In summary, Python offers benefits in ubiquity, breadth, approachability, and seamless interoperability with external systems. Together, they show the value of domain-specific and general-purpose languages for tackling modern analytics and engineering challenges.
However, while Python is a versatile, open-source language popular among developers, the Wolfram Language offers some unique advantages:
Powerful Symbolic Capabilities
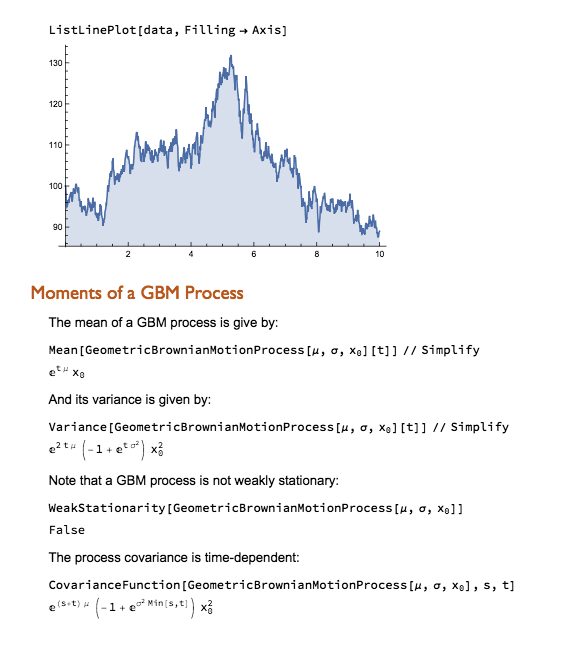
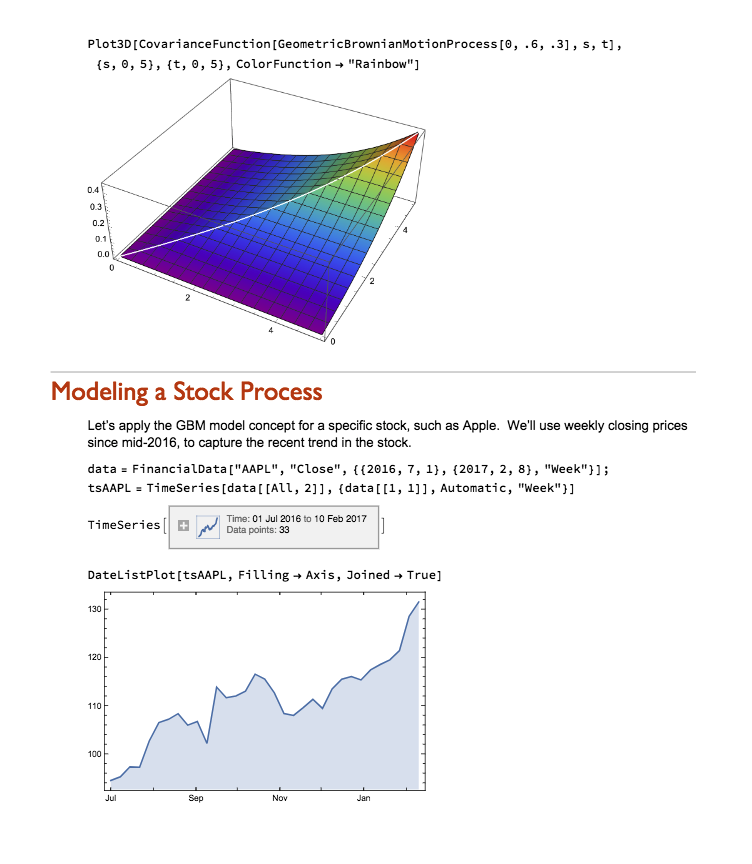
One of the most powerful aspects of the Wolfram Language is its unparalleled symbolic manipulation abilities for mathematical computation. Operations like symbolic integration, solving equations analytically, theorem proving, model simplification and more are built deeply into the language in a way no other programming language matches. Python can conduct numeric computation and data analysis well, but does not have this domain of symbolic capabilities natively.
For any usage involving abstract mathematical development, derivation of analytical results, or formal proofs, the symbolic nature of the Wolfram Language is a major differentiator.
Wolfram Notebooks
offer notable advantages over Jupyter notebooks in Python:
- More visual appeal – The Wolfram notebooks produce beautifully typeset output and publication-ready visualizations by default, whereas Jupyter’s output is more basic.
