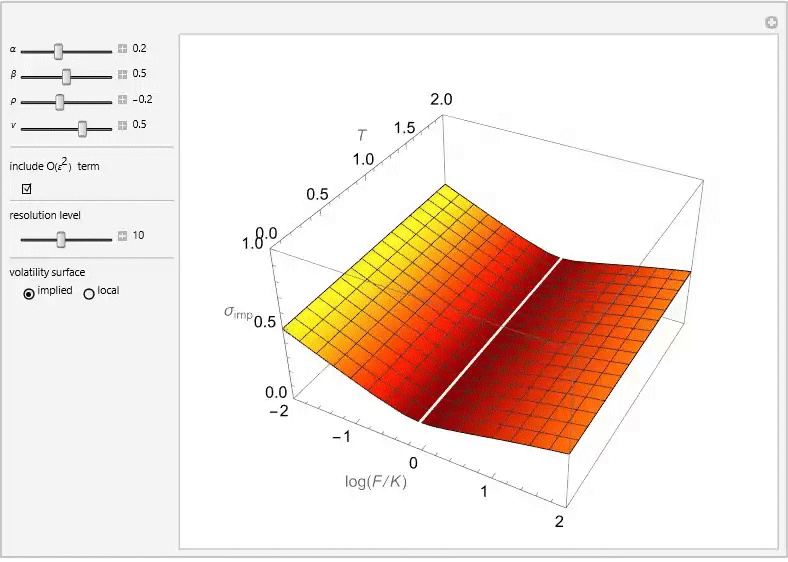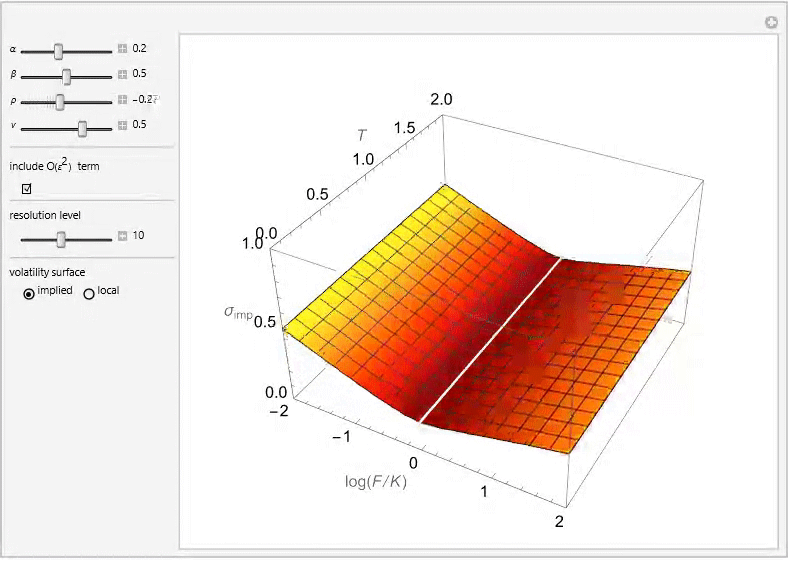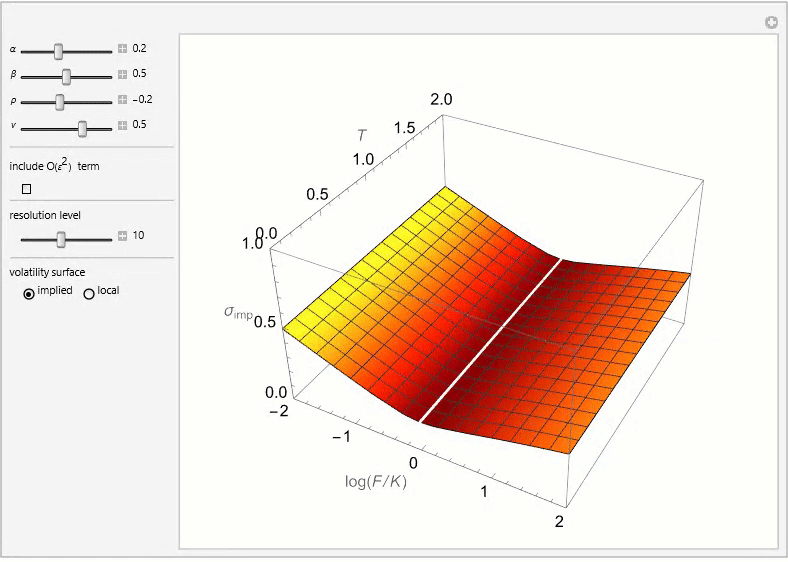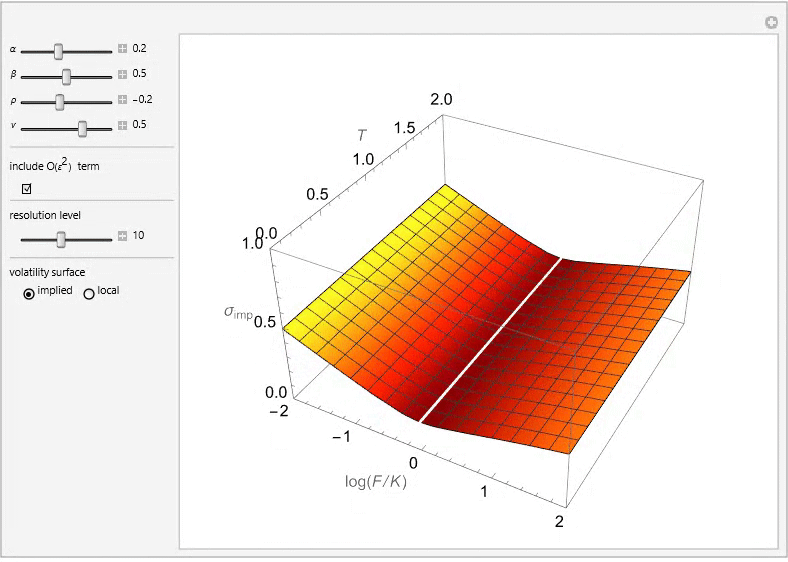
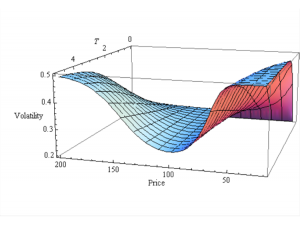
The SABR (Stochastic Alpha, Beta, Rho) model is a stochastic volatility model, which attempts to capture the volatility smile in derivatives markets. The name stands for “Stochastic Alpha, Beta, Rho”, referring to the parameters of the model. The model was developed by Patrick Hagan, Deep Kumar, Andrew Lesniewski, and Diana Woodward.
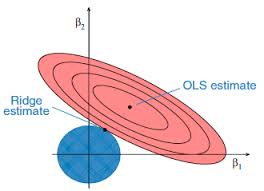
Linear regression is one of the most useful applications in the financial engineer’s tool-kit, but it suffers from a rather restrictive set of assumptions that limit its applicability in areas of research that are characterized by their focus on highly non-linear or correlated variables. The latter problem, referred to as colinearity (or multicolinearity) arises very frequently in financial research, because asset processes are often somewhat (or even highly) correlated. In a colinear system, one can test for the overall significant of the regression relationship, but one is unable to distinguish which of the explanatory variables is individually significant. Furthermore, the estimates of the model parameters, the weights applied to each explanatory variable, tend to be biased.
Over time, many attempts have been made to address this issue, one well-known example being ridge regression. More recent attempts include lasso, elastic net and what I term generalized regression, which appear to offer significant advantages vs traditional regression techniques in situations where the variables are correlated.
In this note, I examine a variety of these techniques and attempt to illustrate and compare their effectiveness.
I have been discussing with some potential academic partners the concept for a new graduate program in High Frequency Finance. The idea is to take the concept of the Computational Finance program developed in the 1990s and update it to meet the needs of students in the 2010s.
