
Analyzing Big Data
Very large datasets – comprising voluminous numbers of symbols – present challenges for the analyst, not least of which is the difficulty of visualizing relationships between the individual component assets. Absent the visual clues that are often highlighted by graphical images, it is easy for the analyst to overlook important changes in relationships. One means of tackling the problem is with the use of graph theory.

DOW 30 Index Member Stocks Correlation Graph
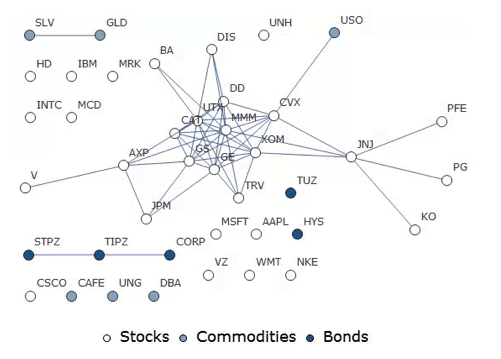
In this example I have selected a universe of the Dow 30 stocks, together with a sample of commodities and bonds and compiled a database of daily returns over the period from Jan 2012 to Dec 2013. If we want to look at how the assets are correlated, one way is to created an adjacency graph that maps the interrelations between assets that are correlated at some specified level (0.5 of higher, in this illustration).
Obviously the choice of correlation threshold is somewhat arbitrary, and it is easy to evaluate the results dynamically, across a wide range of different threshold parameters, say in the range from 0.3 to 0.75:

The choice of parameter (and time frame) may be dependent on the purpose of the analysis: to construct a portfolio we might select a lower threshold value; but if the purpose is to identify pairs for possible statistical arbitrage strategies, one will typically be looking for much higher levels of correlation.
Correlated Cliques
Reverting to the original graph, there is a core group of highly inter-correlated stocks that we can easily identify more clearly using the Mathematica function FindClique to specify graph nodes that have multiple connections:
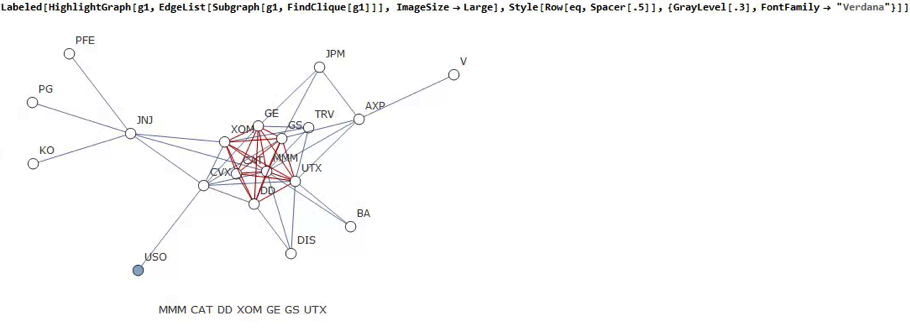
We might, for example, explore the relative performance of members of this sub-group over time and perhaps investigate the question as to whether relative out-performance or under-performance is likely to persist, or, given the correlation characteristics of this group, reverse over time to give a mean-reversion effect.
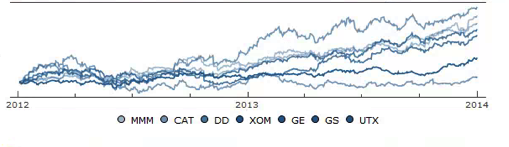
Constructing a Replicating Portfolio
An obvious application might be to construct a replicating portfolio comprising this equally-weighted sub-group of stocks, and explore how well it tracks the Dow index over time (here I am using the DIA ETF as a proxy for the index, for the sake of convenience):
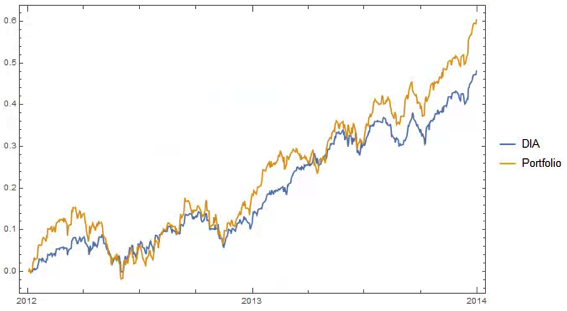
The correlation between the Dow index (DIA ETF) and the portfolio remains strong (around 0.91) throughout the out-of-sample period from 2014-2016, although the performance of the portfolio is distinctly weaker than that of the index ETF after the early part of 2014:
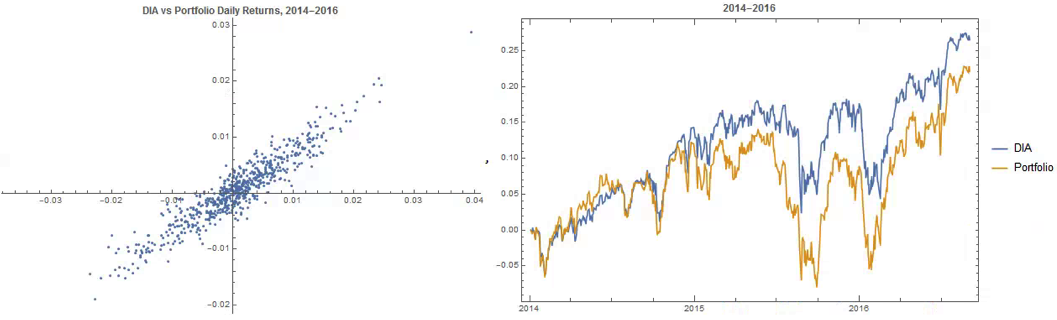
Constructing Robust Portfolios
Another application might be to construct robust portfolios of lower-correlated assets. Here for example we use the graph to identify independent vertices that have very few correlated relationships (designated using the star symbol in the graph below). We can then create an equally weighted portfolio comprising the assets with the lowest correlations and compare its performance against that of the Dow Index.
The new portfolio underperforms the index during 2014, but with lower volatility and average drawdown.

Conclusion – Graph Theory has Applications in Portfolio Constructions and Index Replication
Graph theory clearly has a great many potential applications in finance. It is especially useful as a means of providing a graphical summary of data sets involving a large number of complex interrelationships, which is at the heart of portfolio theory and index replication. Another useful application would be to identify and evaluate correlation and cointegration relationships between pairs or small portfolios of stocks, as they evolve over time, in the context of statistical arbitrage.