- Greater configurability – Wolfram’s notebooks allow extensive styling, templating, and customization of content for different applications. Jupyter also enables some configuration, but not to the same degree.
- Tighter integration – The Wolfram notebooks leverage the language’s underlying functions and capabilities more fluidly since it’s one integrated environment. Jupyter interfaces well with Python but there is still some separation.
- Interactivity – Wolfram notebooks support advanced interactivity through Manipulate/Animate and instant visual output.
Overall, while Jupyter notebooks are hugely popular among Python developers and enable great functionality, Wolfram’s notebook solution stands out as more robust, customizable, and visually polished. The tight integration with the Wolfram Language and computational capabilities augments interactive analysis in a way Jupyter can’t match.
Integrated Knowledge and Data
The Wolfram Language stands out in providing an “integrated knowledge base” that spans from sophisticated algorithms to real-world data across domains. This includes vast curated datasets on topics from architecture to chemistry to finance that can readily feed models and analyses without additional wrangling.
Additionally, the entity store concept allows users to author their own object-based, customizable data repositories. Python’s classes are focused on methods rather than data and while Python offers strong libraries for storing and accessing data, Wolfram facilitates more zero-friction application of real-world knowledge and entity-oriented data storage out-of-the-box. For minimizing time manipulating data or searching for reference algorithms before modeling, Wolfram Language excels.
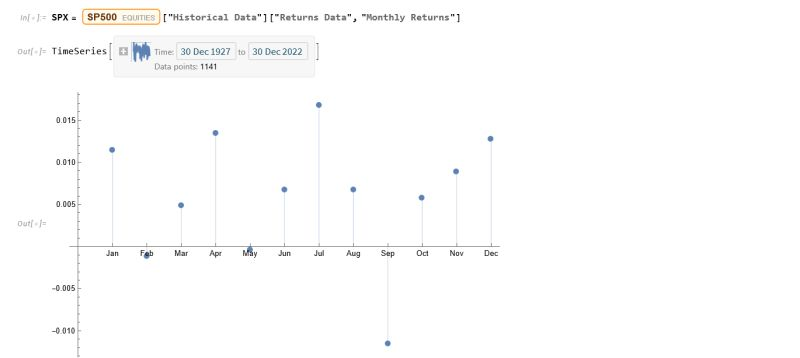
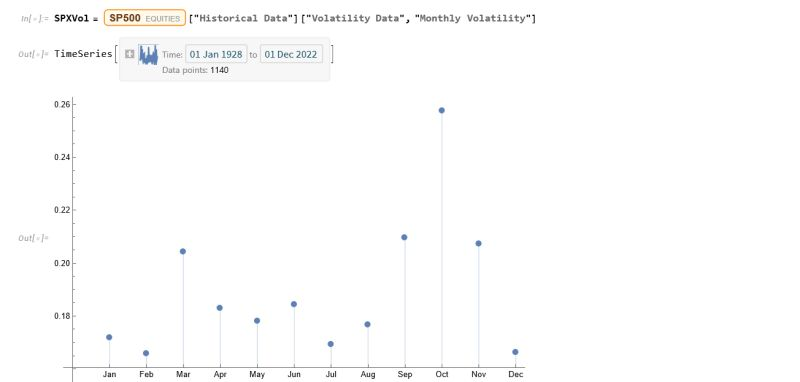
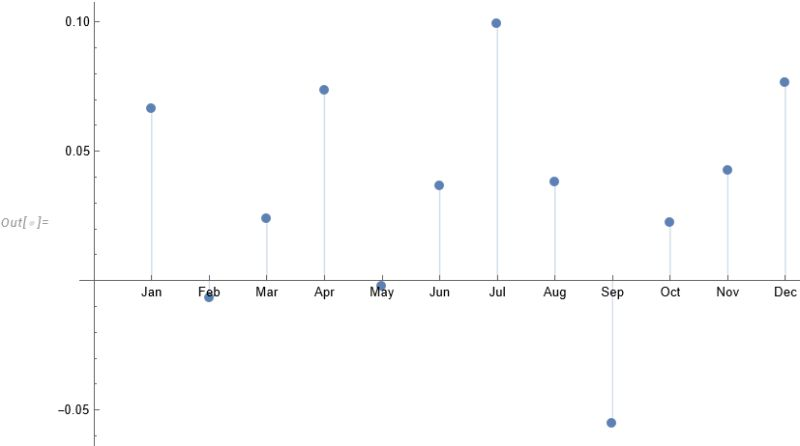
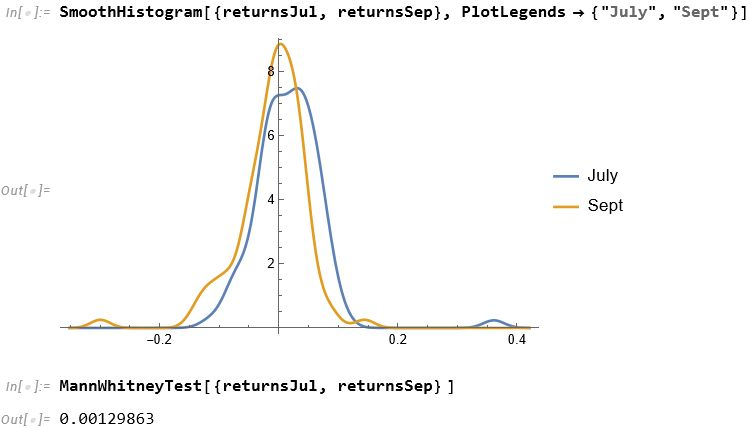
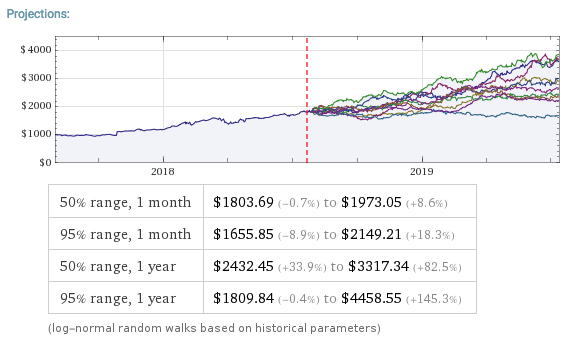
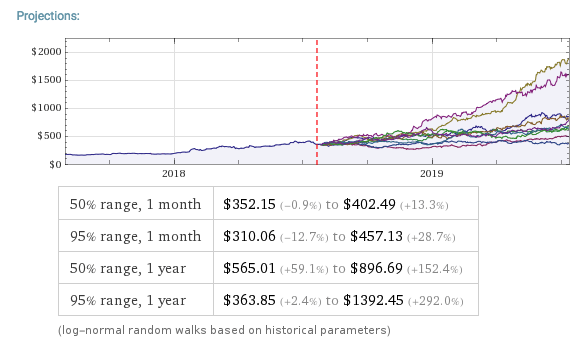
The entity store in particular enables a very natural object/entity-based programming style that can integrate smoothly with Wolfram’s class system and its underlying symbolic capabilities. This unique data representation system differentiation is a key strength (for example, see the Equities Entity Store).
Interactivity and Prototyping
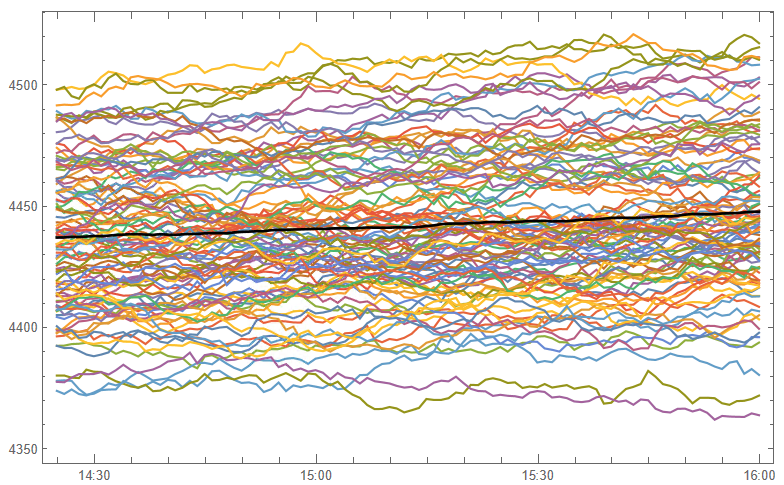
The Wolfram Language excels in hands-on analysis and rapid iteration thanks to its line-by-line execution and built-in Manipulate/Animate functions for customizable graphics, animations and interactive simulations. Python does allow some interactivity in Jupyter notebooks, but does not match Wolfram’s capabilities for creating interactive visualizations on-the-fly. This makes Wolfram Language uniquely well-suited for highly iterative, prototyping tasks that involve visual output. If ease of exploration and fluid development is a priority, the Wolfram Language has clear strengths.
