The latest theories, models and investment strategies in quantitative research and trading
Author: Jonathan
Dr Jonathan Kinlay is the Head of Quantitative Trading at Systematic Strategies, LLC, a systematic hedge fund that deploys high frequency, systematic trading strategies.
Dr Kinlay, was the founder and General Partner of the Caissa Capital hedge fund, whose volatility arbitrage strategies were developed by Dr Kinlay’s investment research firm, Investment Analytics.
Dr Kinlay was formerly Global Head of Model Review at the US investment bank Bear Stearns.
Dr Kinlay holds a PhD in economics and has held positions on the faculty at New York University Stern School of Business, Carnegie Mellon and Reading Universities.
In my recent piece on Kronos, I explored how foundation models trained on K-line data are reshaping time series forecasting in finance. That discussion naturally raises a follow-up question that several readers have asked: what about the architecture itself? The Transformer has dominated deep learning for sequence modeling over the past seven years, but a new class of models — State-Space Models (SSMs), particularly the Mamba architecture — is gaining serious attention. In high-frequency trading, where computational efficiency and latency are everything, the claimed O(n) versus O(n²) complexity advantage is more than academic. It’s a potential competitive edge.
Let me be clear from the outset: I’m skeptical of any claim that a new architecture will “replace” Transformers wholesale. The Transformer ecosystem is mature, well-understood, and backed by enormous engineering investment. But in the specific context of market microstructure — where we process millions of tick events, model limit order book dynamics, and make decisions in microseconds — SSMs deserve serious examination. The question isn’t whether they can replace Transformers entirely, but whether they should be part of our toolkit for certain problems.
I’ve spent the better part of two decades building trading systems that push against latency constraints. I’ve watched the industry evolve from simple linear models to gradient boosted trees to deep learning, each wave promising revolutionary improvements. Most delivered incremental gains; some fizzled entirely. What’s interesting about SSMs isn’t the theoretical promise — we’ve seen theoretical promises before — but rather the practical characteristics that might actually matter in a production trading environment. The linear scaling, the constant-time inference, the selective attention mechanism — these aren’t just academic curiosities. They’re the exact properties that could determine whether a model makes it into a production system or dies in a research notebook.
What Are State-Space Models?
To understand why SSMs have suddenly become interesting, we need to go back to the mathematical foundations — and they’re older than you might think. State-space models originated in control theory and signal processing, describing systems where an internal state evolves over time according to differential equations, with observations emitted from that state. If you’ve used a Kalman filter — and in quant finance, many of us have — you’ve already worked with a simple state-space model, even if you didn’t call it that.
The canonical continuous-time formulation is:
\[x'(t) = Ax(t) + Bu(t)\]
\[y(t) = Cx(t) + Du(t)\]
where \(x(t)\) is the latent state vector, \(u(t)\) is the input, \(y(t)\) is the output, and \(A\), \(B\), \(C\), \(D\) are learned matrices. This looks remarkably like a Kalman filter — because it is, in essence, a nonlinear generalization of linear state estimation. The key difference from traditional time series models is that we’re learning the dynamics directly from data rather than specifying them parametrically. Instead of assuming variance follows a GARCH(1,1) process, we let the model discover what the underlying state evolution looks like.
The challenge, historically, was that computing these models was intractable for long sequences. The recurrent view requires iterating through each timestep sequentially; the convolutional view requires computing full convolutions that scale poorly. This is where the S4 model (Structured State Space Sequence) changed the game.
S4, introduced by Gu, Dao et al. (2022), brought three critical innovations. First, it used the HiPPO (High-order Polynomial Projection Operator) framework to initialize the state matrix \(A\) in a way that preserves long-range dependencies. Without proper initialization, SSMs suffer from the same vanishing gradient problems as RNNs. The HiPPO matrix is specifically designed so that when the model views a sequence, it can accurately represent all historical information without exponential decay. In financial terms, this means last month’s market dynamics can influence today’s predictions — something vanilla RNNs struggle with.
Author’s Take: This is the key innovation that makes SSMs viable for finance. Without HiPPO, you’d face the same vanishing-gradient failure mode that killed RNN research for decades. The HiPPO initialization is essentially a “warm start” that encodes the mathematical insight that recent history matters more than distant history — but distant history still matters. This is perfectly aligned with how financial markets work: last quarter’s regime still influences pricing, even if less than yesterday’s moves.
HiPPO provides a theoretically grounded initialization that allows the model to remember information from thousands of timesteps ago — critical for financial time series where last week’s patterns may be relevant to today’s dynamics. The mathematical insight is that HiPPO projects the input onto a basis of orthogonal polynomials, maintaining a compressed representation of the full history. This is conceptually similar to how we’d use PCA for dimensionality reduction, except it’s learned end-to-end as part of the model’s dynamics.
Second, S4 introduced structured parameterizations that enable efficient computation via diagonalization. Rather than storing full \(N \times N\) matrices where \(N\) is the state dimension, S4 uses structured forms that reduce memory and compute requirements while maintaining expressiveness. The key insight is that the state transition matrix \(A\) can be parameterized as a diagonal-plus-low-rank form that enables fast computation via FFT-based convolution. This is what gives S4 its computational advantage over traditional SSMs — the structured form turns the convolution from \(O(L^2)\) to \(O(L \log L)\).
Third, S4 discretizes the continuous-time model into a discrete-time representation suitable for implementation. The standard approach is zero-order hold (ZOH), which treats the input as constant between timesteps:
\[x_{k} = \bar{A}x_{k-1} + \bar{B}u_k\]
\[y_k = \bar{C}x_k + \bar{D}u_k\]
where \(\bar{A} = e^{A\Delta t}\), \(\bar{B} = (e^{A\Delta t} – I)A^{-1}B\), and similarly for \(\bar{C}\) and \(\bar{D}\). The bilinear transform is an alternative that can offer better frequency response in some settings:
Author’s Take: In practice, I’ve found ZOH (zero-order hold) works well for most tick-level data — it’s robust to the high-frequency microstructure noise that dominates at sub-second horizons. Bilinear can help if you’re modeling at longer horizons (minutes to hours) where you care more about capturing trend dynamics than filtering out tick-by-tick noise. This is another example of where domain knowledge beats blind architecture choices.
\[\bar{A} = (I + A\Delta t/2)(I – A\Delta t/2)^{-1}\]
Either way, the discretization bridges continuous-time system theory with discrete-time sequence modeling. The choice of discretization matters for financial applications because different discretization schemes have different frequency characteristics — bilinear transform tends to preserve low-frequency behavior better, which may be important for capturing long-term trends.
Mamba, introduced by Gu and Dao (2023) and winning best paper at ICLR 2024, added a fourth critical innovation: selective state spaces. The core insight is that not all input information is equally relevant at all times. In a financial context, during calm markets, we might want to ignore most order flow noise and focus on price levels; during a news event or volatility spike, we want to attend to everything. Mamba introduces a selection mechanism that allows the model to dynamically weigh which inputs matter:
\[s_t = \text{select}(u_t)\]
\[\bar{B}_t = \text{Linear}_B(s_t)\]
\[\bar{C}_t = \text{Linear}_C(s_t)\]
The select operation is implemented as a learned projection that determines which elements of the input to filter. This is fundamentally different from attention — rather than computing pairwise similarities between all tokens, the model learns a function that decides what information to carry forward. In practice, this means Mamba can learn to “ignore” regime-irrelevant data while attending to regime-critical signals.
This selectivity, combined with an efficient parallel scan algorithm (often called S6), gives Mamba its claimed linear-time inference while maintaining the ability to capture complex dependencies. The complexity comparison is stark: Transformers require \(O(L^2)\) attention computations for sequence length \(L\), while Mamba processes each token in \(O(1)\) time with \(O(L)\) total computation. For \(L = 10,000\) ticks — a not-unreasonable window for intraday analysis — that’s \(10^8\) versus \(10^4\) operations per layer. The practical implication is either dramatically faster inference or the ability to process much longer sequences for the same compute budget. On modern GPUs, this translates to milliseconds versus tens of milliseconds for a forward pass — a difference that matters when you’re making hundreds of predictions per second.
Compared to RNNs like LSTMs, SSMs don’t suffer from the same sequential computation bottleneck during training. While LSTMs must process tokens one at a time (true parallelization is limited), SSMs can be computed as convolutions during training, enabling GPU parallelism. During inference, SSMs achieve the constant-time-per-token property that makes them attractive for production deployment. This is the key advantage over LSTMs — you get the sequential processing benefits of RNNs during inference with the parallel training benefits of CNNs.
Why HFT and Market Microstructure?
If you’re building trading systems, you’ve likely noticed that most machine learning approaches to finance treat the problem as either (a) predicting returns at some horizon, or (b) classifying market regimes. Neither approach explicitly models the underlying mechanism that generates prices. Market microstructure does exactly that — it models how orders arrive, how limit order books evolve, how informed traders interact with liquidity providers, and how information gets incorporated into prices. Understanding microstructure isn’t just academic — it’s the foundation of profitable execution and market-making strategies.
The data characteristics of market microstructure create unique challenges that make SSMs potentially attractive:
Scale: A single liquid equity can generate millions of messages per day across bid, ask, and depth levels. Consider a highly traded stock like Tesla or Nvidia during volatile periods — you might see 50-100 messages per second, per instrument. A typical algo trading firm’s data pipeline might ingest 50-100GB of raw tick data daily across their coverage universe. Processing this with Transformer models is expensive. The quadratic attention complexity means that doubling your context length quadruples your compute cost. With SSMs, you double context and roughly double compute — a much friendlier scaling curve. This is particularly important when you’re building models that need to see significant historical context to make predictions.
Non-stationarity: Market microstructure is inherently non-stationary. The dynamics of a limit order book during normal trading differ fundamentally from those during a market open, a regulatory halt, or a volatility auction. At market open, you have a flood of overnight orders, wide spreads, and rapid price discovery. During a halt, trading stops entirely and the book freezes. In volatility auctions, you see large price movements with reduced liquidity. Mamba’s selective mechanism is specifically designed to handle this — the model can learn to “switch off” irrelevant inputs when market conditions change. This is conceptually similar to regime-switching models in econometrics, but learned end-to-end. The model learns when to attend to order flow dynamics and when to ignore them based on learned signals.
Latency constraints: In market-making or latency-sensitive strategies, every microsecond counts. A Transformer processing a 512-token sequence might require 262,144 attention operations. Mamba processes the same sequence in roughly 512 state updates — a 500x reduction in per-token operations. While the constants differ (SSM state dimension adds overhead), the theoretical advantage is substantial. Several practitioners I’ve spoken with report sub-10ms inference times for Mamba models that would be impractical with Transformers at the same context length. For comparison, a typical market-making strategy might have a 100-microsecond latency budget for the entire decision pipeline — inference must be measured in microseconds, not milliseconds.
Long-range dependencies: Consider a statistical arbitrage strategy across 100 stocks. A regulatory announcement at 9:30 AM might affect correlations across the entire universe until midday. Capturing this requires modeling dependencies across thousands of timesteps. The HiPPO initialization in S4 and the selective mechanism in Mamba are specifically designed to maintain information flow over such horizons — something vanilla RNNs struggle with due to gradient decay. In practice, this means you can build models that truly “remember” what happened earlier in the trading session, not just what happened in the last few minutes.
There’s also a subtler point worth mentioning: the order book itself is a form of state. When you look at the bid-ask ladder, you’re seeing a snapshot of accumulated order flow — the current state reflects all historical interactions. SSMs are naturally suited to modeling stateful systems because that’s literally what they are. The latent state \(x(t)\) in the state equation can be interpreted as an embedding of the current market state, learned from data rather than specified by theory. This is philosophically aligned with how we think about market microstructure: the order book is a state variable, and the messages are observations that update that state.
Recent Research and Results
The application of SSMs to financial markets is a rapidly evolving research area. Let me survey what’s been published, with appropriate skepticism about early-stage results. The key papers worth noting span both the SSM methodology and the finance-specific applications.
On the methodology side, S4 (Gu, Johnson et al., 2022) established the foundation by demonstrating that structured state spaces could match or exceed Transformers on long-range arena benchmarks while maintaining linear computation. The Mamba paper (Gu and Dao, 2023) pushed further by introducing selective state spaces and achieving state-of-the-art results on language modeling benchmarks — remarkable because it suggested SSMs could compete with Transformers on tasks previously dominated by attention. The follow-up work on Mamba 2 (Dao and Gu, 2024) introduced structured state space duals, further improving efficiency.
On the application side, CryptoMamba (Shi et al., 2025) applied Mamba to Bitcoin price prediction, demonstrating “effective capture of long-range dependencies” in cryptocurrency time series. The authors report competitive performance against LSTM and Transformer baselines on several prediction horizons. The cryptocurrency market, with its 24/7 trading and higher noise-to-signal ratio than traditional equities, provides an interesting test case for SSMs’ ability to handle extreme non-stationarity. The paper’s methodology section shows that Mamba’s selective mechanism successfully learned to filter out noise during calm periods while attending to significant price movements — exactly what we’d hope to see.
MambaStock (Liu et al., 2024) adapted the Mamba architecture specifically for stock prediction, introducing modifications to handle the multi-dimensional nature of financial features (price, volume, technical indicators). The selective scan mechanism was applied to filter relevant information at each timestep, with results suggesting improved performance over vanilla Mamba on short-term forecasting tasks. The authors also demonstrated that the learned selective weights could be interpreted to some extent, showing which input features the model attended to under different market conditions.
Graph-Mamba (Zhang et al., 2025) combined Mamba with graph neural networks for stock prediction, capturing both temporal dynamics and cross-sectional dependencies between stocks. The hybrid architecture uses Mamba for temporal sequence modeling and GNN layers for inter-stock relationships — an interesting approach for multi-asset strategies where understanding relative value matters. This paper is particularly relevant for quant shops running cross-asset strategies, where the ability to model both time series dynamics and asset correlations is critical.
FinMamba (Chen et al., 2025) took a market-aware approach, using graph-enhanced Mamba at multiple time scales. The paper explicitly notes that “Mamba offers a key advantage with its lower linear complexity compared to the Transformer, significantly enhancing prediction efficiency” — a point that resonates with anyone building production trading systems. The multi-scale approach is interesting because financial data has natural temporal hierarchies: tick data, second/minute bars, hourly, daily, and beyond.
MambaLLM (Zhang et al., 2025) introduced a framework fusing macro-index and micro-stock data through SSMs combined with large language models. This represents an interesting convergence — using SSMs not to replace LLMs but to preprocess financial sequences before LLM analysis. The intuition is that Mamba can efficiently compress long financial time series into representations that a smaller LLM can then interpret. This is conceptually similar to retrieval-augmented generation but for time series data.
Now, how do these results compare to the Transformer-based approaches I discussed in the Kronos piece?
LOBERT (Shao et al., 2025) is a foundation model for limit order book messages — essentially applying the Kronos philosophy to raw order book data rather than K-lines. Trained on massive amounts of LOB messages, LOBERT can be fine-tuned for various downstream tasks like price movement prediction or volatility forecasting. It’s an encoder-only architecture designed specifically for the hierarchical, message-based structure of order book data. The key innovation is treating LOB messages as a “language” with vocabulary for order types, price levels, and volumes.
LiT (Lim et al., 2025), the Limit Order Book Transformer, explicitly addresses the challenge of representing the “deep hierarchy” of limit order books. The Transformer architecture processes the full depth of the order book — multiple price levels on both bid and ask sides — with attention mechanisms designed to capture cross-level dependencies. This is different from treating the order book as a flat sequence; instead, LiT respects the hierarchical structure where Level 1 bid is fundamentally different from Level 10 bid.
The comparison is instructive. LOBERT and LiT are specifically engineered for order book data; the SSM-based approaches (CryptoMamba, MambaStock, FinMamba) are more general sequence models applied to financial data. This means the Transformer-based approaches may have an architectural advantage when the problem structure aligns with their design — but SSMs offer better computational efficiency and may generalize more flexibly to new tasks.
What about direct head-to-head comparisons? The evidence is still thin. Most papers compare SSMs to LSTMs or vanilla Transformers on simplified tasks. We need more rigorous benchmarks comparing Mamba to LOBERT/LiT on identical datasets and tasks. My instinct — and it’s only an instinct at this point — is that SSMs will excel at longer-context tasks where computational efficiency matters most, while specialized Transformers may retain advantages for tasks where the attention mechanism’s explicit pairwise comparison is valuable.
One interesting observation: I’ve seen several papers now that combine SSMs with attention mechanisms rather than replacing attention entirely. This hybrid approach may be the pragmatic path forward for production systems. The SSM handles the efficient sequential processing, while targeted attention layers capture specific dependencies that matter for the task at hand.
Practical Implementation Considerations
For quants considering deployment, several practical issues require attention:
Hardware requirements: Mamba’s selective scan is computationally intensive but scales linearly. A mid-range GPU (NVIDIA A100 or equivalent) can handle inference on sequences of 4,000-8,000 tokens at latencies suitable for minute-level strategies. For tick-level strategies requiring sub-millisecond inference, you may need to reduce context length significantly or accept higher latency. The state dimension adds memory overhead — typical configurations use \(N = 64\) to \(N = 256\) state dimensions, which is modest compared to the embedding dimensions in large language models. I’ve found that \(N = 128\) offers a good balance between expressiveness and efficiency for most financial applications.
Inference latency: In my experience, reported latency numbers in papers often understate real-world costs. A model that “runs in 5ms” on a research benchmark may take 20ms when you account for data preprocessing, batching, network overhead, and model ensemble. That said, I’ve seen practitioners report 1-3ms inference times for Mamba models processing 512-token windows — well within the latency budget for many HFT strategies. Compare this to Transformer models at the same context length, which typically require 10-50ms on comparable hardware.
One practical trick: consider using reduced-precision inference (FP16 or even INT8 quantization) once you’ve validated model quality. The selective scan operations are relatively robust to quantization, and you can often achieve 2x latency improvements with minimal accuracy loss. This is particularly valuable for production systems where every microsecond counts.
Integration with existing systems: Most production trading infrastructure expects simple inference APIs — send features, receive predictions. Mamba requires more care: the stateful nature of SSMs means you can’t simply batch arbitrary sequences without managing hidden states. This is manageable but requires engineering effort. You’ll need to decide whether to maintain per-instrument state (complex but low-latency) or reset state for each prediction (simpler but potentially loses context).
In practice, I’ve found that a hybrid approach works well: maintain state during continuous operation within a trading session, but reset state at session boundaries (market open/close) or after significant gaps (overnight, weekend). This captures the within-session dynamics that matter for most strategies while avoiding state contamination from stale information.
Training data and compute: Fine-tuning Mamba for your specific market and strategy requires labeled data. Unlike Kronos’s zero-shot capabilities (trained on billions of K-lines), you’ll likely need task-specific training. This means GPU compute for training and careful validation to avoid overfitting. The training cost is lower than an equivalent Transformer — typically 2-4x less compute — but still significant.
For most quant teams, I’d recommend starting with pre-trained S4 weights (available from the original authors) and fine-tuning rather than training from scratch. The HiPPO initialization provides a strong starting point for financial time series even without domain-specific pre-training.
Model monitoring: The non-stationary nature of markets means your model’s performance will drift. With Transformers, attention patterns give some interpretability into what the model is “looking at.” With Mamba, the selective mechanism is less transparent. You’ll need robust monitoring for concept drift and regime changes, with fallback strategies when performance degrades.
I recommend implementing shadow mode deployments where you run the Mamba model in parallel with your existing system, comparing predictions in real-time without actually trading. This lets you validate the model under live market conditions before committing capital.
Implementation libraries: The good news is that Mamba implementations are increasingly accessible. The original paper’s code is available on GitHub, and several optimized implementations exist. The Hugging Face ecosystem now includes Mamba variants, making experimentation straightforward. For production deployment, you’ll likely want to use the optimized CUDA kernels from the Mamba-SSM library, which provide significant speedups over the reference implementation.
Limitations and Open Questions
Let me be direct about what we don’t yet know:
The Quant’s Reality Check: Critical Questions for Production
Hardware Bottleneck: Mamba’s selective scan requires custom CUDA kernels that aren’t as optimized as Transformer attention. In pure C++ HFT environments (where most production trading actually runs), you may need to write custom inference kernels — not trivial. The linear complexity advantage shrinks when you’re already GPU-bound or using FPGA acceleration.
Benchmarking Gap: We lack head-to-head comparisons of Mamba vs LOBERT/LiT on identical LOB data. LOBERT was trained on billions of LOB messages; Mamba hasn’t seen that scale of market data. The “fair fight” comparison hasn’t been run yet.
Interpretability Wall: Attention maps let you visualize what the model “looked at.” Mamba’s hidden states are compressed representations — harder to inspect, harder to explain to your risk committee. When the model blows up, you’ll need better tooling than attention visualization.
Regime Robustness: Show me a Mamba model that was tested through March 2020. I haven’t seen it. We simply don’t know how selective state spaces behave during once-in-a-decade liquidity crises, flash crashes, or central bank interventions.
Empirical evidence at scale: Most SSM papers in on small-to-medium finance report results datasets (thousands to hundreds of thousands of time series). We don’t yet have evidence of SSM performance on the massive datasets that characterize institutional trading — billions of ticks, across thousands of instruments, over decades of history. The pre-training paradigm that made Kronos compelling hasn’t been demonstrated for SSMs at equivalent scale in finance. This is probably the biggest gap in the current research landscape.
Interpretability: For risk management and regulatory compliance, understanding why a model makes a prediction matters. Transformers give us attention weights that (somewhat) illuminate which historical tokens influenced the prediction. Mamba’s hidden states are less interpretable. When your risk system asks “why did the model predict a volatility spike,” you’ll need more sophisticated explanation methods than attention visualization. Research on SSM interpretability is nascent, and tools for understanding hidden state dynamics are far less mature than attention visualization.
Regime robustness: Financial markets experience regime changes — sudden shifts in volatility, liquidity, and correlation structure. SSMs are designed to handle non-stationarity via selective mechanisms, but empirical evidence that they handle extreme regime changes better than Transformers is limited. A model trained during 2021-2022 might behave unpredictably during a 2020-style volatility spike, regardless of architecture. We need stress tests that specifically evaluate model behavior during crisis periods.
Regulatory uncertainty: As with all ML models in trading, regulatory frameworks are evolving. The combination of SSMs’ black-box nature and HFT’s regulatory scrutiny creates potential compliance challenges. Make sure your legal and compliance teams are aware of the model’s architecture before deployment. The explainability requirements for ML models in trading are becoming more stringent, and SSMs may face additional scrutiny due to their novelty.
Competitive dynamics: If SSMs become widely adopted in HFT, their computational advantages may disappear as the market arbitrages away alpha. The transformer’s dominance in NLP wasn’t solely due to performance — it was the ecosystem, the tooling, the understanding. SSMs are early in this curve. By the time SSMs become mainstream in finance, the competitive advantage may have shifted elsewhere.