The program will offer a thorough grounding in the modeling concepts, trading strategies and risk management procedures currently in use by leading investment banks, proprietary trading firms and hedge funds in US and international financial markets. Students will also learn the necessary programming and systems design skills to enable them to make an effective contribution as quantitative analysts, traders, risk managers and developers.
I would be interested in feedback and suggestions as to the proposed content of the program.
As regards the question of forecasting accuracy discussed in the paper on Forecasting Volatility in the S&P 500 Index, there are two possible misunderstandings here that need to be cleared up. These arise from remarks by one commentator as follows:
“An above 50% vol direction forecast looks good,.. but “direction” is biased when working with highly skewed distributions! ..so it would be nice if you could benchmark it against a simple naive predictors to get a feel for significance, -or- benchmark it with a trading strategy and see how the risk/return performs.”
(i) The first point is simple, but needs saying: the phrase “skewed distributions” in the context of volatility modeling could easily be misconstrued as referring to the volatility skew. This, of course, is used to describe to the higher implied vols seen in the Black-Scholes prices of OTM options. But in the Black-Scholes framework volatility is constant, not stochastic, and the “skew” referred to arises in the distribution of the asset return process, which has heavier tails than the Normal distribution (excess Kurtosis and/or skewness). I realize that this is probably not what the commentator meant, but nonetheless it’s worth heading that possible misunderstanding off at the pass, before we go on.
(ii) I assume that the commentator was referring to the skewness in the volatility process, which is characterized by the LogNormal distribution. But the forecasting tests referenced in the paper are tests of the ability of the model to predict the direction of volatility, i.e. the sign of the change in the level of volatility from the current period to the next period. Thus we are looking at, not a LogNormal distribution, but the difference in two LogNormal distributions with equal mean – and this, of course, has an expectation of zero. In other words, the expected level of volatility for the next period is the same as the current period and the expected change in the level of volatility is zero. You can test this very easily for yourself by generating a large number of observations from a LogNormal process, taking the difference and counting the number of positive and negative changes in the level of volatility from one period to the next. You will find, on average, half the time the change of direction is positive and half the time it is negative.
For instance, the following chart shows the distribution of the number of positive changes in the level of a LogNormally distributed random variable with mean and standard deviation of 0.5, for a sample of 1,000 simulations, each of 10,000 observations. The sample mean (5,000.4) is very close to the expected value of 5,000.
Distribution Number of Positive Direction Changes
So, a naive predictor will forecast volatility to remain unchanged for the next period and by random chance approximately half the time volatility will turn out to be higher and half the time it will turn out to be lower than in the current period. Hence the default probability estimate for a positive change of direction is 50% and you would expect to be right approximately half of the time. In other words, the direction prediction accuracy of the naive predictor is 50%. This, then, is one of the key benchmarks you use to assess the ability of the model to predict market direction. That is what test statistics like Theil’s-U does – measures the performance relative to the naive predictor. The other benchmark we use is the change of direction predicted by the implied volatility of ATM options.
In this context, the model’s 61% or higher direction prediction accuracy is very significant (at the 4% level in fact) and this is reflected in the Theil’s-U statistic of 0.82 (lower is better). By contrast, Theil’s-U for the Implied Volatility forecast is 1.46, meaning that IV is a much worse predictor of 1-period-ahead changes in volatility than the naive predictor.
On its face, it is because of this exceptional direction prediction accuracy that a simple strategy is able to generate what appear to be abnormal returns using the change of direction forecasts generated by the model, as described in the paper. In fact, the situation is more complicated than that, once you introduce the concept of a market price of volatility risk.
