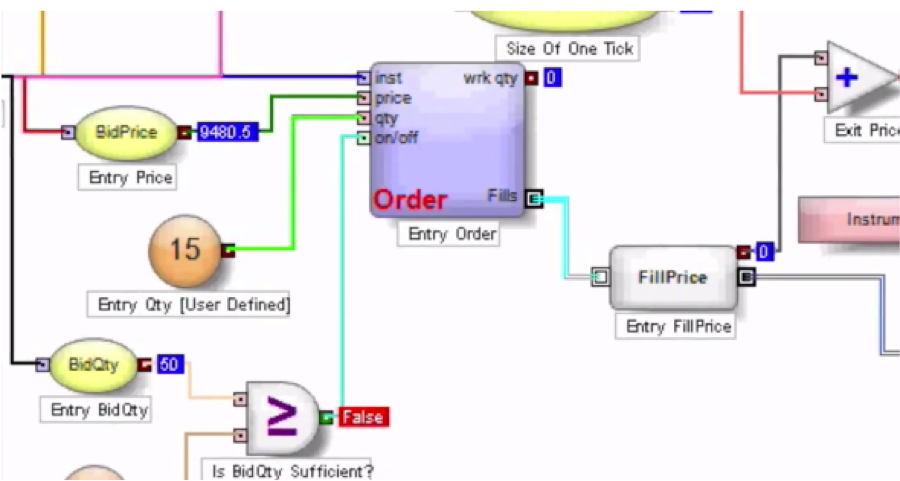
High-frequency statistical arbitrage leverages sophisticated quantitative models and cutting-edge technology to exploit fleeting inefficiencies in global markets. Pioneered by hedge funds and proprietary trading firms over the last decade, the strategy identifies and capitalizes on sub-second price discrepancies across assets ranging from public equities to foreign exchange.
At its core, statistical arbitrage aims to predict short-term price movements based on probability theory and historical relationships. When implemented at high frequencies—microseconds or milliseconds—the quantitative models uncover trading opportunities unavailable to human traders. The predictive signals are then executable via automated, low-latency infrastructure.
These strategies thrive on speed. By getting pricing data faster, determining anomalies faster, and executing orders faster than the rest of the market, you expand the momentary windows to trade profitably.
Seminal papers have delved into the mathematical and technical nuances underpinning high-frequency statistical arbitrage. Zhaodong Zhong and Jian Wang’s 2014 paper develops stochastic models to quantify how market microstructure and randomness influence high-frequency trading outcomes. Samuel Wong’s 2018 research explores adapting statistical arbitrage for the nascent cryptocurrency markets.
Yet maximizing the strategy’s profitability poses an ongoing challenge. Changing market dynamics necessitate regular algorithm tweaking and infrastructure upgrades. It’s an arms race for lower latency and better predictive signals. Any edge gained disappears quickly as new firms implement similar systems. Regulatory attention also persists due to concerns over unintended impacts on market stability.
Nonetheless, high-frequency statistical arbitrage retains a crucial role for leading quant funds. Ongoing advances in machine learning, cloud computing, and execution technology promise to further empower the strategy. Though the competitive landscape grows more challenging, the cutting edge continues advancing profitably. Where human perception fails, automated high-frequency strategies recognize and seize value.
Implementing an Intraday Statistical Arbitrage Model
While HFT infrastructure and know-how are beyond the reach of most traders, it is possible to conceive of a system for pairs trading at moderate frequency, say 1-minute intervals.
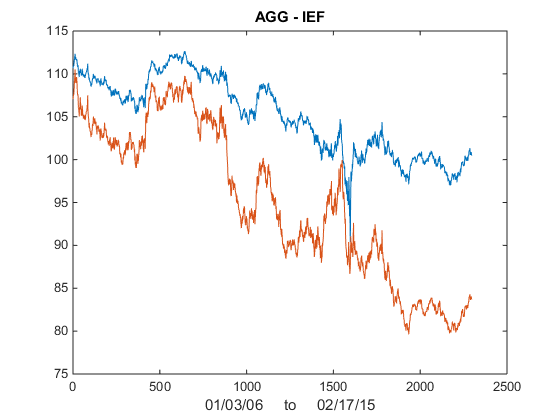
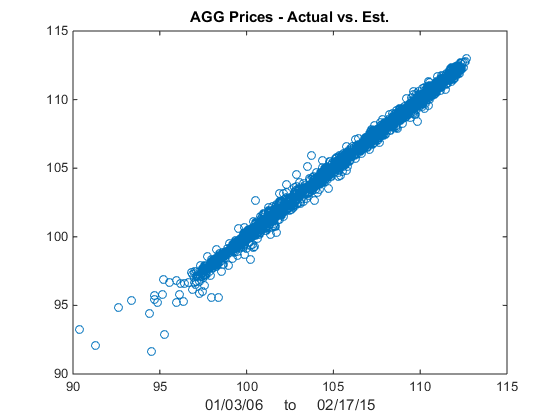
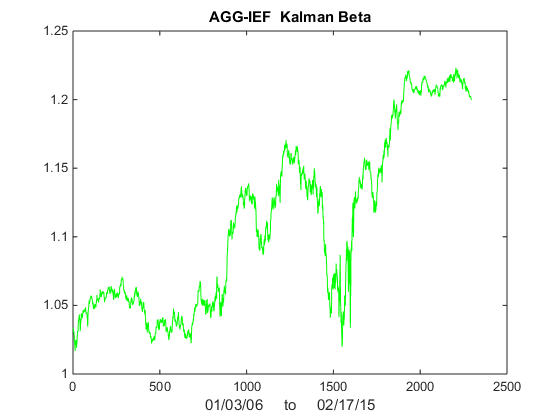
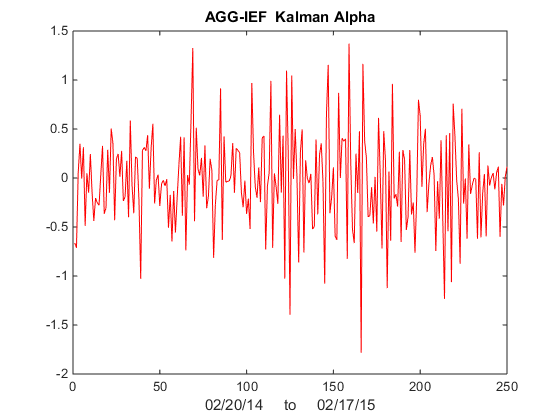
We illustrate the approach with an algorithm that was originally showcased by Mathworks some years ago (but which has since slipped off the radar and is no longer available to download). I’ve amended the code to improve its efficiency, but the core idea remains the same: we conduct a rolling backtest in which data on a pair of assets, in this case spot prices of Brent Crude (LCO) and West Texas Intermediate (WTI), is subdivided into in-sample and out-of-sample periods of varying lengths. We seek to identify windows in which the price series are cointegrated in the sense of Engle-Granger and then apply the regression parameters to take long and short positions in the pair during the corresponding out-of-sample period. The idea is to trade only when there is compelling evidence of cointegration between the two series and to avoid trading at other times.