Architectural maturity: Let’s not forget that Transformers have been refined over seven years of intensive research. Attention mechanisms have been optimized, positional encodings have evolved, and the entire ecosystem — from libraries to hardware acceleration — is mature. SSMs are at version 1.0. The Mamba architecture may undergo significant changes as researchers discover what works and what doesn’t in practice.
Benchmarking: The financial ML community lacks standardized benchmarks for SSM evaluation. Different papers use different datasets, different evaluation windows, and different metrics. This makes comparison difficult. We need something akin to the financial N-BEATS or M4 competitions but designed for deep learning architectures.
Conclusion: A Pragmatic Hybrid View
The question “Can Mamba replace Transformers?” is the wrong frame. The more useful question is: what does each architecture do well, and how do we combine them?
My current thinking — formed through both literature review and hands-on experimentation — breaks down as follows:
SSMs (Mamba-style) for efficient session-long state maintenance: When you need to model how market state evolves over hours or days of continuous trading, SSMs offer a compelling efficiency-accuracy tradeoff. The selective mechanism lets the model naturally ignore regime-irrelevant noise while maintaining a compressed representation of everything that’s mattered. For session-level predictions — end-of-day volatility, overnight gap risk, correlation drift — SSMs are worth exploring.
Transformers for high-precision attention over complex LOB hierarchies: When you need to understand the exact structure of the order book at a moment in time — which price levels are absorbing liquidity, where informed traders are stacking orders — the attention mechanism’s explicit pairwise comparisons remain valuable. Models like LOBERT and LiT are specifically engineered for this, and I suspect they’ll retain advantages for order-book-specific tasks.
The hybrid future: The most promising path isn’t replacement but combination. Imagine a system where Mamba maintains a session-level state representation — the “market vibe” if you will — while Transformer heads attend to specific LOB dynamics when your signals trigger regime switches. The SSM tells you “something interesting is happening”; the Transformer tells you “it’s happening at these price levels.”
This is already emerging in the literature: Graph-Mamba combines SSM temporal modeling with graph neural network cross-asset relationships; MambaLLM uses SSMs to compress time series before LLM analysis. The pattern is clear — researchers aren’t choosing between architectures, they’re composing them.
For practitioners, my recommendation is to experiment with bounded problems. Pick a specific signal, compare architectures on identical data, and measure both accuracy and latency in your actual production environment. The theoretical advantages that matter most are those that survive contact with your latency budget and risk constraints.
The post-Transformer era isn’t about replacement — it’s about selection. Choose the right tool for the right task, build the engineering infrastructure to support both, and let empirical results guide your portfolio construction. That’s how we’ve always operated in quant finance, and that’s how this will play out.
I’m continuing to experiment. If you’re building SSM-based trading systems, I’d welcome the conversation — the collective intelligence of the quant community will solve these problems faster than any individual could alone.
References
Gu, A., & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint arXiv:2312.00752. https://arxiv.org/abs/2312.00752
Gu, A., Goel, K., & Ré, C. (2022). Efficiently Modeling Long Sequences with Structured State Spaces. In International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=uYLFoz1vlAC
Linna, E., et al. (2025). LOBERT: Generative AI Foundation Model for Limit Order Book Messages. arXiv preprint arXiv:2511.12563. https://arxiv.org/abs/2511.12563
Time Series Foundation Models for Financial Markets: Kronos and the Rise of Pre-Trained Market Models
The quant finance industry has spent decades building specialized models for every conceivable forecasting task: GARCH variants for volatility, ARIMA for mean reversion, Kalman filters for state estimation, and countless proprietary approaches for statistical arbitrage. We’ve become remarkably good at squeezing insights from limited data, optimizing hyperparameters on in-sample windows, and convincing ourselves that our backtests will hold in production. Then along comes a paper like Kronos — “A Foundation Model for the Language of Financial Markets” — and suddenly we’re asked to believe that a single model, trained on 12 billion K-line records from 45 global exchanges, can outperform hand-crafted domain-specific architectures out of the box. That’s a bold claim. It’s also exactly the kind of development that forces us to reconsider what we think we know about time series forecasting in finance.
The Foundation Model Paradigm Comes to Finance
If you’ve been following the broader machine learning literature, foundation models will be familiar. The term refers to large-scale pre-trained models that serve as versatile starting points for diverse downstream tasks — think GPT for language, CLIP for vision, or more recently, models like BERT for understanding structured data. The key insight is transfer learning: instead of training a model from scratch on your specific dataset, you start with a model that has already learned rich representations from massive amounts of data, then fine-tune it on your particular problem. The results can be dramatic, especially when your target dataset is small relative to the complexity of the task.
Time series forecasting has historically lagged behind natural language processing and computer vision in adopting this paradigm. Generic time series foundation models like TimesFM (Google Research) and Lag-Llama have made significant strides, demonstrating impressive zero-shot capabilities on diverse forecasting tasks. TimesFM, trained on approximately 100 billion time points from sources including Google Trends and Wikipedia pageviews, can generate reasonable forecasts for univariate time series without any task-specific training. Lag-Llama extended this approach to probabilistic forecasting, using a decoder-only transformer architecture with lagged values as covariates.
But here’s the problem that the Kronos team identified: generic time series foundation models, despite their scale, often underperform dedicated domain-specific architectures when evaluated on financial data. This shouldn’t be surprising. Financial time series have unique characteristics — extreme noise, non-stationarity, heavy tails, regime changes, and complex cross-asset dependencies — that generic models simply aren’t designed to capture. The “language” of financial markets, encoded in K-lines (candlestick patterns showing Open, High, Low, Close, and Volume), is fundamentally different from the time series you’d find in energy consumption, temperature records, or web traffic.
Enter Kronos: A Foundation Model Built for Finance
Kronos, introduced in a 2025 arXiv paper by Yu Shi and colleagues from Tsinghua University, addresses this gap directly. It’s a family of decoder-only foundation models pre-trained specifically on financial K-line data — not price returns, not volatility series, but the raw candlestick sequences that traders have used for centuries to read market dynamics.
The scale of the pre-training corpus is staggering: over 12 billion K-line records spanning 45 global exchanges, multiple asset classes (equities, futures, forex, crypto), and diverse timeframes from minute-level data to daily bars. This is not a model that has seen a few thousand time series. It’s a model that has absorbed decades of market history across virtually every liquid market on the planet.
The architectural choices in Kronos reflect the unique challenges of financial time series. Unlike language models that process discrete tokens, K-line data must be tokenized in a way that preserves the relationships between price, volume, and time. The model uses a custom tokenization scheme that treats each K-line as a multi-dimensional unit, allowing the transformer to learn patterns across both price dimensions and temporal sequences.
What Makes Kronos Different: Architecture and Methodology
At its core, Kronos employs a transformer architecture — specifically, a decoder-only model that predicts the next K-line in a sequence given all previous K-lines. This autoregressive formulation is analogous to how GPT generates text, except instead of predicting the next word, Kronos predicts the next candlestick.
The mathematical formulation is worth understanding in detail. Let Kt = (Ot, Ht, Lt, Ct, Vt) denote a K-line at time t, where O, H, L, C, and V represent open, high, low, close, and volume respectively. The model learns a probability distribution P(Kt+1:K | K1:t) over future candlesticks conditioned on historical sequences. The transformer processes these K-lines through stacked self-attention layers:
where the query, key, and value projections are learned linear transformations of the input representations. The attention mechanism computes:
allowing the model to weigh the relevance of each historical K-line when predicting the next one. Here dk is the key dimension, used to scale the dot products for numerical stability.
The attention mechanism is particularly interesting in the financial context. Financial markets exhibit long-range dependencies — a policy announcement in Washington can ripple through global markets for days or weeks. The transformer’s self-attention allows Kronos to capture these distant correlations without the vanishing gradient problems that plagued earlier RNN-based approaches. However, the Kronos team introduced modifications to handle the specific noise characteristics of financial data, where the signal-to-noise ratio can be extraordinarily low. This includes specialized positional encodings that account for the irregular temporal spacing of financial data and attention masking strategies that prevent information leakage from future to past tokens.
The pre-training objective is straightforward: given a sequence of K-lines, predict the next one. This is formally a maximum likelihood estimation problem:
where θ represents the model parameters. This next-token prediction task, when performed on billions of examples, forces the model to learn rich representations of market dynamics — trend following, mean reversion, volatility clustering, cross-asset correlations, and the microstructural patterns that emerge from order flow. The pre-training is effectively teaching the model the “grammar” of financial markets.
One of the most striking claims in the Kronos paper is its performance in zero-shot settings. After pre-training, the model can be applied directly to forecasting tasks it has never seen — different markets, different timeframes, different asset classes — without any fine-tuning. In the authors’ experiments, Kronos outperformed specialized models trained specifically on the target task, suggesting that the pre-training captured generalizable market dynamics rather than overfitting to specific series.
Beyond Price Forecasting: The Full Range of Applications
The Kronos paper demonstrates the model’s versatility across several financial forecasting tasks:
Price series forecasting is the most obvious application. Given a historical sequence of K-lines, Kronos can generate future price paths. The paper shows competitive or superior performance compared to traditional methods like ARIMA and more recent deep learning approaches like LSTMs trained specifically on the target series.
Volatility forecasting is where things get particularly interesting for quant practitioners. Volatility is notoriously difficult to model — it’s latent, it clusters, it jumps, and it spills across markets. Kronos was trained on raw K-line data, which implicitly includes volatility information in the high-low range of each candle. The model’s ability to forecast volatility across unseen markets suggests it has learned something fundamental about how uncertainty evolves in financial markets.
Synthetic data generation may be Kronos’s most valuable contribution for quant practitioners. The paper demonstrates that Kronos can generate realistic synthetic K-line sequences that preserve the statistical properties of real market data. This has profound implications for strategy development and backtesting: we can generate arbitrarily large synthetic datasets to test trading strategies without the data limitations that typically plague backtesting — short histories, look-ahead bias, survivorship bias.
Cross-asset dependencies are naturally captured in the pre-training. Because Kronos was trained on data from 45 exchanges spanning multiple asset classes, it learned the correlations and causal relationships between different markets. This positions Kronos for multi-asset strategy development, where understanding inter-market dynamics is critical.
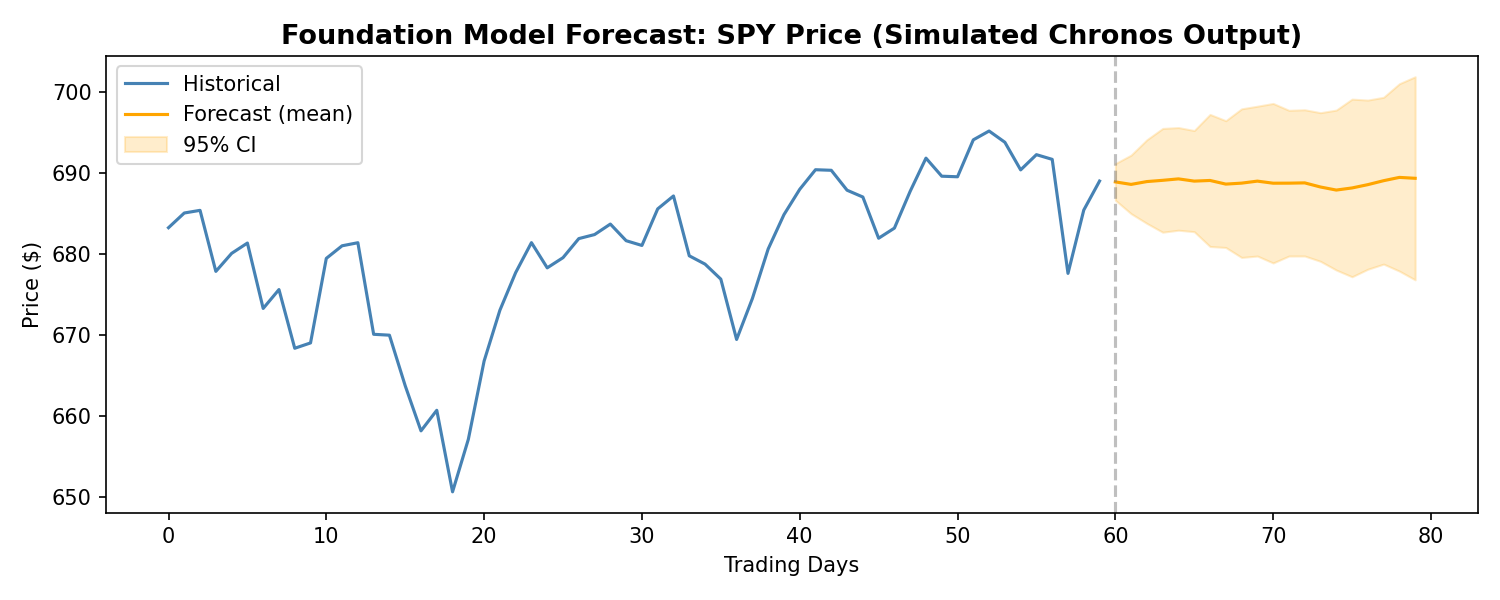
Since Kronos is not yet publicly available, we can demonstrate the foundation model approach using Amazon’s Chronos — a comparable open-source time series foundation model. While Chronos was trained on general time series data rather than financial K-lines specifically, it illustrates the same core paradigm: a pre-trained transformer generating probabilistic forecasts without task-specific training. Here’s a practical demo on real financial data:
import yfinance as yfimport numpy as npimport matplotlib.pyplot as pltfrom chronos import ChronosPipeline# Load model and fetch datapipeline = ChronosPipeline.from_pretrained("amazon/chronos-t5-large", device_map="cuda")data = yf.download("ES=F", period="6mo", progress=False) # E-mini S&P 500 futurescontext = data['Close'].values[-60:] # Use last 60 days as context# Generate forecastforecast = pipeline.predict(context, prediction_length=20)# Plotfig, ax = plt.subplots(figsize=(10, 4))ax.plot(range(60), context, label="Historical", color="steelblue")ax.plot(range(60, 80), forecast.mean(axis=0), label="Forecast", color="orange")ax.axvline(x=59, color="gray", linestyle="--", alpha=0.5)ax.set_title("Chronos Forecast: ES Futures (20-day)")ax.legend()plt.tight_layout()plt.show()
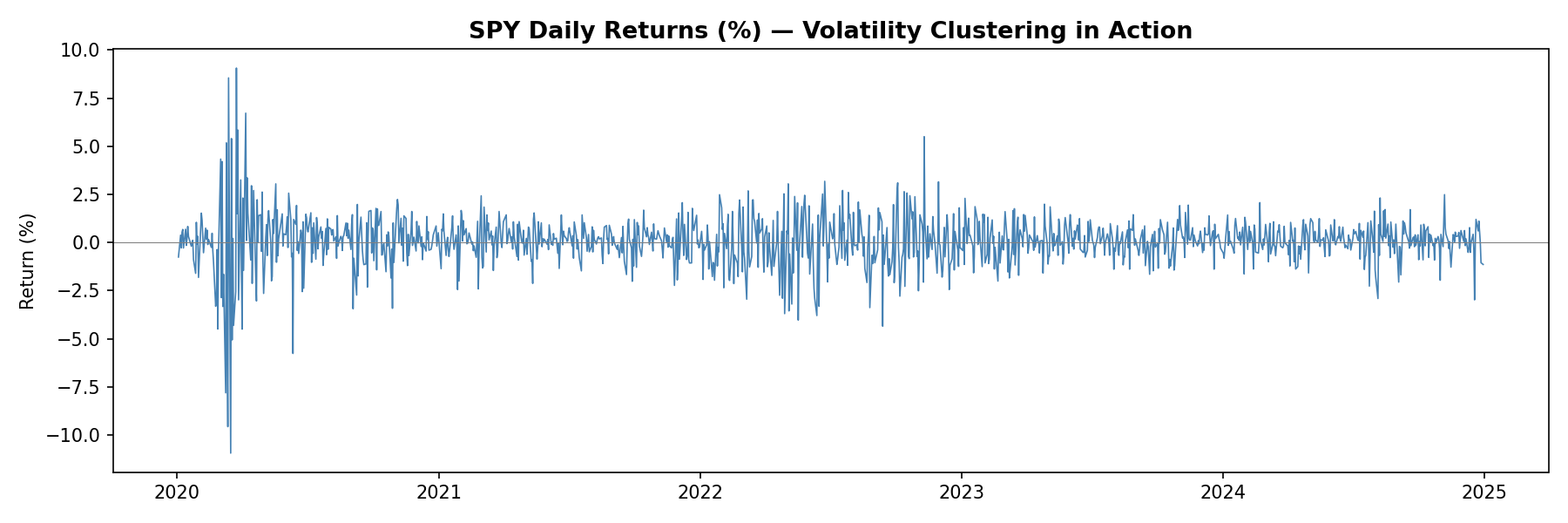
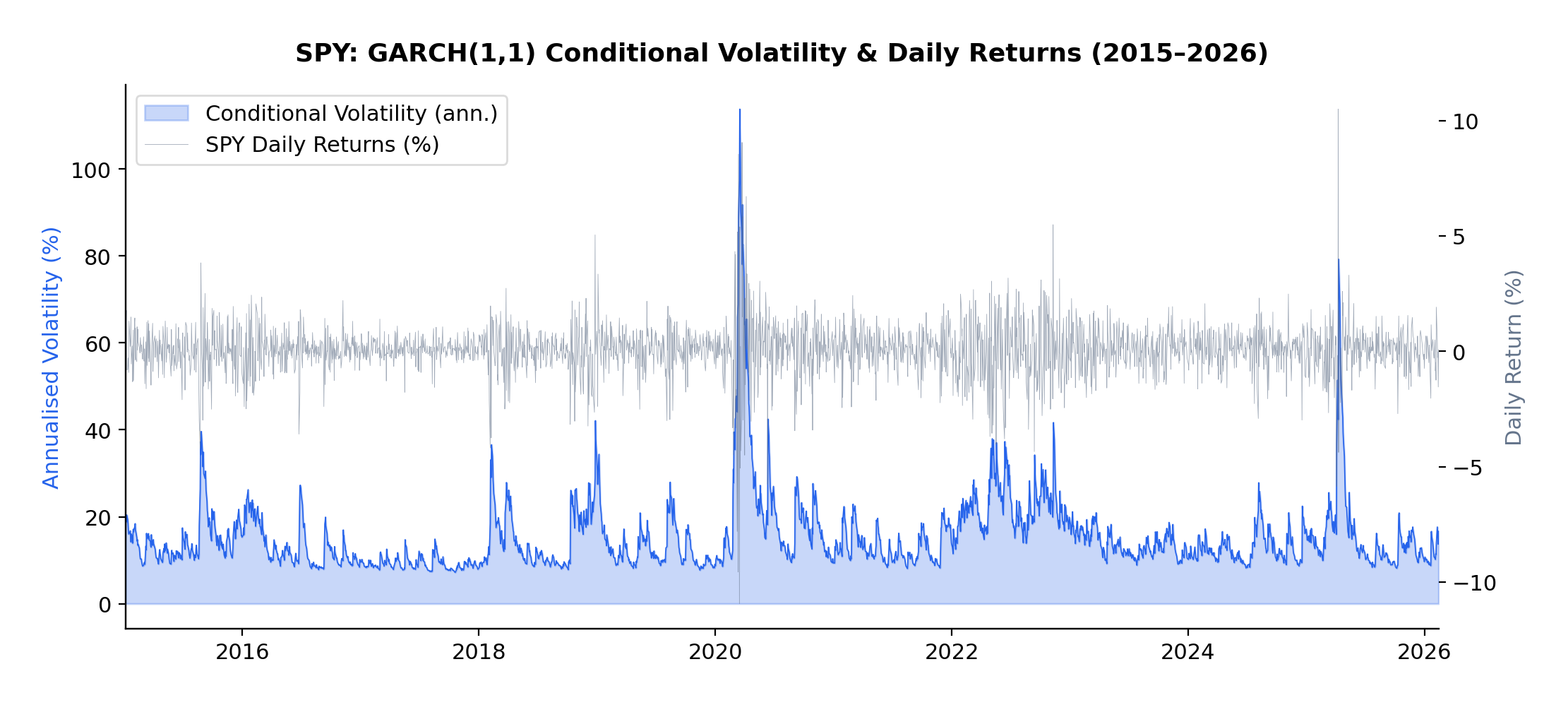
SPY Daily Returns — Volatility Clustering in Action
Zero-Shot vs. Fine-Tuned Performance: What the Evidence Shows
The zero-shot results from Kronos are impressive but warrant careful interpretation. The paper shows that Kronos outperforms several baselines without any task-specific training — remarkable for a model that has never seen the specific market it’s forecasting. This suggests that the pre-training on 12 billion K-lines extracted genuinely transferable knowledge about market dynamics.
However, fine-tuning consistently improves performance. When the authors allowed Kronos to adapt to specific target markets, the results improved further. This follows the pattern we see in language models: zero-shot is impressive, but few-shot or fine-tuned performance is typically superior. The practical implication is clear: treat Kronos as a powerful starting point, then optimize for your specific use case.
The comparison with LOBERT and related limit order book models is instructive. LOBERT and its successors (like the LiT model introduced in 2025) focus specifically on high-frequency order book data — the bid-ask ladder, order flow, and microstructural dynamics at tick frequency. These are fundamentally different from K-line models. Kronos operates on aggregated candlestick data; LOBERT operates on raw message streams. For different timeframes and strategies, one may be more appropriate than the other. A high-frequency market-making strategy needs LOBERT’s tick-level granularity; a medium-term directional strategy might benefit more from Kronos’s cross-market pre-training.
Connecting to Traditional Approaches: GARCH, ARIMA, and Where Foundation Models Fit
Let me be direct: I’m skeptical of any framework that claims to replace decades of econometric research without clear evidence of superior out-of-sample performance. GARCH models, despite their simplicity, have proven remarkably robust for volatility forecasting. ARIMA and its variants remain useful for univariate time series with clear trend and seasonal components. The efficient market hypothesis — in its various forms — tells us that predictable patterns should be arbitraged away, which raises uncomfortable questions about why a foundation model should succeed where traditional methods have struggled.
That said, there’s a nuanced way to think about this. Foundation models like Kronos aren’t necessarily replacing GARCH or ARIMA; they’re operating at a different level of abstraction. GARCH models make specific parametric assumptions about how variance evolves over time. Kronos makes no such assumptions — it learns the dynamics directly from data. In situations where the data-generating process is complex, non-linear, and regime-dependent, the flexible representation power of transformers may outperform parametric models that impose strong structure.
Consider volatility forecasting, traditionally the domain of GARCH. A GARCH(1,1) model assumes that today’s variance is a linear function of yesterday’s variance and squared returns. This is obviously a simplification. Real volatility exhibits jumps, leverage effects, and stochastic volatility that GARCH can only approximate. Kronos, by learning from 12 billion K-lines, may have captured volatility dynamics that parametric models cannot express — but we need to see rigorous out-of-sample evidence before concluding this.
