
I am planning a series of posts on the subject of asset volatility and option pricing and thought I would begin with a survey of some of the central ideas. The attached presentation on Modeling Asset Volatility sets out the foundation for a number of key concepts and the basis for the research to follow.
Perhaps the most important feature of volatility is that it is stochastic rather than constant, as envisioned in the Black Scholes framework. The presentation addresses this issue by identifying some of the chief stylized facts about volatility processes and how they can be modelled. Certain characteristics of volatility are well known to most analysts, such as, for instance, its tendency to “cluster” in periods of higher and lower volatility. However, there are many other typical features that are less often rehearsed and these too are examined in the presentation.
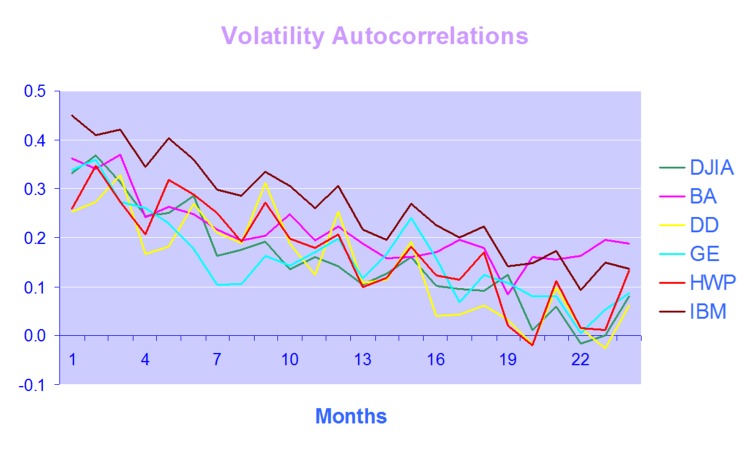
Long Memory
For example, while it is true that GARCH models do a fine job of modeling the clustering effect they typically fail to capture one of the most important features of volatility processes – long term serial autocorrelation. In the typical GARCH model autocorrelations die away approximately exponentially, and historical events are seen to have little influence on the behaviour of the process very far into the future. In volatility processes that is typically not the case, however: autocorrelations die away very slowly and historical events may continue to affect the process many weeks, months or even years ahead.

There are two immediate and very important consequences of this feature. The first is that volatility processes will tend to trend over long periods – a characteristic of Black Noise or Fractionally Integrated processes, compared to the White Noise behavior that typically characterizes asset return processes. Secondly, and again in contrast with asset return processes, volatility processes are inherently predictable, being conditioned to a significant degree on past behavior. The presentation considers the fractional integration frameworks as a basis for modeling and forecasting volatility.
Mean Reversion vs. Momentum
A puzzling feature of much of the literature on volatility is that it tends to stress the mean-reverting behavior of volatility processes. This appears to contradict the finding that volatility behaves as a reinforcing process, whose long-term serial autocorrelations create a tendency to trend. This leads to one of the most important findings about asset processes in general, and volatility process in particular: i.e. that the assets processes are simultaneously trending and mean-reverting. One way to understand this is to think of volatility, not as a single process, but as the superposition of two processes: a long term process in the mean, which tends to reinforce and trend, around which there operates a second, transient process that has a tendency to produce short term spikes in volatility that decay very quickly. In other words, a transient, mean reverting processes inter-linked with a momentum process in the mean. The presentation discusses two-factor modeling concepts along these lines, and about which I will have more to say later.

Cointegration
One of the most striking developments in econometrics over the last thirty years, cointegration is now a principal weapon of choice routinely used by quantitative analysts to address research issues ranging from statistical arbitrage to portfolio construction and asset allocation. Back in the late 1990’s I and a handful of other researchers realized that volatility processes exhibited very powerful cointegration tendencies that could be harnessed to create long-short volatility strategies, mirroring the approach much beloved by equity hedge fund managers. In fact, this modeling technique provided the basis for the Caissa Capital volatility fund, which I founded in 2002. The presentation examines characteristics of multivariate volatility processes and some of the ideas that have been proposed to model them, such as FIGARCH (fractionally-integrated GARCH).
Dispersion Dynamics
Finally, one topic that is not considered in the presentation, but on which I have spent much research effort in recent years, is the behavior of cross-sectional volatility processes, which I like to term dispersion. It turns out that, like its univariate cousin, dispersion displays certain characteristics that in principle make it highly forecastable. Given an appropriate model of dispersion dynamics, the question then becomes how to monetize efficiently the insight that such a model offers. Again, I will have much more to say on this subject, in future.