Seamless Parallelization
The Wolfram Language has seamless built-in parallelization capabilities that allow code to efficiently utilize multi-core systems without the developer needing to directly manage threads or processes. Python can achieve parallelism through libraries, but the developer bears responsibility for managing dependencies and avoiding conflicts. Similarly, the Wolfram Language directly interfaces with Nvidia GPUs out-of-the-box for high performance numerical code with minimal extra effort. Thus, for users focused on computational speedup, Wolfram simplifies parallelization and GPU integration in very useful ways.
Python libraries like TensorFlow and PyTorch do hide GPU complexities well for deep learning. But in general, achieving parallel execution in Python places a greater burden on the developer. Wolfram’s approach dramatically lowers the barriers to leveraging multiple cores and GPU power for everyday computations.
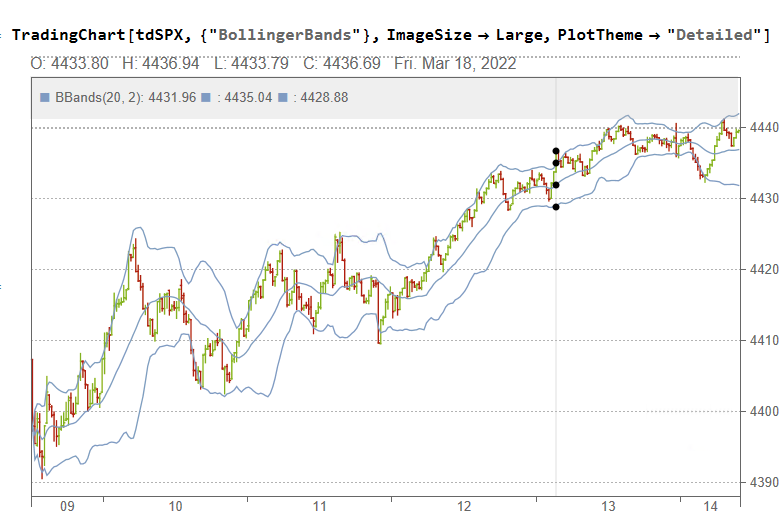
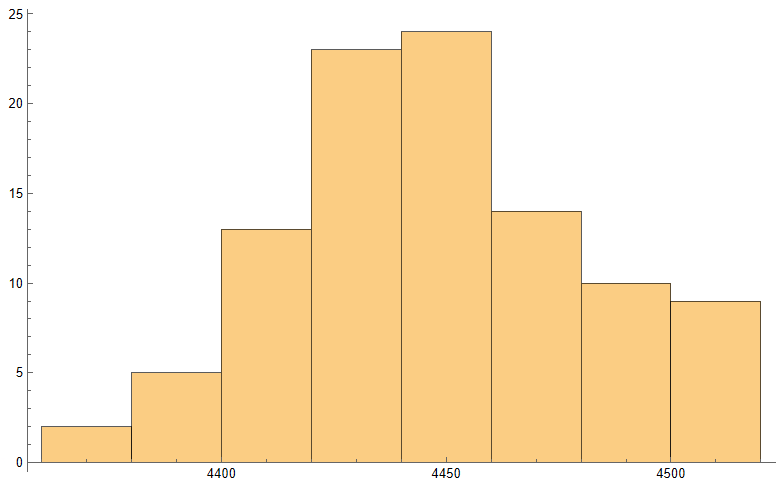
Sophisticated Visualization
Creating publication-quality, customized visualizations requires just lines of code in the Wolfram Language, thanks to the built-in graphics capabilities. While Python offers powerful visualization through add-on libraries like Matplotlib, Seaborn, Bokeh, and Plotly, Wolfram’s out-of-the-box solutions may provide greater ease of use. However, from low-level control to interactive web plots, Python’s visualization options are quite extensive despite requiring more setup. Ultimately, for rapid high-level plotting, Wolfram Language has advantageous default capabilities. But Python gives more flexibility and customization options through its ecosystem of graphic libraries.
In summary, while Python offers flexibility and a large user base – advantages in its own right – the Wolfram Language dramatically reduces lines of code and development time. By curating real-world data, algorithms, and visualization in one coherent language and platform, it streamlines and accelerates quantitative work for scientists, analysts, economists and more.
If you do significant data analysis or modeling, I encourage you to try the Wolfram Language and see the difference yourself. It’s been a gamechanger for my productivity.