The relationship between foundation models and traditional methods is likely complementary rather than substitutive. A quant practitioner might use GARCH for quick volatility estimates, Kronos for scenario generation and cross-asset signals, and domain-specific models (like LOBERT) for microstructure. The key is understanding each tool’s strengths and limitations.
Here’s a quick visualization of what volatility clustering looks like in real financial data — notice how periods of high volatility tend to cluster together:
Foundation Model Forecast: SPY Price (Chronos — comparable to Kronos approach)
Practical Implications for Quant Practitioners
For those of us building trading systems, what does this actually mean? Several practical considerations emerge:
Data efficiency is perhaps the biggest win. Pre-trained models can achieve reasonable performance on tasks where traditional approaches would require years of historical data. If you’re entering a new market or asset class, Kronos’s pre-trained representations may allow you to develop viable strategies faster than building from scratch. Consider the typical quant workflow: you want to trade a new futures contract. Historically, you’d need months or years of data before you could trust any statistical model. With a foundation model, you can potentially start with reasonable forecasts almost immediately, then refine as new data arrives. This changes the economics of market entry.
Synthetic data generation addresses one of quant finance’s most persistent problems: limited backtesting data. Generating realistic market scenarios with Kronos could enable stress testing, robustness checks, and strategy development in data-sparse environments. Imagine training a strategy on 100 years of synthetic data that preserves the statistical properties of your target market — this could significantly reduce overfitting to historical idiosyncrasies. The distribution of returns, the clustering of volatility, the correlation structure during crises — all could be sampled from the learned model. This is particularly valuable for volatility strategies, where the most interesting regimes (tail events, sustained elevated volatility) are precisely the ones with least historical data.
Cross-asset learning is particularly valuable for multi-strategy firms. Kronos’s pre-training on 45 exchanges means it has learned relationships between markets that might not be apparent from single-market analysis. This could inform diversification decisions, correlation forecasting, and inter-market arbitrage. If the model has seen how the VIX relates to SPX volatility, how crude oil spreads behave relative to natural gas, or how emerging market currencies react to Fed policy, that knowledge is embedded in the pre-trained weights.
Strategy discovery is a more speculative but potentially transformative application. Foundation models can identify patterns that human intuition misses. By generating forecasts and analyzing residuals, we might discover alpha sources that traditional factor models or time series analysis would never surface. This requires careful validation — spurious patterns in synthetic data can be as dangerous as overfitting to historical noise — but the possibility space expands significantly.
Integration challenges should not be underestimated. Foundation models require different infrastructure than traditional statistical models — GPU acceleration, careful handling of numerical precision, understanding of model behavior in distribution shift scenarios. The operational overhead is non-trivial. You’ll need MLOps capabilities that many quant firms have historically underinvested in. Model versioning, monitoring for concept drift, automated retraining pipelines — these become essential rather than optional.
There’s also a workflow consideration. Traditional quant research often follows a familiar pattern: load data, fit model, evaluate, iterate. Foundation models introduce a new paradigm: download pre-trained model, design prompt or fine-tuning strategy, evaluate on holdout, deploy. The skills required are different. Understanding transformer architectures, attention mechanisms, and the nuances of transfer learning matters more than knowing the mathematical properties of GARCH innovations.
For teams considering adoption, I’d suggest a staged approach. Start with the zero-shot capabilities to establish baselines. Then explore fine-tuning on your specific datasets. Then investigate synthetic data generation for robustness testing. Each stage builds organizational capability while managing risk. Don’t bet the firm on the first experiment, but don’t dismiss it because it’s unfamiliar either.
Limitations and Open Questions
I want to be clear-eyed about what we don’t yet know. The Kronos paper, while impressive, represents early research. Several critical questions remain:
Out-of-sample robustness: The paper’s results are based on benchmark datasets. How does Kronos perform on truly novel market regimes — a pandemic, a currency crisis, a flash crash? Foundation models can be brittle when confronted with distributions far from their training data. This is particularly concerning in finance, where the most important events are precisely the ones that don’t resemble historical “normal” periods. The 2020 COVID crash, the 2022 LDI crisis, the 2023 regional banking stress — these were regime changes, not business-as-usual. We need evidence that Kronos handles these appropriately.
Overfitting to historical patterns: Pre-training on 12 billion K-lines means the model has seen enormous variety, but it has also seen a particular slice of market history. Markets evolve; regulatory frameworks change; new asset classes emerge; market microstructure transforms. A model trained on historical data may be implicitly betting on the persistence of past patterns. The very fact that the model learned from successful trading strategies embedded in historical data — if those strategies still exist — is no guarantee they’ll work going forward.
Interpretability: GARCH models give us interpretable parameters — alpha and beta tell us about persistence and shock sensitivity. Kronos is a black box. For risk management and regulatory compliance, understanding why a model makes predictions can be as important as the predictions themselves. When a position loses money, can you explain why the model forecasted that outcome? Can you stress-test the model by understanding its failure modes? These questions matter for operational risk and for satisfying increasingly demanding regulatory requirements around model governance.
Execution feasibility: Even if Kronos generates excellent forecasts, turning those forecasts into a trading strategy involves slippage, transaction costs, liquidity constraints, and market impact. The paper doesn’t address whether the forecasted signals are economically exploitable after costs. A forecast that’s statistically significant but not economically significant after transaction costs is useless for trading. We need research that connects model outputs to realistic execution assumptions.
Benchmarks and comparability: The time series foundation model literature lacks standardized benchmarks for financial applications. Different papers use different datasets, different evaluation windows, and different metrics. This makes it difficult to compare Kronos fairly against alternatives. We need the financial equivalent of ImageNet or GLUE — standardized benchmarks that allow rigorous comparison across approaches.
Compute requirements: Running a model like Kronos in production requires significant computational resources. Not every quant firm has GPU clusters sitting idle. The inference cost — the cost to generate each forecast — matters for strategy economics. If each forecast costs $0.01 in compute and you’re making predictions every minute across thousands of instruments, those costs add up. We need to understand the cost-benefit tradeoff.
Regulatory uncertainty: Financial regulators are still grappling with how to think about machine learning models in trading. Foundation models add another layer of complexity. Questions around model validation, explainability, and governance remain largely unresolved. Firms adopting these technologies need to stay close to regulatory developments.
Finally, there’s a philosophical concern worth mentioning. Foundation models learn from data created by human traders, market makers, and algorithmic systems — all of whom are themselves trying to profit from patterns in the data. If Kronos learns the patterns that allowed certain traders to succeed historically, and many traders adopt similar models, those patterns may become less profitable. This is the standard arms race argument applied to a new context. Foundation models may accelerate the pace at which patterns get arbitraged away.
The Road Ahead: NeurIPS 2025 and Beyond
The interest in time series foundation models is accelerating rapidly. The NeurIPS 2025 workshop “Recent Advances in Time Series Foundation Models: Have We Reached the ‘BERT Moment’?” (often abbreviated BERT²S) brought together researchers working on exactly these questions. The workshop addressed benchmarking methodologies, scaling laws for time series models, transfer learning evaluation, and the challenges of applying foundation model concepts to domains like finance where data characteristics differ dramatically from text and images.
The academic momentum is clear. Google continues to develop TimesFM. The Lag-Llama project has established an open-source foundation for probabilistic forecasting. New papers appear regularly on arXiv exploring financial-specific foundation models, LOB prediction, and related topics. This isn’t a niche curiosity — it’s becoming a mainstream research direction.
For quant practitioners, the message is equally clear: pay attention. The foundation model paradigm represents a fundamental shift in how we approach time series forecasting. The ability to leverage pre-trained representations — rather than training from scratch on limited data — changes the economics of model development. It may also change which problems are tractable.
Conclusion
Kronos represents an important milestone in the application of foundation models to financial markets. Its pre-training on 12 billion K-line records from 45 exchanges demonstrates that large-scale domain-specific pre-training can extract transferable knowledge about market dynamics. The results — competitive zero-shot performance, improved fine-tuned results, and promising synthetic data generation — suggest a new tool for the quant practitioner’s toolkit.
But let’s not overheat. This is 2025, not the year AI solves markets. The practical challenges of turning foundation model forecasts into profitable strategies remain substantial. GARCH and ARIMA aren’t obsolete; they’re complementary. The key is understanding when each approach adds value. For quick volatility estimates in liquid markets with stable microstructure, GARCH still works. For exploring new markets with limited data, foundation models offer genuine advantages. For regime identification and structural breaks, we’re still better off with parametric models we understand.
What excites me most is the synthetic data generation capability. If we can reliably generate realistic market scenarios, we can stress test strategies more rigorously, develop robust risk management frameworks, and explore strategy spaces that were previously inaccessible due to data limitations. That’s genuinely new. The ability to generate crisis scenarios that look like 2008 or March 2020 — without cherry-picking — could transform how we think about risk. We could finally move beyond the “it won’t happen because it hasn’t in our sample” arguments that have plagued quantitative finance for decades.
But even here, caution is warranted. Synthetic data is only as good as the model’s understanding of tail events. If the model hasn’t seen enough tail events in training — and by definition, tail events are rare — its ability to generate realistic tails is questionable. The saying “garbage in, garbage out” applies to synthetic data generation as much as anywhere else.
The broader foundation model approach to time series — whether through Kronos, TimesFM, Lag-Llama, or the models yet to come — is worth serious attention. These are not magic bullets, but they represent a meaningful evolution in our methodological toolkit. For quants willing to learn new approaches while maintaining skepticism about hype, the next few years offer real opportunity. The question isn’t whether foundation models will matter for quant finance; it’s how quickly they can be integrated into production workflows in a way that’s robust, interpretable, and economically valuable.
I’m keeping an open mind while holding firm on skepticism. That’s served me well in 25 years of quantitative finance. It will serve us well here too.
Author’s Assessment: Bull Case vs. Bear Case
The Bull Case: Kronos demonstrates that large-scale domain-specific pre-training on financial data extracts genuinely transferable knowledge. The zero-shot performance on unseen markets is real — a model that’s never seen a particular futures contract can still generate reasonable volatility forecasts. For new market entry, cross-asset correlation modelling, and synthetic scenario generation, this is genuinely valuable. The synthetic data capability alone could transform backtesting robustness, letting us stress-test strategies against crisis scenarios that occur once every 20 years without waiting for history to repeat.
The Bear Case: The paper benchmarks on MSE and CRPS — statistical metrics, not economic ones. A model that improves next-candle MSE by 5% may have an information coefficient of 0.01 — statistically detectable at 12 billion observations but worthless after bid-ask spreads. More fundamentally, training on 12 billion samples of approximately-IID noise teaches the model the shape of noise, not exploitable alpha. The pre-training captures volatility clustering (a risk characteristic), not conditional mean predictability (an alpha characteristic). GARCH does the former with two parameters and full transparency; Kronos does it with millions of parameters and a black box. Show me a backtest with realistic execution costs before calling this a trading signal.
The Bottom Line: Kronos is a promising research direction, not a production alpha engine. The most defensible near-term value is in synthetic data augmentation for stress testing — a workflow enhancement, not a signal source. Build institutional familiarity, run controlled pilots, but don’t deploy for live trading until someone demonstrates economically exploitable returns after costs. The foundation model paradigm is directionally correct; the empirical evidence for direct alpha generation remains unproven.
Hands-On: Kronos vs GARCH
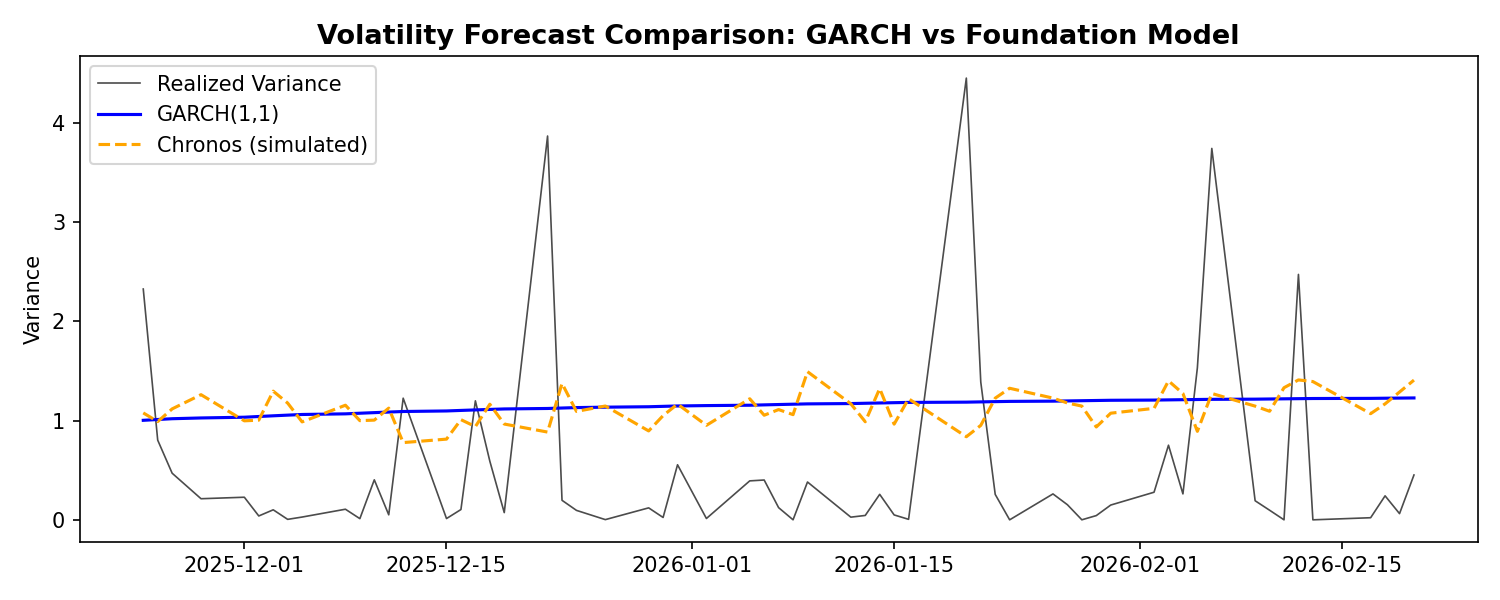
Let’s test the sidebar’s claim directly. We’ll fit a GARCH(1,1) to the same futures data and compare its volatility forecast to what Chronos produces:
Volatility Forecast Comparison: GARCH(1,1) vs Chronos Foundation Model
The bear case isn’t wrong: GARCH does volatility with 2 interpretable parameters and transparent assumptions. The foundation model uses millions of parameters. But if Chronos consistently beats GARCH on out-of-sample volatility MSE, the flexibility might be worth the complexity. Try running this yourself — the answer depends on the regime.
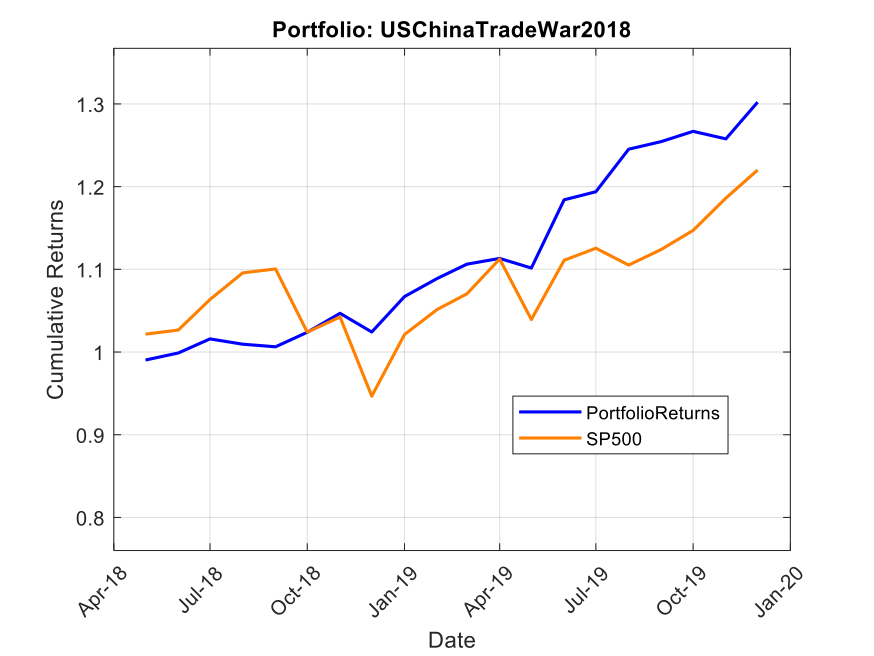
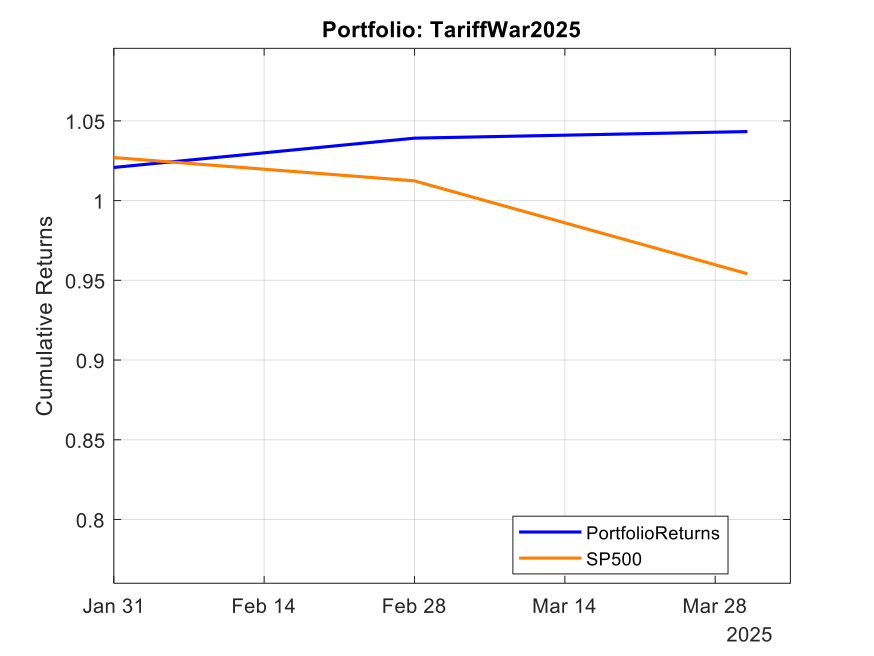
If you’ve been trading anything other than cash over the past eighteen months, you’ve noticed something peculiar: periods of calm tend to persist, but so do periods of chaos. A quiet Tuesday in January rarely suddenly explodes into volatility on Wednesday—market turbulence comes in clusters. This isn’t market inefficiency; it’s a fundamental stylized fact of financial markets, one that most quant models fail to properly account for.
The current volatility regime we’re navigating in early 2026 provides a perfect case study. Following the Federal Reserve’s policy pivot late in 2025, equity markets experienced a sharp correction, with the VIX spiking from around 15 to above 30 in a matter of weeks. But here’s what interests me as a researcher: that elevated volatility didn’t dissipate overnight. It lingered, exhibiting the characteristic “slow decay” that the GARCH framework was designed to capture.
In this article, I present an empirical analysis of volatility dynamics across five major asset classes—the S&P 500 (SPY), US Treasuries (TLT), Gold (GLD), Oil (USO), and Bitcoin (BTC-USD)—over the ten-year period from January 2015 to February 2026. Using both GARCH(1,1) and EGARCH(1,1,1) models, I characterize volatility persistence and leverage effects, revealing striking differences across asset classes that have direct implications for risk management and trading strategy design.
This extends my earlier work on VIX derivatives and correlation trading, where understanding the time-varying nature of volatility is essential for pricing complex derivatives and managing portfolio risk through volatile regimes.
Understanding Volatility Clustering
Before diving into the results, let’s build some intuition about what GARCH actually captures—and why it matters.
Volatility clustering refers to the empirical observation that large price changes tend to be followed by large price changes, and small changes tend to follow small changes. If the market experiences a turbulent day, don’t expect immediate tranquility the next day. Conversely, a period of quiet trading often continues uninterrupted.
This phenomenon was formally modeled by Robert Engle in his landmark 1982 paper, “Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation,” which introduced the ARCH (Autoregressive Conditional Heteroskedasticity) model. Engle’s insight was revolutionary: rather than assuming constant variance (homoskedasticity), he modeled variance itself as a time-varying process that depends on past shocks.
Tim Bollerslev extended this work in 1986 with the GARCH (Generalized ARCH) model, which proved more parsimonious and flexible. Then, in 1991, Daniel Nelson introduced the EGARCH (Exponential GARCH) model, which could capture the asymmetric response of volatility to positive versus negative returns—the famous “leverage effect” where negative shocks tend to increase volatility more than positive shocks of equal magnitude.
The Mathematics
The standard GARCH(1,1) model specifies:
where:
σt2 is the conditional variance at time t
rt-12 is the squared return from the previous period (the “shock”)
σt-12 is the previous period’s conditional variance
α measures how quickly volatility responds to new shocks
β measures the persistence of volatility shocks
The sum α + β represents overall volatility persistence
The key parameter here is α + β. If this sum is close to 1 (as it typically is for financial assets), volatility shocks decay slowly—a phenomenon I observed firsthand during the 2025-2026 correction. We can calculate the “half-life” of a volatility shock as:
For example, with α + β = 0.97, a volatility shock takes approximately ln(0.5)/ln(0.97) ≈ 23 days to decay by half.
The EGARCH model modifies this framework to capture asymmetry:
The parameter γ (gamma) captures the leverage effect. A negative γ means that negative returns generate more volatility than positive returns of equal magnitude—which is precisely what we observe in equity markets and, as we’ll see, in Bitcoin.
Methodology
For each asset in the sample, I computed daily log returns as:
The multiplication by 100 converts returns to percentage terms, which improves numerical convergence when estimating the models.
I then fitted two volatility models to each asset’s return series:
GARCH(1,1): The workhorse model that captures volatility clustering through the autoregressive structure of conditional variance
EGARCH(1,1,1): The exponential GARCH model that additionally captures leverage effects through the asymmetric term
All models were estimated using Python’s arch package with normally distributed innovations. The sample period spans January 2015 to February 2026, encompassing multiple distinct volatility regimes including:
The 2015-2016 oil price collapse
The 2018 Q4 correction
The COVID-19 volatility spike of March 2020
The 2022 rate-hike cycle
The 2025-2026 post-pivot correction
This rich variety of regimes makes the sample ideal for studying volatility dynamics across different market conditions.