The critical part of the walk-forward analysis code is as shown below. Note we are using a function parametersweep to conduct a grid search across a range of in-sample dataset sizes to determine if the series are cointegrated (according to the Engle-Granger test) in that sub-period and, if so, determine the position size according to the regression parameters. The optimal in-sample parameters are then applied in the out-of-sample period and the performance results are recorded.
Here we are making use of Matlab’s parallelization capabilities, which work seamlessly to spread the processing load across available CPUs, handling the distribution of variables, function definitions and dependencies with ease. My experience with trying to parallelize Python, by contrast, is often a frustrating one that frequently fails at the first several attempts.
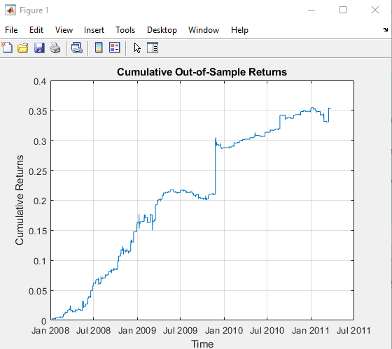

The results appear promising; however, the data is out-of-date, comes from a source that can be less than 100% reliable and may represent price quotes rather than traded prices. If we switch to 1-minute traded prices in a pair of stocks such as PEP and KO that are known to be cointegrated over long horizons, the outcome is very different:
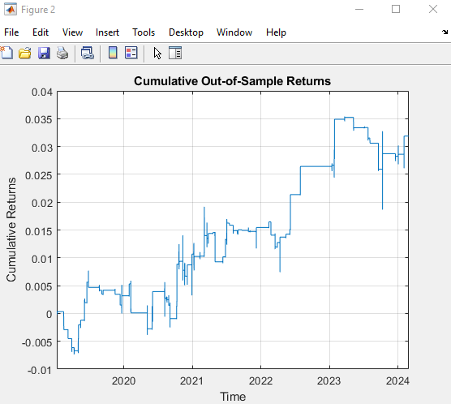
Conclusion
High-frequency statistical arbitrage represents the convergence of cutting-edge technology and quantitative modeling to uncover fleeting trading advantages invisible to human market participants. This strategy has proven profitable for sophisticated hedge funds and prop shops, but also raises broader questions around fairness, regulation, and the future of finance.
However, the competitive edge gained from high-frequency strategies diminishes quickly as the technology diffuses across the industry. Firms must run faster just to stand still.
Continued advancement in machine learning, cloud computing, and execution infrastructure promises to expand the frontier. But practitioners and policymakers alike share responsibility for ensuring market integrity and stability amidst this technology arms race.
In conclusion, high-frequency statistical arbitrage remains essential to many leading quantitative firms, with the competitive landscape growing ever more challenging. Realizing the potential of emerging innovations, while promoting healthy markets that benefit all participants, will require both vision and wisdom. The path ahead lies between cooperation and competition, ethics and incentives. By bridging these domains, high-frequency strategies can contribute positively to financial evolution while capturing sustainable edge.
References:
Zhong, Zhaodong, and Jian Wang. “High-Frequency Trading and Probability Theory.” (2014).
Wong, Samuel S. Y. “A High-Frequency Algorithmic Trading Strategy for Cryptocurrency.” (2018).
Glossary
For those unfamiliar with the topic of statistical arbitrage and its commonly used terms and concepts, check out my book Equity Analytics, which covers the subject matter in considerable detail.