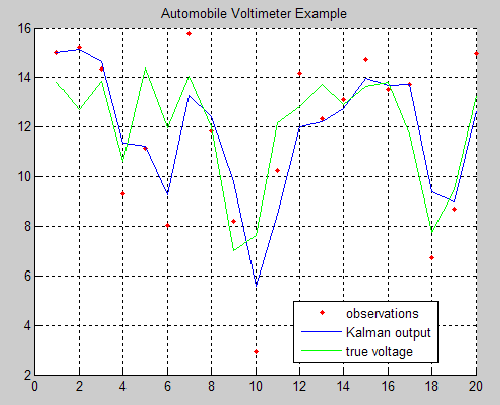
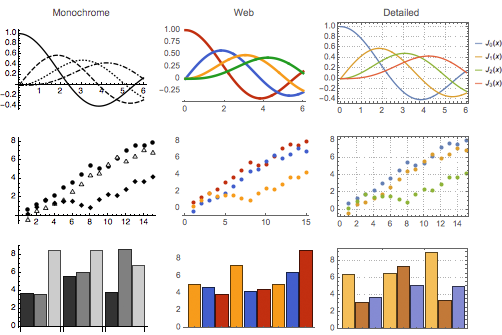
In a previous article I made a detailed comparison of Mathematica and Python and tried to identify areas where the former excels. Despite the many advantages of the Python technology stack, I was able to pinpoint a few areas in which I think Mathematica holds the upper hand. Whether those are sufficient to warrant the investment of time and money required to master the Wolfram Language is another matter, which the user must decide for himself.
In this comparison between Matlab and Python I won’t reiterate the strengths of the Python that make it the programming language of choice for so many developers. Let me instead focus on some of the key aspects of Matlab where I think the Mathworks product outshines its rival.
Matlab is designed for numerical computing, while Python is a general-purpose programming language that has become a major tool for scientific computing through libraries like NumPy, SciPy, and Matplotlib.
The key advantages of Matlab relative to Python, as I see them, are as follows:
Integrated Development Environment (IDE):
Matlab comes with a feature-rich IDE that is tailored for mathematical and engineering workflows. This includes tools for debugging, data visualization, GUI creation, and managing workspace variables. The Matlab IDE is specifically designed to streamline the development of mathematical and engineering applications.
Advanced Toolboxes:
Matlab offers a wide range of specialized toolboxes for different applications, including signal processing, control systems, neural networks, image processing, and many others. These toolboxes are professionally developed, rigorously tested, and regularly updated, providing a comprehensive suite of algorithms and functions for specific domains. With its vast ecosystem of scientific libraries Python has caught up with Matlab in recent years, and even overtaken it in some areas, but Matlab’s toolboxes are tried and battle-tested technologies that are used by millions of users in state-of-the-art applications.
Simulink:
Matlab provides Simulink, a platform for Model-Based Design for dynamic and embedded systems. Simulink is a graphical programming environment for modeling, simulating, and analyzing multidomain dynamical systems. This is particularly useful in engineering applications where system modeling and simulation are crucial.
Built-in Support for Matrix Operations:
Matlab (Matrix Laboratory) has inherent support for matrix operations and linear algebra, making it highly efficient for tasks that involve complex mathematical computations.
Performance:
Matlab is optimized for operations involving matrices and vectors, which are central to engineering and scientific computations. For certain numerical tasks, Matlab’s performance is superior due to its highly optimized code and ability to handle parallel computing and GPU acceleration effectively.
Matlab’s speed has further accelerated over the last decade due to just-in-time compilation. This feature automatically compiles Matlab’s interpreted code into machine code at runtime, which speeds up execution, especially in loops and computationally intensive tasks. The JIT compilation process is entirely transparent to the user, requiring no modifications to the code or the development process.
Python itself is an interpreted language and does not include JIT compilation in its standard implementation (CPython). However, JIT compilation can be introduced through third-party libraries or alternative Python implementations, such as Numba or PyPy.
Testing and Debugging:
Both Matlab and Python are equipped with robust testing and debugging tools that cater to their specific user bases. Matlab’s tools are tightly integrated into its IDE and are particularly tailored for numerical computing and engineering tasks. I would regard them as the industry standard in terms of features, ease of use and helpfulness. In contrast, Python’s testing and debugging ecosystem is more diverse, with multiple options available for different tasks, including third-party libraries that extend its capabilities.
Documentation and Support:
Matlab’s documentation is extensive, well-organized, and includes examples for a wide range of functions and toolboxes. Additionally, MathWorks provides excellent support services, including technical support and community forums, which can be particularly valuable for complex or specialized projects.
Conclusion
While Python has gained significant popularity in scientific computing, data science, and machine learning due to its open-source nature and the vast ecosystem of libraries, Matlab holds strong advantages in numerical computing, engineering applications, and when integrated solutions with robust support and documentation are required.
However, Python offers greater flexibility, scalability and has grown significantly in scientific computing. MATLAB historically had limitations with very large datasets, but recent releases have added features to improve performance with big data. Still, Python likely retains an advantage for extreme scales. The choice depends on the specific use case – for small-scale numerical computing and modeling MATLAB provides an integrated optimized environment while Python excels in general-purpose programming and very large-scale data intensive applications. However, both continue to evolve impressive capabilities so the lines are blurring. Ultimately data scientists and engineers are best served by being proficient in both languages.