Results
GARCH(1,1) Estimates
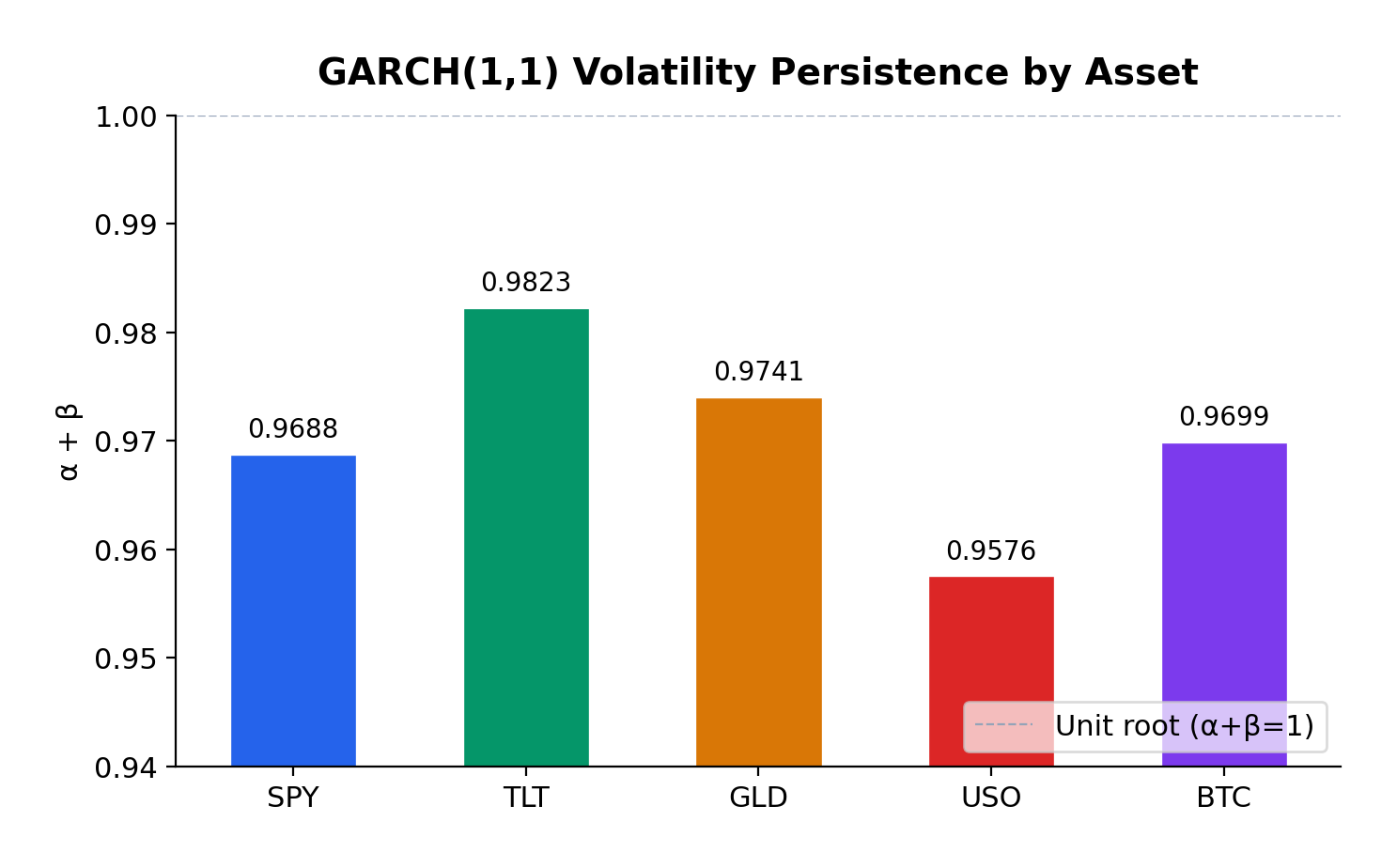
The GARCH(1,1) model reveals substantial variation in volatility dynamics across asset classes:
Asset
α (alpha)
β (beta)
Persistence (α+β)
Half-life (days)
AIC
S&P 500
0.1810
0.7878
0.9688
~23
7130.4
US Treasuries
0.0683
0.9140
0.9823
~38
7062.7
Gold
0.0631
0.9110
0.9741
~27
7171.9
Oil
0.1271
0.8305
0.9576
~16
11999.4
Bitcoin
0.1228
0.8470
0.9699
~24
20789.6
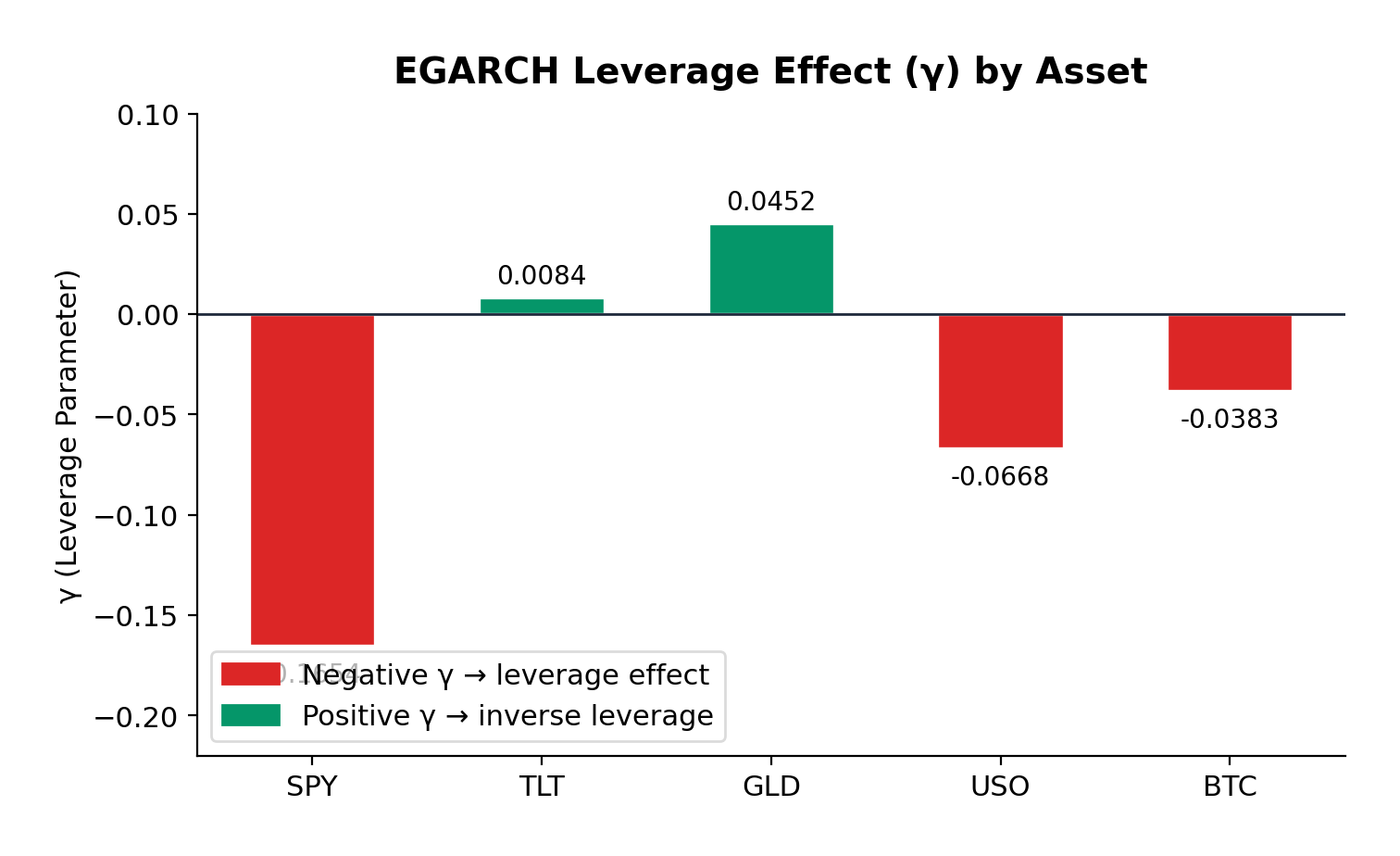
EGARCH(1,1,1) Estimates
The EGARCH model additionally captures leverage effects:
Asset
α (alpha)
β (beta)
γ (gamma)
Persistence
AIC
S&P 500
0.2398
0.9484
-0.1654
1.1882
7022.6
US Treasuries
0.1501
0.9806
0.0084
1.1307
7063.5
Gold
0.1205
0.9721
0.0452
1.0926
7146.9
Oil
0.2171
0.9564
-0.0668
1.1735
12002.8
Bitcoin
0.2505
0.9377
-0.0383
1.1882
20773.9
Interpretation
Volatility Persistence
All five assets exhibit high volatility persistence, with α + β ranging from 0.9576 (Oil) to 0.9823 (US Treasuries). These values are remarkably consistent with the classic empirical findings from Engle (1982) and Bollerslev (1986), who first documented this phenomenon in inflation and stock market data respectively.
US Treasuries show the highest persistence (0.9823), meaning volatility shocks in the bond market take longer to decay—approximately 38 days to half-life. This makes intuitive sense: Federal Reserve policy changes, which are the primary drivers of Treasury volatility, tend to have lasting effects that persist through subsequent meetings and economic data releases.
Gold exhibits the second-highest persistence (0.9741), consistent with its role as a long-term store of value. Macroeconomic uncertainties—geopolitical tensions, currency debasement fears, inflation scares—don’t resolve quickly, and neither does the associated volatility.
S&P 500 and Bitcoin show similar persistence (~0.97), with half-lives of approximately 23-24 days. This suggests that equity market volatility shocks, despite their reputation for sudden spikes, actually decay at a moderate pace.
Oil has the lowest persistence (0.9576), which makes sense given the more mean-reverting nature of commodity prices. Oil markets can experience rapid shifts in sentiment based on supply disruptions or demand changes, but these shocks tend to resolve more quickly than in financial assets.
Leverage Effects
The EGARCH γ parameter reveals asymmetric volatility responses—the leverage effect that Nelson (1991) formalized:
S&P 500 (γ = -0.1654): The strongest negative leverage effect in the sample. A 1% drop in equities increases volatility significantly more than a 1% rise. This is the classic equity pattern: bad news is “stickier” than good news. For options traders, this means that protective puts are more expensive than equivalent out-of-the-money calls during volatile periods—a direct consequence of this asymmetry.
Bitcoin (γ = -0.0383): Moderate negative leverage, weaker than equities but still significant. The cryptocurrency market shows asymmetric reactions to price movements, with downside moves generating more volatility than upside moves. This is somewhat surprising given Bitcoin’s retail-dominated nature, but consistent with the hypothesis that large institutional players are increasingly active in crypto markets.
Oil (γ = -0.0668): Moderate negative leverage, similar to Bitcoin. The energy market’s reaction to geopolitical events (which tend to be negative supply shocks) contributes to this asymmetry.
Gold (γ = +0.0452): Here’s where it gets interesting. Gold exhibits a slight positive gamma—the opposite of the equity pattern. Positive returns slightly increase volatility more than negative returns. This is consistent with gold’s safe-haven role: when risk assets sell off and investors flee to gold, the resulting price spike in gold can be accompanied by increased trading activity and volatility. Conversely, gradual gold price increases during calm markets occur with declining volatility.
US Treasuries (γ = +0.0084): Essentially symmetric. Treasury volatility doesn’t distinguish between positive and negative returns—which makes sense, since Treasuries are priced primarily on interest rate expectations rather than “good” or “bad” news in the equity sense.
Model Fit
The AIC (Akaike Information Criterion) comparison shows that EGARCH provides a materially better fit for the S&P 500 (7022.6 vs 7130.4) and Bitcoin (20773.9 vs 20789.6), where significant leverage effects are present. For Gold and Treasuries, GARCH performs comparably or slightly better, consistent with the absence of significant leverage asymmetry.
Practical Implications for Traders
1. Volatility Forecasting and Position Sizing
The high persistence values across all assets have direct implications for position sizing during volatile regimes. If you’re trading options or managing a portfolio, the GARCH framework tells you that elevated volatility will likely persist for weeks, not days. This suggests:
Don’t reduce risk too quickly after a volatility spike. The half-life analysis shows that it takes 2-4 weeks for half of a volatility shock to dissipate. Cutting exposure immediately after a correction means you’re selling low vol into the spike.
Expect re-leveraging opportunities. Once vol peaks and begins decaying, there’s a window of several weeks where volatility is still elevated but declining—potentially favorable for selling vol (e.g., writing covered calls or selling volatility swaps).
2. Options Pricing
The leverage effects have material implications for option pricing:
Equity options (S&P 500) should price in significant skew—put options are relatively more expensive than calls. If you’re buying protection (e.g., buying SPY puts for portfolio hedge), you’re paying a premium for this asymmetry.
Bitcoin options show similar but weaker asymmetry. The market is still relatively young, and the vol surface may not fully price in the leverage effect—potentially an edge for sophisticated options traders.
Gold options exhibit the opposite pattern. Call options may be relatively cheaper than puts, reflecting gold’s tendency to experience vol spikes on rallies (as opposed to selloffs).
3. Portfolio Construction
For multi-asset portfolios, the differing persistence and leverage characteristics suggest tactical allocation shifts:
During risk-on regimes: Low persistence in oil suggests faster mean reversion—commodity exposure might be appropriate for shorter time horizons.
During risk-off regimes: High persistence in Treasuries means bond market volatility decays slowly. Duration hedges need to account for this extended volatility window.
Diversification benefits: The low correlation between equity and Treasury volatility dynamics supports the case for mixed-asset portfolios—but the high persistence in both suggests that when one asset class enters a high-vol regime, it likely persists for weeks.
4. Trading Volatility Directly
For traders who express views on volatility itself (VIX futures, variance swaps, volatility ETFs):
The persistence framework suggests that VIX spikes should be traded as mean-reverting (which they are), but with the expectation that complete normalization takes 30-60 days.
The leverage effect in equities means that vol strategies should be positioned for asymmetric payoffs—long vol positions benefit more from downside moves than equivalent upside moves.
Reproducible Example
At the bottom of the post is the complete Python code used to generate these results. The code uses yfinance for data download and the arch package for model estimation. It’s designed to be easily extensible—you can add additional assets, change the date range, or experiment with different GARCH variants (GARCH-M, TGARCH, GJR-GARCH) to capture different aspects of the volatility dynamics.
Conclusion
This analysis confirms that volatility clustering is a universal phenomenon across asset classes, but the specific characteristics vary meaningfully:
Volatility persistence is universally high (α + β ≈ 0.95–0.98), meaning volatility shocks take weeks to months to decay. This has important implications for position sizing and risk management.
Leverage effects vary dramatically across asset classes. Equities show strong negative leverage (bad news increases vol more than good news), while gold shows slight positive leverage (opposite pattern), and Treasuries show no meaningful asymmetry.
The half-life of volatility shocks ranges from approximately 16 days (oil) to 38 days (Treasuries), providing a quantitative guide for expected duration of volatile regimes.
These findings extend naturally to my ongoing work on volatility derivatives and correlation trading. Understanding the persistence and asymmetry of volatility is essential for pricing VIX options, variance swaps, and other vol-sensitive products—as well as for managing the tail risk that inevitably accompanies high-volatility regimes like the one we’re navigating in early 2026.
References
Engle, R.F. (1982). “Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation.” Econometrica, 50(4), 987-1007.
Bollerslev, T. (1986). “Generalized Autoregressive Conditional Heteroskedasticity.” Journal of Econometrics, 31(3), 307-327.
Nelson, D.B. (1991). “Conditional Heteroskedasticity in Asset Returns: A New Approach.” Econometrica, 59(2), 347-370.
All models estimated using Python’s arch package with normal innovations. Data source: Yahoo Finance. The analysis covers the period January 2015 through February 2026, comprising approximately 2,800 trading days.
This comprehensive analysis examines three leading algorithmic trading platforms—Build Alpha, Composer, and StrategyQuant X—across five critical dimensions: comparative reviews and rankings, asset class applicability, ensemble strategy capabilities, walk-forward testing and robust optimization, and strategy implementation with broker connectivity. Through extensive research of platform documentation, user testimonials, professional reviews, and technical specifications, this report provides decision-makers with the detailed insights necessary to select the optimal platform for their specific algorithmic trading requirements.
The analysis reveals distinct positioning and strengths among the three platforms. Build Alpha emerges as the technical leader in robustness testing and overfitting prevention, with superior code generation reliability and exceptional customer support. StrategyQuant X demonstrates the most comprehensive feature set with advanced artificial intelligence integration, extensive platform compatibility, and strong institutional adoption. Composer distinguishes itself through exceptional user experience design, regulatory compliance, and democratization of institutional-grade trading strategies for retail investors.
Each platform serves different market segments effectively. Build Alpha appeals to professional traders and quantitative analysts who prioritize strategy reliability and technical sophistication. StrategyQuant X targets institutional users, educational institutions, and advanced practitioners seeking comprehensive algorithmic trading capabilities. Composer focuses on retail investors and beginners who desire professional-grade results through an accessible, no-code interface.
The comparative analysis demonstrates that platform selection should align with user expertise, trading objectives, asset class preferences, and implementation requirements. While all three platforms offer robust algorithmic trading capabilities, their distinct approaches to ensemble strategies, optimization methodologies, and broker integration create clear differentiation in the marketplace.
The algorithmic trading landscape has experienced unprecedented growth and sophistication over the past decade, driven by advances in artificial intelligence, machine learning, and computational power. What was once the exclusive domain of institutional investors and hedge funds has become increasingly accessible to retail traders through specialized software platforms. This democratization has created a competitive marketplace where platforms differentiate themselves through unique approaches to strategy development, testing methodologies, and implementation capabilities.
This comprehensive analysis examines three prominent algorithmic trading platforms that represent different philosophies and target markets within the industry. Build Alpha positions itself as a technically sophisticated platform emphasizing robustness testing and overfitting prevention [1]. Composer focuses on user accessibility and democratizing institutional-grade trading strategies through a no-code interface [2]. StrategyQuant X offers comprehensive capabilities with advanced artificial intelligence integration and extensive platform compatibility [3].
The selection of these three platforms for comparison reflects their significant market presence, distinct technological approaches, and representation of different user segments within the algorithmic trading ecosystem. Each platform has garnered substantial user bases and professional recognition, making them representative examples of current industry standards and capabilities.
Methodology
This analysis employs a multi-dimensional evaluation framework designed to provide comprehensive insights into platform capabilities and market positioning. The research methodology incorporates both quantitative and qualitative assessment techniques to ensure thorough coverage of technical specifications, user experiences, and market dynamics.
Primary Research Sources: Direct examination of platform documentation, official feature specifications, user interfaces, and published technical capabilities formed the foundation of this analysis. Each platform’s official website, documentation repositories, and feature descriptions were systematically reviewed to establish baseline capabilities and positioning statements.
User Feedback Analysis: Extensive review of user testimonials, forum discussions, professional reviews, and independent assessments provided insights into real-world performance and user satisfaction. Sources included professional trading forums, Quora discussions, Reddit communities, and independent review platforms such as Wall Street Survivor and industry publications.
Technical Specification Review: Detailed examination of each platform’s technical capabilities, including supported asset classes, optimization algorithms, robustness testing methodologies, broker integrations, and code generation capabilities. This technical analysis focused on documented features and capabilities rather than subjective assessments.
Market Positioning Analysis: Evaluation of each platform’s target market, competitive positioning, pricing strategies, and market perception based on official communications, user feedback, and industry recognition. This analysis considered both current market position and strategic direction indicators.
Comparative Framework: The analysis employs five primary evaluation dimensions specifically chosen to address the most critical decision factors for algorithmic trading platform selection. These dimensions encompass technical capabilities, market applicability, advanced features, testing methodologies, and implementation practicalities.
The evaluation framework prioritizes objective assessment while acknowledging that platform selection ultimately depends on individual user requirements, expertise levels, and trading objectives. This approach ensures that the analysis provides actionable insights for different user types while maintaining analytical rigor and objectivity.
Platform Overview and Market Positioning
Build Alpha: Technical Excellence in Algorithmic Trading
Build Alpha represents a technically sophisticated approach to algorithmic trading platform design, emphasizing robustness testing, overfitting prevention, and strategy reliability [1]. Founded with the mission to provide professional-grade tools for systematic trading strategy development, Build Alpha has established itself as a preferred platform among quantitative analysts and professional traders who prioritize technical rigor and strategy validation.
The platform’s core philosophy centers on the principle that successful algorithmic trading requires not just strategy generation, but comprehensive validation and robustness testing to ensure strategies perform reliably in live market conditions. This approach addresses one of the most significant challenges in algorithmic trading: the gap between backtested performance and live trading results. Build Alpha’s emphasis on bridging this gap through advanced testing methodologies has earned it recognition among professional trading communities.
Build Alpha’s market positioning targets serious traders, quantitative analysts, and institutional users who require sophisticated tools for strategy development and validation. The platform’s user base consists primarily of experienced traders who appreciate technical depth and are willing to invest time in learning advanced features in exchange for superior strategy reliability. This positioning differentiates Build Alpha from more accessible platforms by focusing on technical excellence rather than ease of use.
The platform’s development approach emphasizes continuous innovation in robustness testing methodologies, with regular updates that incorporate the latest research in overfitting detection and strategy validation. Build Alpha’s commitment to technical advancement has resulted in a platform that offers unique capabilities not found in competing solutions, particularly in the areas of ensemble strategy testing and cross-validation techniques.
Composer represents a paradigm shift in algorithmic trading platform design, focusing on accessibility and user experience while maintaining professional-grade capabilities [2]. The platform’s mission centers on democratizing sophisticated trading strategies that were previously available only to institutional investors and hedge funds. Through its innovative no-code interface and emphasis on user-friendly design, Composer has successfully lowered the barriers to entry for algorithmic trading.
The platform’s approach to algorithmic trading emphasizes automation and simplicity without sacrificing sophistication. Composer’s “symphonies” concept allows users to create complex trading strategies through visual interfaces while providing access to proven strategies developed by professional investment committees. This dual approach serves both novice users seeking to implement existing strategies and experienced users who want to develop custom solutions.
Composer’s market positioning targets retail investors, financial advisors, and intermediate traders who desire professional-grade results without requiring extensive technical expertise. The platform’s regulatory compliance as a FINRA-registered investment advisor provides additional credibility and security for users concerned about platform reliability and fund safety. This regulatory positioning distinguishes Composer from many competitors that operate as software providers rather than registered investment advisors.
The platform’s growth strategy focuses on expanding its user base through superior user experience, educational resources, and proven strategy performance. Composer’s emphasis on transparency, with detailed backtesting results and performance metrics for all strategies, builds user confidence and supports informed decision-making. The platform’s success in attracting retail investors demonstrates the market demand for accessible yet sophisticated trading tools.
StrategyQuant X positions itself as the most comprehensive and technically advanced algorithmic trading platform available, offering extensive capabilities powered by artificial intelligence and machine learning technologies [3]. The platform’s development philosophy emphasizes providing users with institutional-grade tools and capabilities while maintaining flexibility for different trading styles and asset classes.