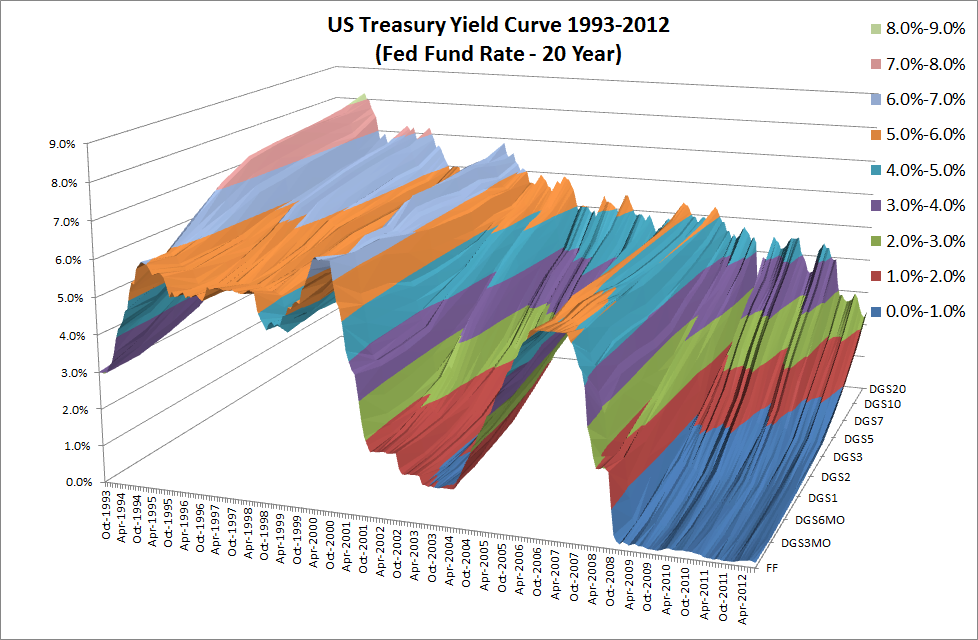
Yield curve models are used to price a wide variety of interest rate-contingent claims. The existence of several different competing methods of curve construction available and there is no single standard method for constructing yield curves and alternate procedures are adopted in different business areas to suit local requirements and market conditions. This fragmentation has often led to confusion amongst some users of the models as to their precise functionality and uncertainty as to which is the most appropriate modeling technique. In addition, recent market conditions, which inter-alia have seen elevated levels of LIBOR basis volatility, have served to heighten concerns amongst some risk managers and other model users about the output of the models and the validity of the underlying modeling methods.
The purpose of this review, which was carried out in conjunction with research analyst Xu Bai, now at Morgan Stanley, was to gain a thorough understanding of current methodologies, to validate their theoretical frameworks and implementation, identify any weaknesses in the current modeling methodologies, and to suggest improvements or alternative approaches that may enhance the accuracy, generality and robustness of modeling procedures.
The LNVM model is a mixture of lognormal models and the model density is a linear combination of the underlying densities, for instance, log-normal densities. The resulting density of this mixture is no longer log-normal and the model can thereby better fit skew and smile observed in the market. The model is becoming increasingly widely used for interest rate/commodity hybrids.
In this review of the model, I examine the mathematical framework of the model in order to gain an understanding of its key features and characteristics.
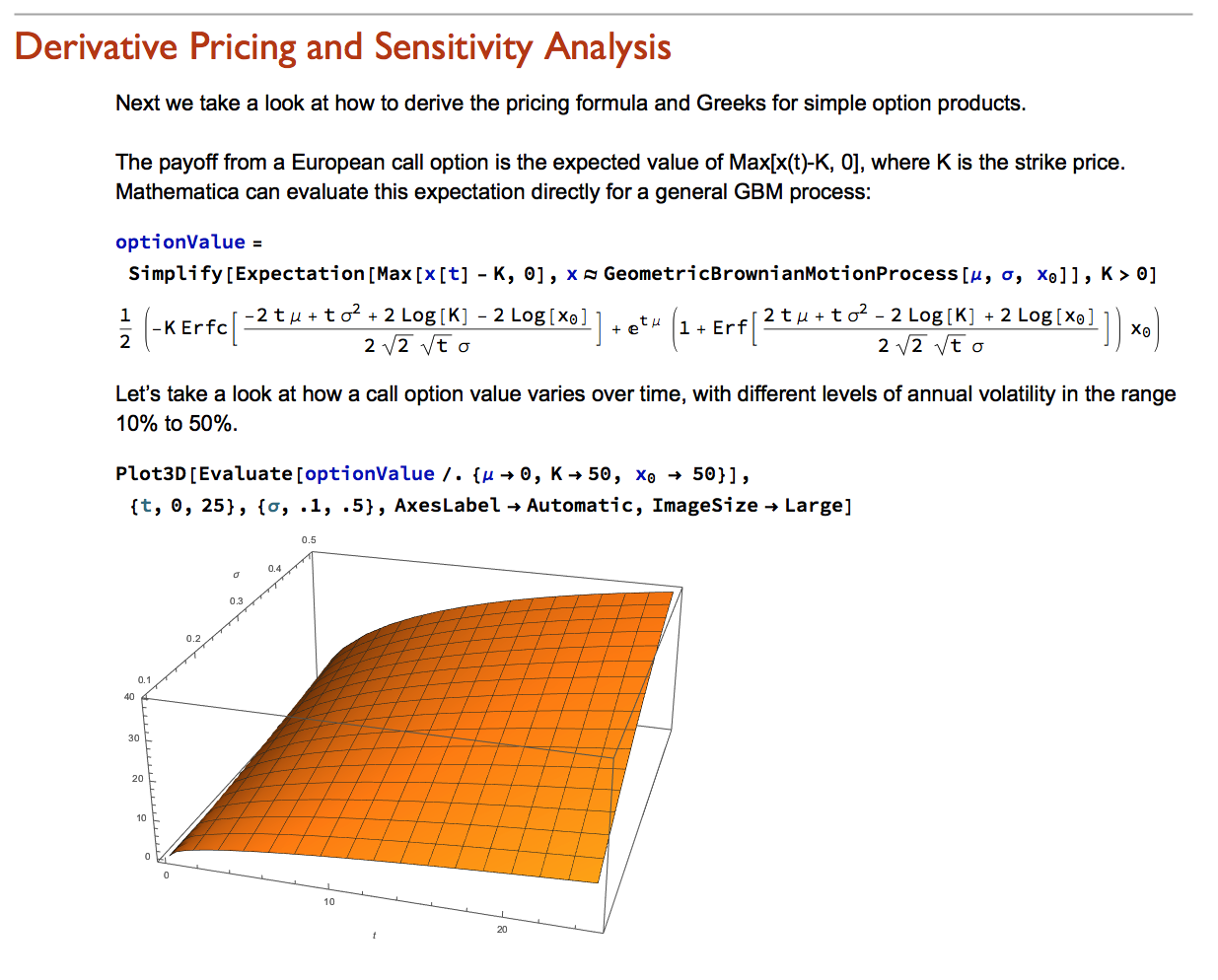
