

As regards the question of forecasting accuracy discussed in the paper on Forecasting Volatility in the S&P 500 Index, there are two possible misunderstandings here that need to be cleared up. These arise from remarks by one commentator as follows:
“An above 50% vol direction forecast looks good,.. but “direction” is biased when working with highly skewed distributions! ..so it would be nice if you could benchmark it against a simple naive predictors to get a feel for significance, -or- benchmark it with a trading strategy and see how the risk/return performs.”
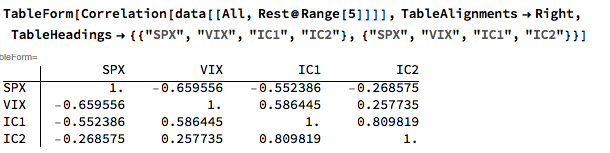
(i) The first point is simple, but needs saying: the phrase “skewed distributions” in the context of volatility modeling could easily be misconstrued as referring to the volatility skew. This, of course, is used to describe to the higher implied vols seen in the Black-Scholes prices of OTM options. But in the Black-Scholes framework volatility is constant, not stochastic, and the “skew” referred to arises in the distribution of the asset return process, which has heavier tails than the Normal distribution (excess Kurtosis and/or skewness). I realize that this is probably not what the commentator meant, but nonetheless it’s worth heading that possible misunderstanding off at the pass, before we go on.

(ii) I assume that the commentator was referring to the skewness in the volatility process, which is characterized by the LogNormal distribution. But the forecasting tests referenced in the paper are tests of the ability of the model to predict the direction of volatility, i.e. the sign of the change in the level of volatility from the current period to the next period. Thus we are looking at, not a LogNormal distribution, but the difference in two LogNormal distributions with equal mean – and this, of course, has an expectation of zero. In other words, the expected level of volatility for the next period is the same as the current period and the expected change in the level of volatility is zero. You can test this very easily for yourself by generating a large number of observations from a LogNormal process, taking the difference and counting the number of positive and negative changes in the level of volatility from one period to the next. You will find, on average, half the time the change of direction is positive and half the time it is negative.
For instance, the following chart shows the distribution of the number of positive changes in the level of a LogNormally distributed random variable with mean and standard deviation of 0.5, for a sample of 1,000 simulations, each of 10,000 observations. The sample mean (5,000.4) is very close to the expected value of 5,000.

So, a naive predictor will forecast volatility to remain unchanged for the next period and by random chance approximately half the time volatility will turn out to be higher and half the time it will turn out to be lower than in the current period. Hence the default probability estimate for a positive change of direction is 50% and you would expect to be right approximately half of the time. In other words, the direction prediction accuracy of the naive predictor is 50%. This, then, is one of the key benchmarks you use to assess the ability of the model to predict market direction. That is what test statistics like Theil’s-U does – measures the performance relative to the naive predictor. The other benchmark we use is the change of direction predicted by the implied volatility of ATM options.
In this context, the model’s 61% or higher direction prediction accuracy is very significant (at the 4% level in fact) and this is reflected in the Theil’s-U statistic of 0.82 (lower is better). By contrast, Theil’s-U for the Implied Volatility forecast is 1.46, meaning that IV is a much worse predictor of 1-period-ahead changes in volatility than the naive predictor.
On its face, it is because of this exceptional direction prediction accuracy that a simple strategy is able to generate what appear to be abnormal returns using the change of direction forecasts generated by the model, as described in the paper. In fact, the situation is more complicated than that, once you introduce the concept of a market price of volatility risk.









{kind=link}