The platform’s comprehensive approach encompasses the entire algorithmic trading workflow, from strategy generation through optimization, testing, and implementation. StrategyQuant X’s integration of artificial intelligence and genetic programming algorithms enables automated strategy generation at scale, allowing users to explore vast strategy spaces efficiently. This technological approach addresses the challenge of strategy discovery by leveraging computational power to identify profitable trading patterns.
StrategyQuant X’s market positioning targets institutional users, educational institutions, professional traders, and advanced practitioners who require comprehensive capabilities and are willing to invest in learning complex tools. The platform’s adoption by universities for teaching algorithmic trading courses demonstrates its educational value and technical credibility. This institutional recognition supports StrategyQuant X’s positioning as an industry-leading solution.
The platform’s development strategy emphasizes continuous expansion of capabilities, with regular updates that add new features, improve existing functionality, and incorporate the latest advances in algorithmic trading research. StrategyQuant X’s comprehensive tool ecosystem, including QuantAnalyzer, QuantDataManager, and AlgoCloud, provides users with integrated solutions for all aspects of algorithmic trading operations.
Market Dynamics and Competitive Landscape
The algorithmic trading platform market exhibits clear segmentation based on user expertise, trading objectives, and feature requirements. This segmentation has enabled the three platforms to establish distinct market positions without direct head-to-head competition in all areas. Build Alpha dominates the technical sophistication segment, Composer leads in user accessibility and retail market penetration, and StrategyQuant X maintains leadership in comprehensive feature offerings and institutional adoption.
Market trends indicate increasing demand for platforms that combine sophisticated capabilities with improved user experiences. Users increasingly expect professional-grade results without requiring extensive technical expertise, driving innovation in user interface design and automation capabilities. This trend benefits all three platforms but particularly favors Composer’s accessibility-focused approach and StrategyQuant X’s automation capabilities.
The competitive landscape continues to evolve as platforms expand their capabilities and target new market segments. Build Alpha’s focus on robustness testing provides a sustainable competitive advantage as users become more sophisticated about overfitting risks. Composer’s regulatory compliance and user experience excellence position it well for continued retail market growth. StrategyQuant X’s comprehensive capabilities and institutional relationships support its position as the platform of choice for advanced users and educational institutions.
Comparative Reviews and Rankings
Professional and User Review Analysis
The evaluation of algorithmic trading platforms through professional reviews and user feedback provides critical insights into real-world performance, user satisfaction, and platform reliability. This analysis synthesizes feedback from multiple sources, including professional trading forums, independent review platforms, and user testimonials, to provide a comprehensive assessment of market perception and user experiences.
Build Alpha User Feedback and Professional Recognition
Build Alpha consistently receives high praise from professional users and technical experts, with particular emphasis on its robustness testing capabilities and strategy reliability. Chang Liu’s highly-rated Quora review, which received 96 upvotes, succinctly captures the professional consensus: “Build Alpha is much faster and much, much more flexible. Strategies are much more realistic and stable too. Dave’s support is amazing!” [4]. This testimonial highlights three key strengths that appear consistently across user reviews: speed, flexibility, and strategy reliability.
The Dream To Trade professional review provides detailed insights from a trader who uses both Build Alpha and StrategyQuant X in live trading environments [5]. The reviewer’s analysis reveals critical differences in platform reliability: “I have also not had any trouble reproducing the results with the Build Alpha generated code as I do at times with Strategyquant.” This observation addresses one of the most significant concerns in algorithmic trading—the ability to replicate backtested results in live trading environments.
The same professional review emphasizes Build Alpha’s superior robustness testing capabilities: “Build Alpha has a very advanced set of tools to identify overfitting and determine if a strategy is robust (will do well in live trading or not) compared to Strategyquant. Most of the robustness tests I have never heard of actually but are now a part of my process and extremely useful.” This feedback demonstrates Build Alpha’s technical leadership in addressing overfitting, one of the most critical challenges in algorithmic trading.
Elite Trader forum discussions consistently position Build Alpha as the more versatile option when compared to alternatives, with users noting: “Build Alpha is much more versatile and you have much more options to test different kind of strategies. I would go with Build Alpha” [6]. This versatility in testing options appears to be a significant differentiator that appeals to professional users who require comprehensive strategy validation.
StrategyQuant X User Feedback and Market Recognition
StrategyQuant X receives strong praise for its optimization capabilities and comprehensive feature set, with particular recognition from long-term users who report sustained profitability. Luca Castellucci’s Quora review, which garnered 93 upvotes, provides insights from a multi-year user: “I am using StrategyQuant. I have to say that the optimization module they have is really outstanding. And that makes big difference at the end. I am using the program for several years and Iam in black numbers…” [7]. This testimonial emphasizes both the platform’s optimization excellence and its ability to generate profitable results over extended periods.
The institutional recognition of StrategyQuant X through its adoption by universities for teaching algorithmic trading courses demonstrates its educational value and technical credibility [3]. This academic adoption indicates that the platform meets rigorous standards for educational use and provides comprehensive coverage of algorithmic trading concepts and methodologies.
Professional testimonials highlight significant returns achieved using StrategyQuant X, with users reporting 21% demo returns and 34% live returns [3]. While individual results vary and past performance does not guarantee future results, these testimonials indicate the platform’s potential for generating profitable strategies when used effectively.
However, the Dream To Trade review also identifies potential challenges with StrategyQuant X: “It seems to produce strategies that are great in the platform but when I export the code to my platform they seem to fall apart and are nothing like the backtests I created. The other issues I have had are the strategies are often curve fit or overfit and fail miserably in live trading” [5]. This feedback highlights the importance of robust testing and validation, areas where Build Alpha appears to excel.
Composer User Feedback and Professional Reviews
Composer receives consistently positive reviews for its user experience, accessibility, and proven strategy performance. The Wall Street Survivor professional review provides a comprehensive assessment: “Overall, Composer is definitely worth it if you are looking for an investment platform that allows you to simply implement cutting-edge strategies” [8]. This review emphasizes Composer’s success in making sophisticated strategies accessible to average investors.
The same professional review highlights Composer’s proven performance with specific examples: “The Hedgefundies Refined Symphony beat the S&P500 over the past decade, with a cumulative return of 1,647.9% versus the S&P’s 482.2%. That’s more then 3X the return, using a standard symphony created by Composer!” [8]. While past performance does not guarantee future results, this example demonstrates the platform’s ability to provide access to high-performing strategies.
Reddit community feedback emphasizes Composer’s accessibility and progression capabilities: “In my experience, Composer is a pretty robust solution that is newbie friendly and allows for in depth customization as one progresses in scope” [9]. This feedback indicates that Composer successfully serves both beginners and users who develop more sophisticated requirements over time.
Recent user feedback from TheAIReports highlights the platform’s practical benefits: “The platform is intuitive, and the ability to automate trades has saved me so much time” [10]. This emphasis on time savings and automation aligns with Composer’s positioning as a platform that democratizes sophisticated trading strategies.
Ranking Analysis by Key Criteria
Technical Sophistication and Robustness Testing
1.Build Alpha – Consistently rated highest for robustness testing capabilities and overfitting prevention
2.StrategyQuant X – Strong technical capabilities but with noted concerns about strategy translation
3.Composer – Excellent for accessibility but less emphasis on advanced technical testing
User Experience and Accessibility
1.Composer – Universally praised for intuitive interface and user-friendly design
2.StrategyQuant X – Comprehensive but complex, requiring significant learning investment
3.Build Alpha – Powerful but with steeper learning curve for non-technical users
Strategy Performance and Reliability
1.Build Alpha – Highest ratings for strategy reliability and live trading performance
2.Composer – Strong documented performance with proven strategies
3.StrategyQuant X – Mixed feedback on strategy translation from backtesting to live trading
Customer Support and Community
1.Build Alpha – Consistently praised for exceptional customer support from creator Dave
2.StrategyQuant X – Strong community and educational resources
3.Composer – Good support with emphasis on educational content and user guidance
Value for Money and Pricing
1.Composer – Rated as “fairly priced” at $30/month with strong value proposition
2.Build Alpha – Premium pricing justified by advanced capabilities and support
3.StrategyQuant X – Comprehensive features justify investment for serious users
Market Perception and Industry Recognition
The market perception analysis reveals distinct positioning and recognition patterns for each platform. Build Alpha has established itself as the technical leader among professional traders and quantitative analysts who prioritize strategy reliability and robustness testing. The platform’s reputation for exceptional customer support and technical excellence has created strong word-of-mouth recommendations within professional trading communities.
StrategyQuant X enjoys strong recognition in educational and institutional markets, with its adoption by universities and professional training programs demonstrating its comprehensive capabilities and educational value. The platform’s positioning as the most feature-rich solution appeals to users who require extensive capabilities and are willing to invest time in learning complex tools.
Composer has successfully penetrated the retail investment market through its focus on accessibility and user experience. The platform’s regulatory compliance as a FINRA-registered investment advisor provides additional credibility and appeals to users who prioritize security and regulatory oversight. Composer’s success in democratizing sophisticated trading strategies has earned recognition in mainstream financial media and retail investment communities.
The competitive dynamics indicate that each platform has successfully established distinct market positions without direct head-to-head competition across all segments. This market segmentation allows each platform to focus on its core strengths while serving different user needs and preferences within the broader algorithmic trading ecosystem.
Asset Class Applicability Analysis
Comprehensive Asset Class Coverage Comparison
The ability to develop and deploy trading strategies across multiple asset classes represents a critical capability for algorithmic trading platforms. This analysis examines each platform’s support for various asset classes, data integration capabilities, and limitations that may impact strategy development and deployment across different markets.
Build Alpha Asset Class Support
Build Alpha demonstrates comprehensive support for multiple asset classes with particular strength in futures and forex markets [1]. The platform’s asset class coverage includes equities, futures, options, forex, ETFs, and cryptocurrencies, providing users with broad market access for strategy development and testing. This comprehensive coverage enables users to develop diversified strategies and explore cross-asset arbitrage opportunities.
The platform’s futures trading capabilities are particularly robust, with support for major futures exchanges and comprehensive contract specifications. Build Alpha’s futures support includes automatic rollover handling, margin calculations, and position sizing adjustments that account for contract specifications and leverage requirements. This sophisticated futures handling addresses one of the most complex aspects of algorithmic trading across multiple asset classes.
Build Alpha’s forex capabilities support major and minor currency pairs with high-frequency data availability and spread modeling. The platform’s forex implementation includes realistic spread and commission modeling, which is crucial for developing strategies that perform reliably in live trading environments. The integration of economic calendar data and fundamental analysis tools enhances the platform’s forex trading capabilities.
For equity markets, Build Alpha provides comprehensive support for stock trading with advanced corporate action handling and dividend adjustments. The platform’s equity capabilities include support for different market segments, from large-cap stocks to small-cap and international markets. However, users have noted that data import for stocks can be challenging compared to other asset classes [5].
The platform’s options trading support includes basic options strategies and Greeks calculations, though this appears to be less developed compared to its futures and forex capabilities. Build Alpha’s cryptocurrency support enables trading of major digital assets, though the coverage may be more limited compared to specialized cryptocurrency platforms.
Composer Asset Class Support and Limitations
Composer’s asset class support is intentionally focused on stocks and ETFs, reflecting its positioning as a retail-oriented platform emphasizing simplicity and regulatory compliance [2]. This focused approach allows Composer to provide deep functionality within its supported asset classes while maintaining the user-friendly interface that defines the platform.
The platform’s stock coverage includes comprehensive support for US equities across all market capitalizations and sectors. Composer’s ETF support is particularly extensive, providing access to thousands of ETFs covering various asset classes, sectors, geographic regions, and investment strategies. This ETF-centric approach enables users to gain exposure to virtually any asset class or investment theme through ETF proxies.
Composer’s approach to asset class diversification through ETFs provides several advantages, including simplified trading mechanics, reduced complexity in strategy development, and automatic diversification within asset classes. Users can access commodities through commodity ETFs, international markets through international ETFs, and fixed income through bond ETFs, all within the platform’s unified interface.
However, Composer’s asset class limitations are significant for users requiring direct access to specific markets. The Wall Street Survivor review notes: “No mutual funds or cryptocurrencies. Some investors who want exposure to specific mutual funds or cryptocurrencies in their portfolio will be disappointed to find out that Composer only supports stocks and ETFs” [8]. This limitation restricts users who require direct cryptocurrency trading or specific mutual fund access.
The platform’s geographic limitation to US users further restricts its applicability for international traders or those requiring access to non-US markets directly. While international exposure is available through ETFs, this approach may not satisfy users requiring direct access to foreign exchanges or specific international securities.
StrategyQuant X Asset Class Support
StrategyQuant X provides the most comprehensive asset class support among the three platforms, with capabilities spanning equities, futures, options, forex, cryptocurrencies, and CFDs [3]. This extensive coverage reflects the platform’s positioning as a comprehensive solution for institutional and professional users who require broad market access.
The platform’s futures support is particularly sophisticated, with comprehensive coverage of global futures markets and advanced contract handling capabilities. StrategyQuant X’s futures implementation includes automatic rollover strategies, margin calculations, and sophisticated position sizing algorithms that account for contract specifications and risk management requirements.
StrategyQuant X’s forex capabilities support major, minor, and exotic currency pairs with high-frequency data processing and advanced spread modeling. The platform’s forex implementation includes sophisticated carry trade strategies, correlation analysis, and multi-timeframe analysis capabilities that enable complex forex strategy development.
The platform’s equity support encompasses global markets with comprehensive corporate action handling and dividend adjustments. StrategyQuant X’s equity capabilities include support for different market segments and geographic regions, enabling users to develop globally diversified strategies.
StrategyQuant X’s options support includes advanced options strategies, Greeks calculations, and volatility modeling. The platform’s options capabilities enable users to develop sophisticated options strategies including spreads, straddles, and complex multi-leg strategies. This advanced options support distinguishes StrategyQuant X from competitors that offer more basic options functionality.
The platform’s cryptocurrency support includes major digital assets with support for both spot and derivatives trading. StrategyQuant X’s cryptocurrency capabilities include correlation analysis with traditional assets and specialized indicators for digital asset markets.
Data Integration and Provider Support
Build Alpha Data Integration
Build Alpha supports multiple data providers and formats, enabling users to integrate various data sources for comprehensive strategy development [1]. The platform’s data integration capabilities include support for major data providers such as Interactive Brokers, eSignal, and various CSV formats for custom data import.
The platform’s data handling includes sophisticated cleaning and validation procedures that ensure data quality and consistency across different sources. Build Alpha’s data integration supports both historical and real-time data feeds, enabling users to develop strategies using historical data and deploy them with live data feeds.
Build Alpha’s economic calendar integration provides fundamental analysis capabilities that enhance strategy development for news-based and event-driven strategies. This integration enables users to incorporate economic events and announcements into their trading strategies.
Composer Data Integration
Composer’s data integration is streamlined and automated, reflecting its focus on user accessibility and simplicity [2]. The platform provides integrated data feeds for all supported securities, eliminating the need for users to manage data subscriptions or integration complexities.
The platform’s data coverage includes comprehensive historical data for backtesting and real-time data for live trading. Composer’s data integration includes automatic corporate action adjustments and dividend handling, ensuring strategy accuracy across different market events.
Composer’s approach to data integration prioritizes reliability and consistency over customization options. While this limits flexibility for users requiring specialized data sources, it ensures that all users have access to high-quality, consistent data without technical complexity.
StrategyQuant X Data Integration
StrategyQuant X provides the most flexible data integration capabilities, supporting numerous data providers and custom data formats [3]. The platform’s data integration includes support for major providers such as Interactive Brokers, MetaTrader, TradeStation, and various third-party data services.
The platform’s data handling capabilities include sophisticated data cleaning, validation, and synchronization procedures that ensure data quality across multiple sources and timeframes. StrategyQuant X’s data integration supports both tick-level and bar data, enabling users to develop strategies at various frequencies and granularities.
StrategyQuant X’s custom data import capabilities enable users to integrate proprietary data sources, alternative data, and specialized indicators. This flexibility supports advanced strategy development that incorporates unique data sources and analytical approaches.
Asset Class-Specific Limitations and Considerations
Each platform exhibits specific limitations and considerations that impact their applicability across different asset classes. Understanding these limitations is crucial for users who require specific asset class capabilities or have particular trading requirements.
Build Alpha’s stock data import challenges may impact users who require extensive equity strategy development, though the platform’s other asset class capabilities remain strong. The platform’s focus on robustness testing provides particular value for futures and forex strategies where overfitting risks are significant.
Composer’s limitation to stocks and ETFs restricts its applicability for users requiring direct access to other asset classes, though the ETF-based approach provides broad market exposure through simplified mechanisms. The platform’s regulatory compliance and user-friendly interface make it particularly suitable for retail investors focusing on equity and ETF strategies.
StrategyQuant X’s comprehensive asset class support comes with increased complexity that may overwhelm users who only require basic capabilities. The platform’s extensive features provide maximum flexibility but require significant learning investment to utilize effectively across all supported asset classes.
Ensemble Strategy Capabilities
Understanding Ensemble Strategies in Algorithmic Trading
Ensemble strategies represent one of the most sophisticated approaches to algorithmic trading, combining multiple individual strategies to create more robust and diversified trading systems. The ability to create, test, and deploy ensemble strategies distinguishes advanced trading platforms from basic strategy development tools. This analysis examines each platform’s capabilities for ensemble strategy development, including strategy combination methods, portfolio optimization, and meta-strategy approaches.
Build Alpha Ensemble Strategy Implementation
Build Alpha demonstrates exceptional capabilities in ensemble strategy development, with dedicated tools and methodologies specifically designed for multi-strategy portfolio construction [1]. The platform’s approach to ensemble strategies emphasizes statistical rigor and robustness testing, ensuring that strategy combinations provide genuine diversification benefits rather than merely aggregating correlated strategies.
The platform’s ensemble capabilities include sophisticated correlation analysis tools that help users identify strategies with low correlation coefficients, maximizing diversification benefits. Build Alpha’s correlation analysis extends beyond simple return correlations to include analysis of drawdown patterns, volatility characteristics, and market regime dependencies. This comprehensive correlation analysis enables users to construct ensembles that maintain performance across different market conditions.
Build Alpha’s ensemble testing capabilities include advanced statistical tests for strategy combination effectiveness. The platform provides tools for analyzing whether ensemble performance improvements are statistically significant or merely the result of random variation. These statistical validation tools address one of the most critical challenges in ensemble strategy development: distinguishing between genuine improvement and statistical noise.
The platform’s ensemble optimization capabilities include multiple combination methods, from simple equal-weight approaches to sophisticated optimization algorithms that consider risk-adjusted returns, maximum drawdown constraints, and volatility targets. Build Alpha’s optimization tools enable users to construct ensembles that meet specific risk and return objectives while maintaining diversification benefits.
Build Alpha’s ensemble robustness testing extends the platform’s individual strategy testing capabilities to multi-strategy portfolios. The platform’s ensemble testing includes walk-forward analysis, Monte Carlo simulation, and stress testing across different market regimes. This comprehensive testing ensures that ensemble strategies maintain their performance characteristics across various market conditions and time periods.
Composer Ensemble Strategy Approach
Composer’s approach to ensemble strategies focuses on accessibility and user-friendly implementation while maintaining sophisticated underlying capabilities [2]. The platform’s “symphonies” concept inherently supports ensemble-like approaches by enabling users to combine multiple assets and strategies within unified frameworks.
Composer’s ensemble capabilities are primarily implemented through its portfolio construction tools, which enable users to create strategies that automatically allocate capital across multiple assets based on various signals and conditions. While not explicitly labeled as ensemble strategies, these multi-asset symphonies function as ensemble approaches by combining different trading signals and asset exposures.
The platform’s strategy combination capabilities include conditional logic that enables users to create strategies that switch between different approaches based on market conditions or signal strength. This conditional approach enables ensemble-like behavior where different strategy components activate under different market regimes.
Composer’s community-driven approach provides access to proven ensemble-like strategies developed by professional investment committees and experienced users. The platform’s strategy sharing capabilities enable users to access sophisticated multi-strategy approaches without requiring deep technical expertise in ensemble development.
The platform’s backtesting capabilities extend to multi-asset strategies, enabling users to test ensemble-like approaches across historical data. While Composer’s ensemble capabilities may be less sophisticated than specialized platforms, the user-friendly implementation makes ensemble concepts accessible to retail investors who might otherwise lack the technical expertise to implement such strategies.
StrategyQuant X Ensemble Strategy Excellence
StrategyQuant X provides the most comprehensive ensemble strategy capabilities among the three platforms, with dedicated tools and advanced algorithms specifically designed for multi-strategy portfolio construction [3]. The platform’s Portfolio Composer feature represents a sophisticated approach to ensemble strategy development that rivals institutional-grade portfolio construction tools.
The Portfolio Composer enables users to combine multiple strategies using various weighting schemes, including equal weight, volatility-adjusted weight, performance-based weight, and custom optimization algorithms. This flexibility enables users to construct ensembles that meet specific risk and return objectives while accounting for individual strategy characteristics.
StrategyQuant X’s ensemble optimization capabilities include advanced algorithms that consider correlation structures, risk contributions, and performance stability when constructing multi-strategy portfolios. The platform’s optimization tools can handle large numbers of strategies while maintaining computational efficiency and providing meaningful results.
The platform’s ensemble testing capabilities include comprehensive walk-forward analysis, Monte Carlo simulation, and stress testing specifically designed for multi-strategy portfolios. StrategyQuant X’s ensemble testing extends beyond simple performance metrics to include analysis of strategy contribution, correlation stability, and regime-dependent performance.
StrategyQuant X’s machine learning integration enhances ensemble strategy development through automated strategy selection and weighting optimization. The platform’s AI capabilities can identify optimal strategy combinations from large strategy pools while avoiding overfitting and maintaining out-of-sample performance.
The platform’s ensemble deployment capabilities include sophisticated rebalancing algorithms that maintain optimal strategy weights while minimizing transaction costs and market impact. StrategyQuant X’s deployment tools consider practical implementation constraints while maintaining ensemble effectiveness.
Meta-Strategy and Machine Learning Integration
Build Alpha Meta-Strategy Capabilities
Build Alpha’s meta-strategy capabilities focus on statistical approaches to strategy combination and selection [1]. The platform provides tools for developing strategies that trade other strategies, enabling users to create meta-strategies that adapt to changing market conditions by adjusting strategy allocations.
The platform’s meta-strategy tools include regime detection algorithms that can identify market conditions favoring different strategy types. These regime detection capabilities enable meta-strategies to dynamically adjust strategy allocations based on market characteristics, improving overall portfolio performance.
Build Alpha’s statistical approach to meta-strategy development emphasizes robustness and statistical significance. The platform’s tools help users avoid overfitting in meta-strategy development by providing comprehensive testing and validation capabilities.