Wolfram Research introduced random processes in version 9 of Mathematica and for the first time users were able to tackle more complex modeling challenges such as those arising in stochastic calculus. The software’s capabilities in this area have grown and matured over the last two versions to a point where it is now feasible to teach stochastic calculus and the fundamentals of financial engineering entirely within the framework of the Wolfram Language. In this post we take a lightening tour of some of the software’s core capabilities and give some examples of how it can be used to create the building blocks required for a complete exposition of the theory behind modern finance.
Conclusion
Financial Engineering has long been a staple application of Mathematica, an area in which is capabilities in symbolic logic stand out. But earlier versions of the software lacked the ability to work with Ito calculus and model stochastic processes, leaving the user to fill in the gaps by other means. All that changed in version 9 and it is now possible to provide the complete framework of modern financial theory within the context of the Wolfram Language.
The advantages of this approach are considerable. The capabilities of the language make it easy to provide interactive examples to illustrate theoretical concepts and develop the student’s understanding of them through experimentation. Furthermore, the student is not limited merely to learning and applying complex formulae for derivative pricing and risk, but can fairly easily derive the results for themselves. As a consequence, a course in stochastic calculus taught using Mathematica can be broader in scope and go deeper into the theory than is typically the case, while at the same time reinforcing understanding and learning by practical example and experimentation.
















{kind=link}