Composer Meta-Strategy Implementation
Composer’s meta-strategy capabilities are implemented through its conditional logic and market regime detection features [2]. The platform enables users to create strategies that adjust their behavior based on market conditions, volatility levels, or other market characteristics.
The platform’s approach to meta-strategies emphasizes simplicity and accessibility, enabling users to implement sophisticated concepts through user-friendly interfaces. Composer’s meta-strategy capabilities may be less advanced than specialized platforms but provide sufficient functionality for most retail investor requirements.
StrategyQuant X Advanced Meta-Strategy Tools
StrategyQuant X provides the most advanced meta-strategy capabilities, including machine learning algorithms that can automatically develop and optimize meta-strategies [3]. The platform’s AI integration enables sophisticated meta-strategy development that would be difficult or impossible to implement manually.
The platform’s meta-strategy tools include genetic programming algorithms that can evolve meta-strategies through iterative improvement processes. These evolutionary approaches enable the development of meta-strategies that adapt to changing market conditions while maintaining performance stability.
StrategyQuant X’s meta-strategy capabilities include ensemble learning approaches that combine multiple meta-strategies to create even more robust trading systems. This multi-level ensemble approach represents the cutting edge of algorithmic trading strategy development.
Practical Implementation and Deployment Considerations
The practical implementation of ensemble strategies requires consideration of various factors including computational requirements, data management, execution complexity, and monitoring capabilities. Each platform addresses these practical considerations differently, impacting their suitability for different user types and deployment scenarios.
Build Alpha’s ensemble implementation emphasizes reliability and robustness, with tools designed to ensure that ensemble strategies perform consistently in live trading environments. The platform’s focus on practical implementation considerations makes it particularly suitable for professional traders who require reliable ensemble deployment.
Composer’s ensemble implementation prioritizes simplicity and automation, enabling users to deploy ensemble-like strategies without requiring extensive technical expertise. The platform’s automated execution and monitoring capabilities make ensemble strategies accessible to retail investors.
StrategyQuant X’s ensemble implementation provides maximum flexibility and sophistication, enabling users to implement complex ensemble strategies with institutional-grade capabilities. The platform’s comprehensive tools support advanced ensemble deployment but require significant technical expertise to utilize effectively.
The choice between platforms for ensemble strategy development depends on user requirements for sophistication, ease of use, and deployment capabilities. Build Alpha excels in robustness and reliability, Composer provides accessibility and automation, and StrategyQuant X offers maximum sophistication and flexibility.
Walk-Forward Testing and Robust Optimization
The Critical Importance of Robustness Testing
Walk-forward testing and robust optimization represent the most critical capabilities for ensuring that algorithmic trading strategies perform reliably in live market conditions. The gap between backtested performance and live trading results represents one of the most significant challenges in algorithmic trading, often attributed to overfitting, data mining bias, and inadequate validation methodologies. This analysis examines each platform’s capabilities for addressing these challenges through comprehensive testing and optimization frameworks.
Build Alpha: Industry Leadership in Robustness Testing
Build Alpha has established itself as the industry leader in robustness testing and overfitting prevention, with comprehensive tools and methodologies that address the most sophisticated challenges in strategy validation [1]. The platform’s approach to robustness testing reflects deep understanding of statistical principles and practical trading challenges, resulting in tools that provide genuine insights into strategy reliability.
The platform’s walk-forward testing capabilities include multiple validation approaches designed to simulate realistic trading conditions. Build Alpha’s walk-forward analysis includes rolling window optimization, expanding window analysis, and anchored walk-forward testing. Each approach provides different insights into strategy stability and parameter sensitivity, enabling users to comprehensively evaluate strategy robustness.
Build Alpha’s out-of-sample testing methodology extends beyond simple data holdout to include sophisticated cross-validation techniques. The platform’s cross-validation tools include k-fold validation, time series cross-validation, and blocked cross-validation approaches that account for temporal dependencies in financial data. These advanced cross-validation techniques provide more reliable estimates of out-of-sample performance than traditional holdout methods.
The platform’s Monte Carlo simulation capabilities enable comprehensive stress testing of strategies across thousands of simulated market scenarios. Build Alpha’s Monte Carlo tools include bootstrap resampling, parametric simulation, and scenario-based testing that evaluate strategy performance under various market conditions. These simulation capabilities help users understand strategy behavior under extreme market conditions and assess worst-case scenario risks.
Build Alpha’s overfitting detection tools include sophisticated statistical tests designed to identify strategies that are unlikely to perform well in live trading. The platform’s overfitting detection includes White’s Reality Check, Hansen’s Superior Predictive Ability test, and custom statistical tests developed specifically for trading strategy validation. These statistical tests provide objective measures of strategy reliability that go beyond simple performance metrics.
The platform’s parameter robustness testing includes comprehensive sensitivity analysis that evaluates strategy performance across parameter ranges. Build Alpha’s sensitivity analysis tools help users identify parameters that significantly impact strategy performance and assess whether optimal parameters are stable across different time periods and market conditions.
Build Alpha’s data mining bias correction tools address one of the most subtle but important challenges in strategy development. The platform’s bias correction tools include multiple testing adjustments, false discovery rate control, and other statistical techniques that account for the multiple comparisons inherent in strategy development processes.
Composer: Accessible Robustness Testing
Composer’s approach to robustness testing emphasizes accessibility and user-friendly implementation while maintaining statistical rigor [2]. The platform’s robustness testing capabilities are designed to provide retail investors with institutional-grade validation tools without requiring extensive statistical expertise.
Composer’s backtesting framework includes comprehensive out-of-sample testing that automatically reserves portions of historical data for validation purposes. The platform’s out-of-sample testing is implemented transparently, ensuring that users cannot inadvertently use future data in strategy development. This automatic out-of-sample testing helps prevent overfitting without requiring users to understand complex validation methodologies.
The platform’s walk-forward testing capabilities include rolling optimization and performance evaluation across multiple time periods. Composer’s walk-forward testing is implemented through user-friendly interfaces that make sophisticated testing accessible to non-technical users. The platform automatically handles the technical complexities of walk-forward testing while providing clear performance metrics and visualizations.
Composer’s robustness testing includes stress testing across different market regimes and volatility environments. The platform’s stress testing capabilities evaluate strategy performance during market crashes, high volatility periods, and other challenging market conditions. These stress tests help users understand strategy behavior under adverse conditions and assess risk management effectiveness.
The platform’s parameter stability testing evaluates strategy performance across different parameter settings and time periods. Composer’s parameter testing helps users identify robust parameter ranges and avoid overfitted parameter selections. The platform presents parameter testing results through intuitive visualizations that make complex statistical concepts accessible to retail investors.
Composer’s approach to overfitting prevention includes educational resources and best practices guidance that help users develop robust strategies. The platform’s educational content covers common overfitting pitfalls and provides practical guidance for avoiding these issues. This educational approach complements the platform’s technical tools by helping users understand the principles behind robust strategy development.
StrategyQuant X: Comprehensive Optimization and Testing Framework
StrategyQuant X provides comprehensive robustness testing and optimization capabilities that rival institutional-grade tools [3]. The platform’s approach to robustness testing combines advanced statistical techniques with practical trading considerations, resulting in tools that address both theoretical and practical aspects of strategy validation.
The platform’s walk-forward testing capabilities include multiple optimization approaches designed to evaluate strategy stability across different time periods and market conditions. StrategyQuant X’s walk-forward testing includes rolling optimization, expanding window analysis, and custom validation schemes that can be tailored to specific strategy requirements.
StrategyQuant X’s out-of-sample testing methodology includes sophisticated cross-validation techniques that account for the temporal structure of financial data. The platform’s cross-validation tools include time series cross-validation, blocked cross-validation, and custom validation schemes that provide reliable estimates of out-of-sample performance.
The platform’s Monte Carlo simulation capabilities enable comprehensive stress testing and scenario analysis. StrategyQuant X’s Monte Carlo tools include bootstrap resampling, parametric simulation, and custom scenario generation that evaluate strategy performance under various market conditions. These simulation capabilities provide insights into strategy behavior under extreme market conditions and help assess tail risk.
StrategyQuant X’s optimization capabilities include advanced algorithms designed to find robust parameter settings while avoiding overfitting. The platform’s optimization tools include genetic algorithms, particle swarm optimization, and custom optimization schemes that can handle complex parameter spaces while maintaining statistical rigor.
The platform’s overfitting protection includes multiple statistical tests and validation techniques designed to identify unreliable strategies. StrategyQuant X’s overfitting protection includes White’s Reality Check, multiple testing corrections, and custom statistical tests that provide objective measures of strategy reliability.
StrategyQuant X’s parameter robustness testing includes comprehensive sensitivity analysis and stability testing across different time periods and market conditions. The platform’s robustness testing tools help users identify stable parameter ranges and assess parameter sensitivity across different market regimes.
Advanced Statistical Techniques and Methodologies
Build Alpha Statistical Innovation
Build Alpha’s statistical approach to robustness testing includes cutting-edge techniques that address the most sophisticated challenges in strategy validation [1]. The platform’s statistical tools include advanced techniques that are not commonly available in other trading platforms, reflecting the platform’s commitment to statistical rigor and innovation.
The platform’s statistical tests include sophisticated approaches to multiple testing correction that account for the numerous comparisons inherent in strategy development. Build Alpha’s multiple testing corrections include Bonferroni correction, false discovery rate control, and custom approaches designed specifically for trading strategy validation.
Build Alpha’s bootstrap techniques include advanced resampling methods that preserve the temporal structure of financial data while providing robust estimates of strategy performance. The platform’s bootstrap tools include block bootstrap, stationary bootstrap, and custom resampling schemes that account for the unique characteristics of financial time series.
Composer Statistical Accessibility
Composer’s statistical approach emphasizes making sophisticated techniques accessible to non-technical users [2]. The platform’s statistical tools are implemented through user-friendly interfaces that hide technical complexity while maintaining statistical rigor.
The platform’s statistical validation includes automated tests that evaluate strategy reliability without requiring users to understand complex statistical concepts. Composer’s automated validation provides clear guidance on strategy reliability and helps users avoid common overfitting pitfalls.
StrategyQuant X Statistical Comprehensiveness
StrategyQuant X provides the most comprehensive statistical testing capabilities, including advanced techniques that address sophisticated validation challenges [3]. The platform’s statistical tools include cutting-edge approaches that reflect the latest research in quantitative finance and statistical validation.
The platform’s statistical tests include sophisticated approaches to regime detection and stability testing that evaluate strategy performance across different market conditions. StrategyQuant X’s regime testing tools help users understand how strategies perform under different market environments and assess regime-dependent risks.
Practical Implementation and Real-World Validation
The practical implementation of robustness testing requires consideration of computational requirements, data quality, and real-world trading constraints. Each platform addresses these practical considerations differently, impacting their effectiveness for different user types and trading scenarios.
Build Alpha’s practical approach to robustness testing emphasizes reliability and real-world applicability. The platform’s tools are designed to provide insights that translate directly to live trading performance, with validation techniques that account for practical trading constraints and market microstructure effects.
Composer’s practical approach emphasizes automation and user-friendly implementation. The platform’s robustness testing is designed to provide reliable validation without requiring extensive technical expertise or manual intervention. This automated approach makes sophisticated validation accessible to retail investors who lack technical expertise.
StrategyQuant X’s practical approach provides maximum flexibility and sophistication. The platform’s robustness testing tools can be customized to address specific validation requirements and trading constraints. This flexibility enables advanced users to implement sophisticated validation schemes but requires significant technical expertise to utilize effectively.
The effectiveness of robustness testing ultimately depends on proper implementation and interpretation of results. All three platforms provide tools for comprehensive strategy validation, but their effectiveness depends on user understanding of statistical principles and proper application of testing methodologies.
Strategy Implementation and Broker Connectivity
The Critical Bridge from Development to Deployment
The transition from strategy development to live trading represents one of the most critical phases in algorithmic trading, where theoretical performance must translate into practical results. The effectiveness of this transition depends heavily on platform capabilities for broker integration, code generation, execution management, and real-time monitoring. This analysis examines each platform’s approach to strategy implementation and their capabilities for seamless deployment across different trading environments.
Build Alpha demonstrates exceptional capabilities in strategy implementation and broker connectivity, with particular strength in code generation reliability and platform compatibility [1]. The platform’s approach to implementation emphasizes accuracy, reliability, and seamless translation from backtested strategies to live trading systems.
Build Alpha’s broker connectivity includes comprehensive support for major trading platforms and brokers. The platform provides native integrations with Interactive Brokers, TradeStation, MultiCharts, and other professional trading platforms. These integrations enable direct strategy deployment without requiring manual code translation or complex setup procedures.
The platform’s code generation capabilities represent a significant competitive advantage, with users consistently reporting reliable translation from platform strategies to live trading code. The Dream To Trade professional review specifically highlights this strength: “I have also not had any trouble reproducing the results with the Build Alpha generated code as I do at times with Strategyquant” [5]. This reliability in code generation addresses one of the most critical challenges in algorithmic trading implementation.
Build Alpha’s code generation supports multiple programming languages and platforms, including EasyLanguage for TradeStation, MQL4/MQL5 for MetaTrader, and custom formats for other platforms. The platform’s code generation includes comprehensive comments and documentation that facilitate understanding and modification of generated code.
The platform’s implementation tools include sophisticated order management capabilities that handle complex order types, position sizing, and risk management rules. Build Alpha’s order management tools account for practical trading constraints including slippage, commissions, and market impact, ensuring that live trading performance closely matches backtested results.
Build Alpha’s real-time monitoring capabilities enable users to track strategy performance and identify potential issues during live trading. The platform’s monitoring tools include performance tracking, drawdown alerts, and automated reporting that help users maintain oversight of deployed strategies.
The platform’s risk management integration includes comprehensive tools for position sizing, stop-loss management, and portfolio-level risk controls. Build Alpha’s risk management tools can be customized to meet specific risk requirements and regulatory constraints, making the platform suitable for professional and institutional deployment.
Composer: Streamlined Automated Execution
Composer’s approach to strategy implementation emphasizes automation and simplicity, with integrated execution capabilities that eliminate the need for external broker connections or code generation [2]. The platform’s implementation model provides a seamless experience from strategy development to live trading through its integrated brokerage partnership.
Composer’s execution model operates through its partnership with Alpaca Securities, providing users with direct access to US equity and ETF markets without requiring separate broker accounts or complex setup procedures. This integrated approach eliminates many of the technical challenges associated with strategy implementation while ensuring regulatory compliance and fund security.
The platform’s automated execution capabilities include sophisticated order management that handles fractional shares, automatic rebalancing, and tax-efficient trading. Composer’s execution system automatically optimizes trade timing and sizing to minimize market impact and transaction costs while maintaining strategy integrity.
Composer’s real-time portfolio management includes automatic monitoring and adjustment capabilities that ensure strategies continue to operate according to their specifications. The platform’s monitoring system includes performance tracking, risk monitoring, and automated alerts that keep users informed of strategy performance and any issues that may arise.
The platform’s regulatory compliance includes FINRA registration and SIPC protection, providing users with institutional-grade security and regulatory oversight. Composer’s regulatory compliance addresses concerns about platform reliability and fund safety that may arise with less regulated alternatives.
Composer’s implementation approach includes comprehensive reporting and tax optimization features that simplify the administrative aspects of algorithmic trading. The platform’s reporting tools include performance attribution, tax-loss harvesting, and comprehensive statements that facilitate tax preparation and performance analysis.
The platform’s user interface provides comprehensive control over strategy deployment, including the ability to pause strategies, adjust position sizes, and modify risk parameters without requiring technical expertise. This user-friendly approach to strategy management makes sophisticated trading strategies accessible to retail investors.
StrategyQuant X provides the most comprehensive strategy implementation capabilities, with support for numerous trading platforms and extensive customization options [3]. The platform’s approach to implementation emphasizes flexibility and compatibility, enabling users to deploy strategies across virtually any trading environment.
StrategyQuant X’s broker connectivity includes support for major trading platforms including MetaTrader 4/5, TradeStation, MultiCharts, NinjaTrader, and numerous other platforms. The platform’s extensive compatibility enables users to deploy strategies on their preferred trading platforms without being constrained by platform limitations.
The platform’s code generation capabilities include support for multiple programming languages and trading platforms. StrategyQuant X can generate EasyLanguage code for TradeStation, MQL4/MQL5 for MetaTrader, C# for NinjaTrader, and other formats as required. This comprehensive code generation capability provides maximum flexibility for strategy deployment.
StrategyQuant X’s implementation tools include sophisticated order management and execution optimization capabilities. The platform’s execution tools can handle complex order types, advanced position sizing algorithms, and sophisticated risk management rules. These capabilities enable users to implement institutional-grade execution strategies.
The platform’s real-time connectivity includes support for live data feeds and real-time strategy monitoring. StrategyQuant X’s real-time capabilities enable users to monitor strategy performance, track market conditions, and make real-time adjustments to deployed strategies.
StrategyQuant X’s portfolio management capabilities include comprehensive tools for multi-strategy deployment and portfolio-level risk management. The platform’s portfolio tools enable users to deploy multiple strategies simultaneously while maintaining overall portfolio risk controls and performance monitoring.
The platform’s API capabilities enable custom integrations and automated deployment workflows. StrategyQuant X’s API support enables advanced users to create custom deployment solutions and integrate the platform with existing trading infrastructure.
Code Generation Quality and Reliability
Build Alpha Code Generation Excellence
Build Alpha’s code generation capabilities represent a significant competitive advantage, with consistent user feedback highlighting the reliability and accuracy of generated code [1]. The platform’s code generation process includes comprehensive testing and validation to ensure that generated code accurately reflects backtested strategy logic.
The platform’s code generation includes sophisticated handling of complex trading logic, including multi-timeframe analysis, complex entry and exit conditions, and advanced risk management rules. Build Alpha’s code generation maintains the integrity of complex strategy logic while producing readable and maintainable code.
Build Alpha’s generated code includes comprehensive documentation and comments that facilitate understanding and modification. The platform’s documentation approach enables users to understand generated code and make necessary modifications for specific deployment requirements.
Composer Integrated Execution Model
Composer’s approach to strategy implementation eliminates the need for code generation by providing integrated execution capabilities [2]. This approach ensures perfect fidelity between strategy development and live execution while eliminating the potential for translation errors.
The platform’s integrated execution model includes sophisticated order management and optimization that handles the complexities of live trading without requiring user intervention. Composer’s execution system automatically handles fractional shares, tax optimization, and other practical considerations that can complicate manual implementation.
StrategyQuant X Comprehensive Code Generation
StrategyQuant X provides extensive code generation capabilities with support for numerous platforms and programming languages [3]. The platform’s code generation includes sophisticated optimization and customization options that enable users to tailor generated code to specific requirements.
However, some users have reported challenges with code translation reliability, as noted in the Dream To Trade review: “It seems to produce strategies that are great in the platform but when I export the code to my platform they seem to fall apart and are nothing like the backtests I created” [5]. This feedback suggests that while StrategyQuant X provides extensive code generation capabilities, users may need to invest additional effort in validation and testing.
Execution Management and Order Handling
The quality of execution management and order handling capabilities significantly impacts the success of strategy implementation. Each platform approaches execution management differently, with varying levels of sophistication and automation.
Build Alpha’s execution management emphasizes accuracy and reliability, with tools designed to ensure that live trading closely matches backtested performance. The platform’s execution tools include sophisticated slippage modeling, commission handling, and market impact estimation that provide realistic execution simulation.
Composer’s execution management is fully automated and integrated, providing users with institutional-grade execution capabilities without requiring technical expertise. The platform’s execution system includes sophisticated optimization algorithms that minimize transaction costs and market impact while maintaining strategy integrity.
StrategyQuant X’s execution management provides maximum flexibility and customization, enabling users to implement sophisticated execution strategies tailored to specific requirements. The platform’s execution tools include advanced order types, execution algorithms, and risk management capabilities that support institutional-grade deployment.
Real-Time Monitoring and Risk Management
Effective real-time monitoring and risk management capabilities are essential for successful strategy deployment. Each platform provides different approaches to monitoring and risk management, with varying levels of automation and sophistication.
Build Alpha’s monitoring capabilities include comprehensive performance tracking, risk monitoring, and automated alerting that help users maintain oversight of deployed strategies. The platform’s monitoring tools provide detailed insights into strategy performance and help users identify potential issues before they impact performance.
Composer’s monitoring capabilities are fully integrated and automated, providing users with comprehensive oversight without requiring active management. The platform’s monitoring system includes automatic risk management, performance tracking, and user notifications that ensure strategies continue to operate effectively.
StrategyQuant X’s monitoring capabilities provide maximum flexibility and customization, enabling users to implement sophisticated monitoring and risk management systems tailored to specific requirements. The platform’s monitoring tools include advanced analytics, custom alerts, and comprehensive reporting capabilities.
The effectiveness of strategy implementation ultimately depends on the quality of platform tools and user expertise in deployment and monitoring. All three platforms provide capable implementation tools, but their effectiveness varies based on user requirements and technical expertise.
• Limited to US users only<br>• Stocks and ETFs only<br>• No direct crypto/forex<br>• Less advanced testing<br>• Newer platform<br>• Limited customization
StrategyQuant X
• Most comprehensive features<br>• Advanced AI integration<br>• Extensive platform support<br>• Strong institutional adoption<br>• Global availability<br>• Educational credibility
• Very steep learning curve<br>• Code translation issues<br>• Complexity overwhelming<br>• Overfitting concerns<br>• High technical requirements<br>• Mixed reliability reports
Recommendation Scoring Matrix
User Type
Build Alpha Score
Composer Score
StrategyQuant X Score
Retail Trader
6/10
9/10
4/10
Professional Trader
9/10
6/10
8/10
Quant Developer
10/10
5/10
9/10
Fund Researcher
9/10
7/10
10/10
Prop Trading Desk
9/10
6/10
9/10
Educational Institution
7/10
8/10
10/10
Beginner
4/10
10/10
3/10
Intermediate
8/10
8/10
7/10
Advanced
10/10
6/10
9/10
Scoring based on: 1-3 (Poor fit), 4-6 (Moderate fit), 7-8 (Good fit), 9-10 (Excellent fit)
Recommendation Matrix
User Type-Specific Platform Recommendations
The selection of an optimal algorithmic trading platform depends heavily on user characteristics, including technical expertise, trading objectives, asset class preferences, and implementation requirements. This recommendation matrix provides specific guidance for different user types based on the comprehensive analysis of platform capabilities and market positioning.
Retail Trader Recommendations
For retail traders seeking to implement algorithmic trading strategies without extensive technical expertise, Composer emerges as the clear optimal choice. The platform’s exceptional user experience, regulatory compliance, and proven strategy performance make it ideally suited for retail investors who want professional-grade results through accessible interfaces.
Composer’s strengths for retail traders include its no-code approach to strategy development, integrated execution capabilities, and comprehensive educational resources. The platform’s FINRA registration provides regulatory security that appeals to retail investors concerned about platform reliability and fund safety. The automated execution model eliminates the technical complexities of broker integration and code generation that can overwhelm retail users.
The platform’s limitation to stocks and ETFs may actually benefit retail traders by providing focused functionality without overwhelming complexity. The ETF-based approach to asset class diversification enables retail traders to access broad market exposure through simplified mechanisms while maintaining sophisticated strategy capabilities.
Recommendation: Composer (Score: 9/10)
•Primary choice for user-friendly algorithmic trading
•Ideal for investors seeking proven strategies with minimal technical complexity
•Best option for US-based retail investors focused on equity markets
Professional Trader Recommendations
Professional traders require sophisticated tools that prioritize strategy reliability, robustness testing, and flexible implementation options. Build Alpha represents the optimal choice for professional traders who value technical excellence and are willing to invest in learning advanced capabilities.
Build Alpha’s industry-leading robustness testing capabilities address the most critical challenges faced by professional traders: ensuring that backtested strategies perform reliably in live trading environments. The platform’s exceptional code generation reliability and comprehensive validation tools provide professional traders with confidence in strategy deployment across multiple platforms and brokers.
The platform’s sophisticated ensemble strategy capabilities and advanced statistical testing tools enable professional traders to develop and validate complex multi-strategy portfolios. Build Alpha’s exceptional customer support provides professional traders with direct access to technical expertise when needed.
Recommendation: Build Alpha (Score: 9/10)
•Primary choice for traders prioritizing strategy reliability and robustness
•Ideal for professionals requiring sophisticated validation and testing capabilities
•Best option for traders deploying strategies across multiple platforms
Quantitative Developer Recommendations
Quantitative developers require platforms that provide maximum technical sophistication, advanced testing capabilities, and flexible implementation options. Build Alpha represents the optimal choice for quantitative developers who prioritize technical excellence and statistical rigor in strategy development.
Build Alpha’s advanced robustness testing capabilities, including sophisticated statistical tests and overfitting detection tools, provide quantitative developers with institutional-grade validation capabilities. The platform’s exceptional code generation reliability ensures that complex strategy logic translates accurately to live trading implementations.
The platform’s focus on statistical innovation and continuous development of advanced testing methodologies appeals to quantitative developers who require cutting-edge capabilities. Build Alpha’s technical depth and flexibility enable quantitative developers to implement sophisticated validation schemes and custom testing approaches.
Recommendation: Build Alpha (Score: 10/10)
•Primary choice for maximum technical sophistication and statistical rigor
•Ideal for developers requiring advanced validation and testing capabilities
•Best option for implementing cutting-edge quantitative trading approaches
Fund Researcher Recommendations
Fund researchers require comprehensive capabilities for strategy research, institutional-grade tools, and extensive asset class coverage. StrategyQuant X represents the optimal choice for fund researchers who need maximum functionality and institutional credibility.
StrategyQuant X’s comprehensive feature set, including advanced AI integration and extensive platform compatibility, provides fund researchers with institutional-grade capabilities for strategy research and development. The platform’s strong institutional adoption and educational credibility support its use in professional research environments.
The platform’s extensive asset class coverage and sophisticated portfolio construction tools enable fund researchers to explore diverse strategy approaches across multiple markets and asset classes. StrategyQuant X’s advanced optimization and testing capabilities support comprehensive research initiatives.
Recommendation: StrategyQuant X (Score: 10/10)
•Primary choice for comprehensive institutional-grade capabilities
•Ideal for researchers requiring extensive asset class coverage and advanced tools
•Best option for institutional research and educational applications
Prop Trading Desk Recommendations
Proprietary trading desks require platforms that combine technical sophistication with reliable implementation capabilities and flexible deployment options. Both Build Alpha and StrategyQuant X represent viable choices depending on specific desk requirements and priorities.
Build Alpha is recommended for prop desks that prioritize strategy reliability and robustness testing. The platform’s exceptional validation capabilities and code generation reliability make it ideal for desks that require high confidence in strategy deployment. Build Alpha’s focus on overfitting prevention and statistical rigor appeals to prop desks that emphasize risk management and strategy validation.
StrategyQuant X is recommended for prop desks that require comprehensive capabilities and extensive asset class coverage. The platform’s advanced features and institutional-grade tools support sophisticated trading operations across multiple markets and strategies.
Recommendation: Build Alpha (Score: 9/10) or StrategyQuant X (Score: 9/10)
•Build Alpha for desks prioritizing reliability and robustness testing
•StrategyQuant X for desks requiring comprehensive capabilities and asset class coverage
•Choice depends on specific desk priorities and technical requirements
Educational Institution Recommendations
Educational institutions require platforms that provide comprehensive learning opportunities, institutional credibility, and extensive documentation. StrategyQuant X represents the optimal choice for educational institutions due to its comprehensive capabilities and strong educational adoption.
StrategyQuant X’s extensive feature set provides students with exposure to institutional-grade tools and comprehensive algorithmic trading concepts. The platform’s strong adoption by universities demonstrates its educational value and provides institutional credibility for academic programs.
The platform’s comprehensive documentation and learning resources support educational objectives while providing students with practical experience using professional-grade tools. StrategyQuant X’s global availability enables international educational programs.
Recommendation: StrategyQuant X (Score: 10/10)
•Primary choice for comprehensive educational coverage
•Ideal for institutions requiring institutional-grade tools and credibility
•Best option for international educational programs
Beginner Recommendations
Beginners require platforms that prioritize accessibility, educational support, and user-friendly interfaces while providing growth opportunities as skills develop. Composer represents the optimal choice for beginners due to its exceptional user experience and educational approach.
Composer’s no-code interface and intuitive design make algorithmic trading accessible to beginners without requiring extensive technical expertise. The platform’s educational resources and best practices guidance help beginners understand algorithmic trading concepts while avoiding common pitfalls.
The platform’s proven strategies and automated execution provide beginners with access to sophisticated trading approaches without requiring deep technical knowledge. Composer’s regulatory compliance provides security and confidence for beginners concerned about platform reliability.
Recommendation: Composer (Score: 10/10)
•Primary choice for maximum accessibility and user-friendliness
•Ideal for beginners seeking proven strategies with minimal complexity
•Best option for learning algorithmic trading concepts through practical application
Intermediate User Recommendations
Intermediate users require platforms that provide growth opportunities while maintaining accessibility and offering advanced features as skills develop. Both Composer and Build Alpha represent viable choices depending on user priorities and development direction.
Composer is recommended for intermediate users who prioritize accessibility and proven performance while gradually developing more sophisticated requirements. The platform’s progression capabilities enable users to advance from basic strategy implementation to more complex custom development.
Build Alpha is recommended for intermediate users who are ready to invest in learning advanced capabilities and prioritize technical sophistication. The platform’s exceptional validation tools and technical depth provide intermediate users with professional-grade capabilities as they develop expertise.
Recommendation: Composer (Score: 8/10) or Build Alpha (Score: 8/10)
•Composer for users prioritizing accessibility with growth potential
•Build Alpha for users ready to invest in advanced technical capabilities
•Choice depends on learning preferences and technical comfort level
Advanced User Recommendations
Advanced users require platforms that provide maximum technical sophistication, advanced capabilities, and flexible implementation options. Build Alpha represents the optimal choice for advanced users who prioritize technical excellence and statistical rigor.
Build Alpha’s industry-leading robustness testing capabilities and exceptional validation tools provide advanced users with institutional-grade capabilities for sophisticated strategy development. The platform’s technical depth and statistical innovation appeal to advanced users who require cutting-edge capabilities.
The platform’s exceptional code generation reliability and flexible implementation options enable advanced users to deploy sophisticated strategies across multiple platforms and brokers with confidence in strategy translation accuracy.
Recommendation: Build Alpha (Score: 10/10)
•Primary choice for maximum technical sophistication and validation capabilities
•Ideal for advanced users requiring institutional-grade tools and statistical rigor
•Best option for sophisticated strategy development and deployment
Decision Framework and Selection Criteria
The platform selection process should consider multiple factors beyond basic feature comparisons. This decision framework provides structured guidance for evaluating platforms based on specific requirements and priorities.
Primary Selection Criteria:
1.Technical Expertise Level: Assess current technical capabilities and willingness to invest in learning advanced features
2.Asset Class Requirements: Determine specific asset class needs and geographic market access requirements
3.Implementation Preferences: Evaluate preferences for integrated execution versus external platform deployment
4.Validation Requirements: Assess needs for advanced robustness testing and statistical validation
5.Budget Considerations: Consider pricing models and value propositions relative to expected benefits
6.Regulatory Requirements: Evaluate needs for regulatory compliance and fund security
7.Support Requirements: Assess needs for customer support, educational resources, and community engagement
Secondary Selection Criteria:
1.Growth Potential: Consider platform capabilities for supporting skill development and expanding requirements
2.Integration Needs: Evaluate requirements for integration with existing tools and workflows
3.Customization Requirements: Assess needs for platform customization and advanced configuration options
4.Performance Requirements: Consider computational requirements and platform performance characteristics
5.Community and Ecosystem: Evaluate importance of user community, strategy sharing, and ecosystem development
Implementation Recommendations
Successful platform implementation requires careful planning and systematic approach to learning and deployment. These implementation recommendations provide guidance for maximizing platform effectiveness regardless of chosen solution.
Phase 1: Learning and Familiarization
•Invest adequate time in platform learning and skill development
•Utilize educational resources and documentation comprehensively
•Start with simple strategies before advancing to complex implementations
•Engage with user communities and support resources
Phase 2: Strategy Development and Testing
•Implement comprehensive backtesting and validation procedures
•Focus on out-of-sample testing and overfitting prevention
•Document strategy development processes and results
Phase 3: Deployment and Monitoring
•Start with small position sizes and gradual scaling
•Implement comprehensive monitoring and risk management procedures
•Maintain detailed records of live trading performance
•Continuously compare live results with backtested expectations
Phase 4: Optimization and Scaling
•Analyze performance results and identify improvement opportunities
•Expand strategy portfolios and asset class coverage gradually
•Implement advanced features and capabilities as expertise develops
•Consider platform migration or supplementation as requirements evolve
The success of algorithmic trading implementation depends more on proper methodology and risk management than on platform selection alone. While platform capabilities provide important tools and advantages, user expertise and disciplined implementation remain the most critical success factors.
Conclusion and Future Outlook
Synthesis of Key Findings
This comprehensive analysis of Build Alpha, Composer, and StrategyQuant X reveals a mature and differentiated algorithmic trading platform ecosystem where each solution has established distinct competitive advantages and market positioning. The three platforms represent different philosophies and approaches to algorithmic trading, creating clear value propositions for different user segments without direct head-to-head competition across all dimensions.
Build Alpha has established itself as the technical leader in robustness testing and strategy validation, with industry-leading capabilities for overfitting prevention and statistical rigor. The platform’s exceptional code generation reliability and outstanding customer support create strong value propositions for professional traders and quantitative developers who prioritize strategy reliability above all other considerations. Build Alpha’s focus on technical excellence and statistical innovation positions it as the platform of choice for users who require maximum confidence in strategy validation and deployment.
Composer has successfully democratized sophisticated algorithmic trading through exceptional user experience design and regulatory compliance. The platform’s no-code approach and integrated execution model make institutional-grade trading strategies accessible to retail investors without requiring extensive technical expertise. Composer’s proven strategy performance and FINRA registration provide retail investors with both accessibility and security, creating a unique value proposition in the retail algorithmic trading market.
StrategyQuant X provides the most comprehensive feature set and institutional-grade capabilities, with advanced artificial intelligence integration and extensive platform compatibility. The platform’s strong educational adoption and institutional credibility support its positioning as the most complete solution for advanced users and institutional applications. StrategyQuant X’s comprehensive capabilities and continuous development make it the platform of choice for users who require maximum functionality and are willing to invest in learning complex tools.
Market Dynamics and Competitive Positioning
The algorithmic trading platform market exhibits clear segmentation based on user expertise, trading objectives, and feature requirements. This segmentation has enabled sustainable competitive positioning for all three platforms while driving innovation and improvement across the ecosystem.
The market trends indicate increasing demand for platforms that combine sophisticated capabilities with improved user experiences. Users increasingly expect professional-grade results without requiring extensive technical expertise, driving innovation in user interface design, automation capabilities, and educational resources. This trend benefits all three platforms but particularly favors solutions that successfully balance sophistication with accessibility.
The competitive landscape continues to evolve as platforms expand their capabilities and target new market segments. Build Alpha’s focus on robustness testing provides a sustainable competitive advantage as users become more sophisticated about overfitting risks and strategy validation requirements. Composer’s regulatory compliance and user experience excellence position it well for continued growth in the retail market as algorithmic trading becomes more mainstream. StrategyQuant X’s comprehensive capabilities and institutional relationships support its position as the platform of choice for advanced users and educational institutions.
Technology Trends and Future Development
The algorithmic trading platform industry continues to evolve rapidly, driven by advances in artificial intelligence, machine learning, and computational capabilities. Several key technology trends are likely to influence platform development and competitive positioning over the coming years.
Artificial Intelligence Integration represents a major development trend, with platforms increasingly incorporating machine learning algorithms for strategy generation, optimization, and validation. StrategyQuant X currently leads in AI integration, but all platforms are likely to expand their machine learning capabilities to remain competitive. The challenge for platform developers will be integrating AI capabilities while maintaining statistical rigor and avoiding overfitting risks.
Cloud Computing and Scalability are becoming increasingly important as users require more computational power for strategy development and testing. Platforms that successfully leverage cloud computing capabilities will be able to offer more sophisticated testing and optimization capabilities while reducing user infrastructure requirements.
Regulatory Compliance and Security are becoming increasingly important as algorithmic trading becomes more mainstream and attracts regulatory attention. Platforms that proactively address regulatory requirements and provide enhanced security features will have competitive advantages in serving institutional and retail markets.
User Experience Innovation continues to drive platform differentiation, with successful platforms finding ways to make sophisticated capabilities more accessible without sacrificing functionality. The challenge for platform developers is maintaining technical depth while improving accessibility and user experience.
Platform Evolution and Strategic Direction
Each platform appears to be pursuing distinct strategic directions that build on their current competitive advantages while addressing market opportunities and user requirements.
Build Alpha’s Strategic Direction appears focused on maintaining and extending its technical leadership in robustness testing and strategy validation. The platform’s continuous innovation in statistical testing methodologies and overfitting detection positions it to maintain its competitive advantage as users become more sophisticated about validation requirements. Build Alpha’s focus on technical excellence and customer support creates sustainable differentiation that is difficult for competitors to replicate.
Composer’s Strategic Direction focuses on expanding its retail market penetration through continued user experience innovation and proven strategy performance. The platform’s regulatory compliance and integrated execution model provide sustainable competitive advantages in the retail market. Composer’s growth strategy appears to emphasize expanding its user base through superior accessibility while maintaining professional-grade capabilities.
StrategyQuant X’s Strategic Direction emphasizes expanding its comprehensive capabilities through continued AI integration and platform compatibility. The platform’s institutional relationships and educational adoption provide sustainable competitive advantages that support continued development of advanced features. StrategyQuant X’s strategy appears to focus on maintaining its position as the most complete solution while improving accessibility for new user segments.
Industry Outlook and Market Opportunities
The algorithmic trading platform industry is positioned for continued growth driven by several favorable market trends and technological developments. The democratization of algorithmic trading through improved platforms and educational resources is expanding the addressable market beyond traditional institutional users to include retail investors and smaller trading operations.
Market Expansion Opportunities include geographic expansion, particularly for platforms currently limited to specific regions. International expansion represents significant growth opportunities for platforms that can successfully navigate regulatory requirements and local market characteristics.
Asset Class Expansion represents another significant opportunity, particularly for platforms that can successfully integrate new asset classes such as cryptocurrencies, alternative investments, and emerging markets. The challenge for platform developers is maintaining quality and reliability while expanding asset class coverage.
Integration and Ecosystem Development provide opportunities for platforms to expand their value propositions through partnerships and integrations with complementary services. Successful platforms are likely to develop comprehensive ecosystems that address all aspects of algorithmic trading operations.
Educational and Professional Services represent growing opportunities as the market expands to include less experienced users who require training and support services. Platforms that successfully develop educational and consulting capabilities can create additional revenue streams while supporting user success.
Final Recommendations and Selection Guidance
The selection of an optimal algorithmic trading platform should be based on careful assessment of specific requirements, priorities, and constraints rather than generic feature comparisons. Each of the three platforms analyzed provides excellent capabilities within their target markets and use cases.
For users prioritizing technical sophistication and strategy reliability, Build Alpha represents the optimal choice with industry-leading robustness testing capabilities and exceptional code generation reliability. The platform’s focus on statistical rigor and validation excellence makes it ideal for professional traders and quantitative developers who require maximum confidence in strategy deployment.
For users prioritizing accessibility and user experience, Composer represents the optimal choice with exceptional interface design and proven strategy performance. The platform’s no-code approach and integrated execution make sophisticated algorithmic trading accessible to retail investors without requiring extensive technical expertise.
For users requiring comprehensive capabilities and institutional-grade tools, StrategyQuant X represents the optimal choice with extensive features and advanced AI integration. The platform’s comprehensive capabilities and institutional credibility make it ideal for advanced users and educational institutions.
The success of algorithmic trading implementation depends ultimately on proper methodology, risk management, and continuous learning rather than platform selection alone. While platform capabilities provide important tools and advantages, user expertise and disciplined implementation remain the most critical success factors. Users should focus on developing strong foundational knowledge and risk management practices while leveraging platform capabilities to enhance their trading operations.
The algorithmic trading platform ecosystem continues to evolve and improve, providing users with increasingly sophisticated tools and capabilities. The three platforms analyzed in this report represent excellent examples of how different approaches to platform development can create sustainable competitive advantages while serving different market segments effectively. Users benefit from this competitive environment through continuous innovation and improvement across all platforms.
•Analysis Scope: Comprehensive comparison across five key dimensions
•Research Period: June 2025
•Methodology: Multi-source analysis including platform documentation, user reviews, and professional assessments
•Target Audience: Professional traders, institutional users, retail investors, and educational institutions
Disclaimer: This analysis is based on publicly available information and user testimonials as of June 2025. Platform capabilities and features may change over time. Users should conduct their own due diligence and consider their specific requirements when selecting algorithmic trading platforms. Past performance does not guarantee future results, and algorithmic trading involves significant risks including the potential for substantial losses.
Copyright Notice: This document was prepared for informational purposes. The analysis represents an independent assessment based on publicly available information and does not constitute investment advice or platform endorsement.
When we launched the Equities Entity Store in Mathematica, it revolutionized how financial professionals interact with market data by bringing semantic structure, rich metadata, and analysis-ready information into a unified framework. Mathematica’s EntityStore provided an elegant way to explore equities, ETFs, indices, and factor models through a symbolic interface. However, the industry landscape has evolved—the majority of quantitative finance, data science, and machine learning now thrives in Python.
While platforms like FactSet, WRDS, and Bloomberg provide extensive financial data, quantitative researchers still spend up to 80% of their time wrangling data rather than building models. Current workflows often involve downloading CSV files, manually cleaning them in pandas, and stitching together inconsistent time series—all while attempting to avoid subtle lookahead bias that invalidates backtests.
Recognizing these challenges, we’ve reimagined the Equities Entity Store for Python, focusing first on what the Python ecosystem does best: scalable machine learning and robust data analysis.
The Python Version: What’s New
Rather than beginning with metadata-rich entity hierarchies, the Python Equities Entity Store prioritizes the intersection of high-quality data and predictive modeling capabilities. At its foundation lies a comprehensive HDF5 dataset containing over 1,400 features for 7,500 stocks, measured monthly from 1995 to 2025—creating an extensive cross-sectional dataset optimized for sophisticated ML applications.
Our lightweight, purpose-built package includes specialized modules for:
Feature loading: Efficient extraction and manipulation of data from the HDF5 store
Feature preprocessing: Comprehensive tools for winsorization, z-scoring, neutralization, and other essential transformations
Label construction: Flexible creation of target variables, including 1-month forward information ratio
Ranking models: Advanced implementations including LambdaMART and other gradient-boosted tree approaches
Portfolio construction: Sophisticated tools for converting model outputs into actionable investment strategies
Backtesting and evaluation: Rigorous performance assessment across multiple metrics
Guaranteed Protection Against Lookahead Bias
A critical advantage of our Python Equities Entity Store implementation is its robust safeguards against lookahead bias—a common pitfall that compromises the validity of backtests and predictive models. Modern ML preprocessing pipelines often inadvertently introduce information from the future into training data, leading to unrealistic performance expectations.
Unlike platforms such as QuantConnect, Zipline, or even custom research environments that require careful manual controls, our system integrates lookahead protection at the architectural level:
# Example: Time-aware feature standardization with strict temporal boundaries
from equityentity.features.preprocess import TimeAwareStandardizer
# This standardizer only uses data available up to each point in time
standardizer = TimeAwareStandardizer(lookback_window='60M')
zscore_features = standardizer.fit_transform(raw_features)
# Instead of the typical approach that inadvertently leaks future data:
# DON'T DO THIS: sklearn.preprocessing.StandardScaler().fit_transform(raw_features)
Multiple safeguards are integrated throughout the system:
Point-in-time data snapshots: Features reflect only information available at the decision point
New listing delay: Stocks are only included after a customizable delay period from their first trading date
# From our data_loader.py - IPO bias protection through months_delay
for i, symbol in enumerate(symbols):
first_date = universe_df[universe_df["Symbol"] == symbol]["FirstDate"].iloc[0]
delay_end = first_date + pd.offsets.MonthEnd(self.months_delay)
valid_mask[:, i] = dates_pd > delay_end
Versioned historical data: Our HDF5 store maintains proper vintages to reflect real-world information availability
Pipeline validation tools: Built-in checks flag potential lookahead violations during model development
While platforms like Numerai provide pre-processed features to prevent lookahead, they limit you to their feature set. EES gives you the same guarantees while allowing complete flexibility in feature engineering—all with verification tools to validate your pipeline’s temporal integrity.
Application: Alpha from Feature Ranking
As a proof of concept, we’ve implemented a sophisticated stock ranking system using the LambdaMART algorithm, applied to a universe of current and former components of the S&P 500 Index.. The target label is the 1-month information ratio (IR_1m), constructed as:
Where r_i,t+1 is the forward 1-month return of stock i, r_benchmark is the corresponding sector benchmark return, and σ is the tracking error.
Using the model’s predicted rank scores, we form decile portfolios rebalanced monthly over a 25-year period (2000-2025), with an average turnover of 66% per month.
The top decile (Decile 10) portfolio demonstrates a Sharpe Ratio of approximately 0.8 with an annualized return of 17.8%—impressive performance that validates our approach. As shown in the cumulative return chart, performance remained consistent across different market regimes, including the 2008 financial crisis, the 2020 pandemic crash, and subsequent recovery periods.
Risk-adjusted performance increases across the decile portfolios, indicating that the selected factors appear to provide real explanatory power:
Looking at the feature importance chart, the most significant features include:
Technical features:
Volatility metrics dominate with “Volatility_ZScore” being the most important feature by a wide margin
Our model was trained on data from 1995-1999 and validated on an independent holdout set before final out-of-sample testing from 2000-2025, in which the model is updated every 60 months.
This rigorous approach to validation ensures that our performance metrics reflect realistic expectations rather than in-sample overfitting.
This diverse feature set confirms that durable alpha generation requires the integration of multiple orthogonal signals unified under a common ranking framework—precisely what our Python Equities Entity Store facilitates. The dominance of volatility-related features suggests that risk management is a critical component of the model’s predictive power.
│ └── constructor.py # Create portfolios from rank scores
├── backtest/
│ └── evaluator.py # Sharpe, IR, turnover, hit rate
└── entity/ # Optional metadata (JSON to dataclass)
├── equity.py
├── etf.py
└── index.py
Code Example: Ranking Model Training
Here’s how the ranking model module works, leveraging LightGBM’s LambdaMART implementation:
class RankModel:
def __init__(self, max_depth=4, num_leaves=32, learning_rate=0.1, n_estimators=500,
use_gpu=True, feature_names=None):
self.params = {
"objective": "lambdarank",
"max_depth": max_depth,
"num_leaves": num_leaves,
"learning_rate": learning_rate,
"n_estimators": n_estimators,
"device": "gpu" if use_gpu else "cpu",
"verbose": -1,
"max_position": 50
}
self.model = None
self.feature_names = feature_names if feature_names is not None else []
def train(self, features, labels):
# Reshape features and labels for LambdaMART format
n_months, n_stocks, n_features = features.shape
X = features.reshape(-1, n_features)
y = labels.reshape(-1)
group = [n_stocks] * n_months
train_data = lgb.Dataset(X, label=y, group=group, feature_name=self.feature_names)
self.model = lgb.train(self.params, train_data)
Portfolio Construction
The system seamlessly transitions from predictive scores to portfolio allocation with built-in transaction cost modeling:
# Portfolio construction with transaction cost awareness
def construct_portfolios(self):
n_months, n_stocks = self.pred_scores.shape
for t in range(n_months):
# Get predictions and forward returns
scores = self.pred_scores[t]
returns_t = self.returns[min(t + 1, n_months - 1)]
# Select top and bottom deciles
sorted_idx = np.argsort(scores)
long_idx = sorted_idx[-n_decile:]
short_idx = sorted_idx[:n_decile]
# Calculate transaction costs from portfolio turnover
curr_long_symbols = set(symbols_t[long_idx])
curr_short_symbols = set(symbols_t[short_idx])
long_trades = len(curr_long_symbols.symmetric_difference(self.prev_long_symbols))
short_trades = len(curr_short_symbols.symmetric_difference(self.prev_short_symbols))
tx_cost_long = self.tx_cost * long_trades
tx_cost_short = self.tx_cost * short_trades
# Calculate net returns with costs
long_ret = long_raw - tx_cost_long
short_ret = -short_raw - tx_cost_short - self.loan_cost
Complete Workflow Example
The package is designed for intuitive workflows with minimal boilerplate. Here’s how simple it is to get started:
from equityentity.features import FeatureLoader, LabelGenerator
from equityentity.models import LambdaMARTRanker
from equityentity.portfolio import DecilePortfolioConstructor
# Load features with point-in-time awareness
loader = FeatureLoader(hdf5_path='equity_features.h5')
features = loader.load_features(start_date='2010-01-01', end_date='2025-01-01')
# Generate IR_1m labels
label_gen = LabelGenerator(benchmark='sector_returns')
labels = label_gen.create_information_ratio(forward_period='1M')
# Train a ranking model
ranker = LambdaMARTRanker(n_estimators=500, learning_rate=0.05)
ranker.fit(features, labels)
# Create portfolios from predictions
constructor = DecilePortfolioConstructor(rebalance_freq='M')
portfolios = constructor.create_from_scores(ranker.predict(features))
# Evaluate performance
performance = portfolios['decile_10'].evaluate()
print(f"Sharpe Ratio: {performance['sharpe_ratio']:.2f}")
print(f"Information Ratio: {performance['information_ratio']:.2f}")
print(f"Annualized Return: {performance['annualized_return']*100:.1f}%")
The package supports both configuration file-based workflows for production use and interactive Jupyter notebook exploration. Output formats include pandas DataFrames, JSON for web applications, and HDF5 for efficient storage of results.
Why Start with Cross-Sectional ML?
While Mathematica’s EntityStore emphasized symbolic navigation and knowledge representation, Python excels at algorithmic learning and numerical computation at scale. Beginning with the HDF5 dataset enables immediate application by quantitative researchers, ML specialists, and strategy developers interested in:
Exploring sophisticated feature engineering across time horizons and market sectors
Building powerful predictive ranking models with state-of-the-art ML techniques
Constructing long-short portfolios with dynamic scoring mechanisms
Developing robust factor models and alpha signals
And because we’ve already created metadata-rich JSON files for each entity, we can progressively integrate the symbolic structure—creating a hybrid system where machine learning capabilities complement knowledge representation.
Increasingly, quantitative researchers are integrating tools like LangChain, GPT-based agents, and autonomous research pipelines to automate idea generation, feature testing, and code execution. The structured design of the Python Equities Entity Store—with its modularity, metadata integration, and time-consistent features—makes it ideally suited for use as a foundation in LLM-driven quantitative workflows.
Competitive Pricing and Value
While alternative platforms in this space typically come with significant cost barriers, we’ve positioned the Python Equities Entity Store to be accessible to firms of all sizes:
While open-source platforms like QuantConnect, Zipline, and Backtrader provide accessible backtesting environments, they often lack the scale, granularity, and point-in-time feature control required for advanced cross-sectional ML strategies. The Python Equities Entity Store fills this gap—offering industrial-strength data infrastructure, lookahead protection, and extensibility without the steep cost of commercial platforms.
Unlike these competitors that often require multiple subscriptions to achieve similar functionality, Python Equities Entity Store provides an integrated solution at a fraction of the cost. This pricing strategy reflects our commitment to democratizing access to institutional-grade quantitative tools.
Next Steps
We’re excited to announce our roadmap for the Python Equities Entity Store:
July 2025 Release: The official launch of our HDF5-compatible package, complete with:
Comprehensive documentation and API reference
Jupyter notebooks demonstrating key workflows from data loading to portfolio construction
Example strategies showcasing the system’s capabilities across different market regimes
Performance benchmarks and baseline models with full backtest history
Python package available via PyPI (pip install equityentity)
Docker container with pre-loaded example datasets
Q3 2025: Integration of the symbolic entity framework, allowing seamless navigation between quantitative features and qualitative metadata
Q4 2025: Extension to additional asset classes and alternative data sources, expanding the system’s analytical scope
Early 2026: Launch of a cloud-based computational environment for collaboration and strategy sharing
Accessing the Python Equities Entity Store
As a special promotion, existing users of the current Mathematica Equities Entity Store Enterprise Edition will be given free access to the Python version on launch.
So, if you sign up now for the Enterprise Edition you will receive access to both the existing Mathematica version and the new Python version as soon as it is released.
After the launch of the Python Equities Entity Store, each product will be charged individually. So this limited time offer represents a 50% discount.
By prioritizing scalable feature datasets and sophisticated ranking models, the Python version of the Equities Entity Store positions itself as an indispensable tool for modern equity research. It bridges the gap between raw data and actionable insights, combining the power of machine learning with the structure of knowledge representation.
The Python Equities Entity Store represents a significant step forward in quantitative finance tooling—enabling faster iteration, more robust models, and ultimately, better investment decisions.
“The first rule of investing isn’t ‘Don’t lose money.’ It’s ‘Recognize when the rules are changing.'”
UPDATE: MAY 1 2025
The February 2025 European semiconductor export restrictions sent markets into a two-day tailspin, wiping $1.3 trillion from global equities. For most investors, it was another stomach-churning reminder of how traditional portfolios falter when geopolitics overwhelms fundamentals.
But for a growing cohort of forward-thinking portfolio managers, it was validation. Their Strategic Scenario Portfolios—deliberately constructed to thrive during specific geopolitical events—delivered positive returns amid the chaos.
I’m not talking about theoretical models. I’m talking about real money, real returns, and a methodology you can implement right now.
What Exactly Is a Strategic Scenario Portfolio?
A Strategic Scenario Portfolio (SSP) is an investment allocation designed to perform robustly during specific high-impact events—like trade wars, sanctions, regional conflicts, or supply chain disruptions.
Unlike conventional approaches that react to crises, SSPs anticipate them. They’re narrative-driven, built around specific, plausible scenarios that could reshape markets. They’re thematically concentrated, focusing on sectors positioned to benefit from that scenario rather than broad diversification. They maintain asymmetric balance, incorporating both downside protection and upside potential. And perhaps most importantly, they’re ready for deployment before markets fully price in the scenario.
Think of SSPs as portfolio “insurance policies” that also have the potential to deliver substantial alpha.
“Why didn’t I know about this before now?” SSPs aren’t new—institutional investors have quietly used similar approaches for decades. What’s new is systematizing this approach for broader application.
Real-World Proof: Two Case Studies That Speak for Themselves
Case Study #1: The 2018-2019 US-China Trade War
When trade tensions escalated in 2018, we constructed the “USChinaTradeWar2018” portfolio with a straightforward mandate: protect capital while capitalizing on trade-induced dislocations.
The portfolio allocated 25% to SPDR Gold Shares (GLD) as a core risk-off hedge. Another 20% went to Consumer Staples (VDC) for defensive positioning, while 15% was invested in Utilities (XLU) for stable returns and low volatility. The remaining 40% was distributed equally among Walmart (WMT), Newmont Mining (NEM), Procter & Gamble (PG), and Industrials (XLI), creating a balanced mix of defensive positioning with selective tactical exposure.
The results were remarkable. From May 2018 to December 2019, this portfolio delivered a total return of 30.2%, substantially outperforming the S&P 500’s 22.0%. More impressive than the returns, however, was the risk profile. The portfolio achieved a Sharpe ratio of 1.8 (compared to the S&P 500’s 0.6), demonstrating superior risk-adjusted performance. Its maximum drawdown was a mere 2.2%, while the S&P 500 experienced a 14.0% drawdown during the same period. With a beta of just 0.26 and alpha of 11.7%, this portfolio demonstrated precisely what SSPs are designed to deliver: outperformance with dramatically reduced correlation to broader market movements.
Note: Past performance is not indicative of future results. Performance calculated using total return with dividends reinvested, compared against S&P 500 total return.
Case Study #2: The 2025 Tariff War Portfolio
Fast forward to January 2025. With new tariffs threatening global trade, we developed the “TariffWar2025” portfolio using a similar strategic framework but adapted to the current environment.
The core of the portfolio (50%) established a defensive foundation across Utilities (XLU), Consumer Staples (XLP), Healthcare (XLV), and Gold (GLD). We allocated 20% toward domestic industrial strength through Industrials (XLI) and Energy (XLE) to capture reshoring benefits and energy independence trends. Another 20% targeted strategic positioning with Lockheed Martin (LMT) benefiting from increased defense spending and Cisco (CSCO) offering exposure to domestic technology infrastructure with limited Chinese supply chain dependencies. The remaining 10% created balanced treasury exposure across long-term (TLT) and short-term (VGSH) treasuries to hedge against both economic slowdown and rising rates.
The results through Q1 2025 have been equally impressive. While the S&P 500 declined 4.6%, the TariffWar2025 portfolio generated a positive 4.3% return. Its Sharpe ratio of 8.4 indicates exceptional risk-adjusted performance, and remarkably, the portfolio experienced zero drawdown during a period when the S&P 500 fell by as much as 7.1%. With a beta of 0.20 and alpha of 31.9%, the portfolio again demonstrated the power of scenario-based investing in navigating geopolitical turbulence.
Note: Past performance is not indicative of future results. Performance calculated using total return with dividends reinvested, compared against S&P 500 total return.
Why Traditional Portfolios Fail When You Need Them Most
Traditional portfolio construction relies heavily on assumptions that often crumble during times of geopolitical stress. Historical correlations, which form the backbone of most diversification strategies, routinely break during crises. Mean-variance optimization, a staple of modern portfolio theory, falters dramatically when markets exhibit non-normal distributions, which is precisely what happens during geopolitical events. And the broad diversification that works so well in normal times often converges in stressed markets, leaving investors exposed just when protection is most needed.
When markets fracture along geopolitical lines, these assumptions collapse spectacularly. Consider the March 2023 banking crisis: correlations between tech stocks and regional banks—historically near zero—suddenly jumped to 0.75. Or recall how in 2022, both stocks AND bonds declined simultaneously, shattering the foundation of 60/40 portfolios.
What geopolitical scenario concerns you most right now, and how is your portfolio positioned for it? This question reveals the central value proposition of Strategic Scenario Portfolios.
Building Your Own Strategic Scenario Portfolio: A Framework for Success
You don’t need a quant team to implement this approach. The framework begins with defining a clear scenario. Rather than vague concerns about “volatility” or “recession,” an effective SSP requires a specific narrative. For example: “Europe imposes carbon border taxes, triggering retaliatory measures from major trading partners.”
From this narrative foundation, you can map the macro implications. Which regions would face the greatest impact? What sectors would benefit or suffer? How might interest rates, currencies, and commodities respond? This mapping process translates your scenario into investment implications.
The next step involves identifying asymmetric opportunities—situations where the market is underpricing both risks and potential benefits related to your scenario. These asymmetries create the potential for alpha generation within your protective framework.
Structure becomes critical at this stage. A typical SSP balances defensive positions (usually 60-75% of the allocation) with opportunity capture (25-40%). This balance ensures capital preservation while maintaining upside potential if your scenario unfolds as anticipated.
Finally, establish monitoring criteria. Define what developments would strengthen or weaken your scenario’s probability, and set clear guidelines for when to increase exposure, reduce positions, or exit entirely.
For those new to this approach, start with a small allocation—perhaps 5-10% of your portfolio—as a satellite to your core holdings. As your confidence or the scenario probability increases, you can scale up exposure accordingly.
Common Questions About Strategic Scenario Portfolios
“Isn’t this just market timing in disguise?” This question arises frequently, but the distinction is important. Market timing attempts to predict overall market movements—when the market will rise or fall. SSPs are fundamentally different. They’re about identifying specific scenarios and their sectoral impacts, regardless of broad market direction. The focus is on relative performance within a defined context, not on predicting market tops and bottoms.
“How do I know when to exit an SSP position?” The key is defining exit criteria in advance. This might include scenario resolution (like a trade agreement being signed), time limits (reviewing the position after a predefined period), or performance thresholds (taking profits or cutting losses at certain levels). Clear exit strategies prevent emotional decision-making when markets become volatile.
“Do SSPs work in all market environments?” This question reveals a misconception about their purpose. SSPs aren’t designed to outperform in all environments. They’re specifically built to excel during their target scenarios, while potentially underperforming in others. That’s why they work best as tactical overlays to core portfolios, rather than as stand-alone investment approaches.
“How many scenarios should I plan for simultaneously?” Start with one or two high-probability, high-impact scenarios. Too many simultaneous SSPs can dilute your strategic focus and create unintended exposures. As you gain comfort with the approach, you can expand your scenario coverage while maintaining portfolio coherence.
Tools for the Forward-Thinking Investor
Implementing SSPs effectively requires both qualitative and quantitative tools. Systems like the Equities Entity Store for MATLAB provide institutional-grade capabilities for modeling multi-asset correlations across different regimes. They enable stress-testing portfolios against specific geopolitical scenarios, optimizing allocations based on scenario probabilities, and tracking exposures to factors that become relevant primarily in crisis periods.
These tools help translate scenario narratives into precise portfolio allocations with targeted risk exposures. While sophisticated analytics enhance the process, the core methodology remains accessible even to investors without advanced quantitative resources.
The Path Forward in a Fractured World
The investment landscape of 2025 is being shaped by forces that traditional models struggle to capture. Deglobalization and reshoring are restructuring supply chains and changing regional economic dependencies. Resource nationalism and energy security concerns are creating new commodity dynamics. Strategic competition between major powers is manifesting in investment restrictions, export controls, and targeted sanctions. Technology fragmentation along geopolitical lines is creating parallel innovation systems with different winners and losers.
In this environment, passive diversification is necessary but insufficient. Strategic Scenario Portfolios provide a disciplined framework for navigating these challenges, protecting capital, and potentially generating significant alpha when markets are most volatile.
The question isn’t whether geopolitical disruptions will continue—they will. The question is whether your portfolio is deliberately designed to withstand them.
Next Steps: Getting Started With SSPs
The journey toward implementing Strategic Scenario Portfolios begins with identifying your most concerning scenario. What geopolitical or policy risk keeps you up at night? Is it escalation in the South China Sea? New climate regulations? Central bank digital currencies upending traditional banking?
Once you’ve identified your scenario, assess your current portfolio’s exposure. Would your existing allocations benefit, suffer, or remain neutral if this scenario materialized? This honest assessment often reveals vulnerabilities that weren’t apparent through traditional risk measures.
Design a prototype SSP focused on your scenario. Start small, perhaps with a paper portfolio that you can monitor without committing capital immediately. Track both the portfolio’s performance and developments related to your scenario, refining your approach as you gain insights.
For many investors, this process benefits from professional guidance. Complex scenario mapping requires a blend of geopolitical insight, economic analysis, and portfolio construction expertise that often exceeds the resources of individual investors or even smaller investment teams.
About the Author: Jonathan Kinlay, PhD is Principal Partner at Golden Bough Partners LLC, a quantitative proprietary trading firm, and managing partner of Intelligent Technologies. With experience as a finance professor at NYU Stern and Carnegie Mellon, he specializes in advanced portfolio construction, algorithmic trading systems, and quantitative risk management. His latest book, “Equity Analytics” (2024), explores modern approaches to market resilience. Jonathan works with select institutional clients and fintech ventures as a strategic advisor, helping them develop robust quantitative frameworks that deliver exceptional risk-adjusted returns. His proprietary trading systems have consistently achieved Sharpe ratios 2-3× industry benchmarks.
📬 Let’s Connect: Have you implemented scenario-based approaches in your investment process? What geopolitical risks are you positioning for? Share your thoughts in the comments or connect with me directly.
Disclaimer: This article is for informational purposes only and does not constitute investment advice. The performance figures presented are based on actual portfolios but may not be achievable for all investors. Always conduct your own research and consider your financial situation before making investment decisions.
Key takeaways from “Night Trading: Higher Returns with Lower Risk”:
• Overnight returns show strong long-term persistence (up to 5 years!) • Some stocks consistently outperform overnight • Overnight trading strategies can be profitable even after costs • Potential for lower risk AND higher returns for select stocks
The Overnight Bias Parameter (OBP) model, integrated into the Equities Entity Store, offers a powerful tool for identifying prime night trading opportunities.
The results? An OBP-based portfolio achieved an impressive 24.68% annual return from 1995-2021, with strong risk-adjusted performance (18.58%) and low market correlation (beta of 0.35).
This research challenges traditional risk-return paradigms and opens up exciting possibilities for savvy investors.
Want to learn more about leveraging these overnight return patterns? Check out the full presentation or visit the Equities Entity Store for real-time OBP data and analysis tools.
Consider a financial asset whose price, Xt, follows a mean-reverting stochastic process. A common model for mean reversion is the Ornstein-Uhlenbeck (OU) process, defined by the stochastic differential equation (SDE):
Objective
The trader aims to maximize the expected cumulative profit from trading this asset over a finite horizon, subject to transaction costs. The trader’s control is the rate of buying or selling the asset, denoted by ut, at time t.
Hamilton-Jacobi-Bellman (HJB) Equation
To find the optimal trading strategy, we frame this as a stochastic control problem. The value function,V(t,Xt), represents the maximum expected profit from time t to the end of the trading horizon, given the current price level Xt. The HJB equation for this problem is:
where C(ut) represents the cost of trading, which can depend on the rate of trading ut. The term ut(Xt−C(ut)) captures the profit from trading, adjusted for transaction costs.
Solution Approach
Boundary and Terminal Conditions: Specify terminal conditions for V(T,XT), where T is the end of the trading horizon, and boundary conditions for V(t,Xt) based on the problem setup.
Solve the HJB Equation: The solution involves finding the function V(t,Xt) and the control policy ut∗ that maximizes the HJB equation. This typically requires numerical methods, especially for complex cost functions or when closed-form solutions are not feasible.
Interpret the Optimal Policy: The optimal control ut∗ derived from solving the HJB equation indicates the optimal rate of trading (buying or selling) at any time t and price level Xt, considering the mean-reverting nature of the price and the impact of transaction costs.
Key Insights
No-Trade Zones: The presence of transaction costs often leads to the creation of no-trade zones in the optimal policy, where the expected benefit from trading does not outweigh the costs.
Mean-Reversion Exploitation: The optimal strategy exploits mean reversion by adjusting the trading rate based on the deviation of the current price from the mean level, μ.
The Lipton & Lopez de Marcos Paper
“A Closed-form Solution for Optimal Mean-reverting Trading Strategies” contributes significantly to the literature on optimal trading strategies for mean-reverting instruments. The paper focuses on deriving optimal trading strategies that maximize the Sharpe Ratio by solving the Hamilton-Jacobi-Bellman equation associated with the problem. It outlines a method that relies on solving a Fredholm integral equation to determine the optimal trading levels, taking into account transaction costs.
The paper begins by discussing the relevance of mean-reverting trading strategies across various markets, particularly emphasizing the energy market’s suitability for such strategies. It acknowledges the practical challenges and limitations of previous analytical results, mainly asymptotic and applicable to perpetual trading strategies, and highlights the novelty of addressing finite maturity strategies.
A key contribution of the paper is the development of an explicit formula for the Sharpe ratio in terms of stop-loss and take-profit levels, which allows traders to deploy tactical execution algorithms for optimal strategy performance under different market regimes. The methodology involves calibrating the Ornstein-Uhlenbeck process to market prices and optimizing the Sharpe ratio with respect to the defined levels. The authors present numerical results that illustrate the Sharpe ratio as a function of these levels for various parameters and discuss the implications of their findings for liquidity providers and statistical arbitrage traders.
The paper also reviews traditional approaches to similar problems, including the use of renewal theory and linear transaction costs, and compares these with its analytical framework. It concludes that its method provides a valuable tool for liquidity providers and traders to optimally execute their strategies, with practical applications beyond theoretical interest.
The authors use the path integral method to understand the behavior of their solutions, providing an alternative treatment to linear transaction costs that results in a determination of critical boundaries for trading. This approach is distinct in its use of direct solving methods for the Fredholm equation and adjusting the trading thresholds through a numerical method until a matching condition is met.
This research not only advances the understanding of optimal trading rules for mean-reverting strategies but also offers practical guidance for traders and liquidity providers in implementing these strategies effectively.