

Posted by androidMarvin:
Genetic programming is an approach to letting the computer generate its own program code, rather than have a person write the program. It doesn’t specifically “find patterns” or rules within data structures. It starts with a number of randomly-constructed (as long as they are mathematically valid) sample programs, evaluates how close each one is to achieving what the desired result program should achieve, then steadily modifies the best matches to the desired target program in order to improve their match to the desired target; the original random attempts “evolve” towards a better match by natural selection, the best ones being selected to act as the basis for the next generation of attempts.
A tree representing a candidate formula could be represented as follows:
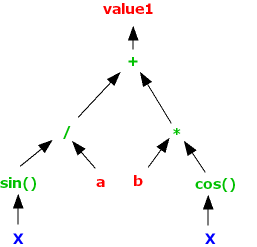
It basically shows the mathematical operations that will be used in the formula, the order in which they are applied, and what values they act on. When the EL Verifier is analysing a statement like
value1 = sin( X ) / a + b * cos( X )
it has to see work out what order the parts of the statement should be evaluated in, which a person sees immediately; effectively, the Verifier constructs the tree diagram above, so that it knows that it has to generate code to make the computer :
- take the value of variable X and pass it through a call to the sin() functio
- take that result, and divide it by the value of a
- take the value of variable X and pass it through a call to the cos() functio
- take that result and multiply it by the value of variable
- take the result of step 2 and the result of step 4 and add the
- that result is the value of Y for the input value of X

Tradestation optimiser would take a single such tree, defining a fixed formula, and attempt to fit it to the data by varying the values of variables a and b. A Genetic Programming optimiser could do the same, but it also has the freedom to change the mathematical operators and the merge points in the tree, and change the shape of the tree to make the formula more or less complex as well; it can adjust both the parameters to the equation and the equation itself in order to evolve it to a better result.
For a mathematical curve fit, a GP optimiser would evaluate each individual tree by applying all the measured X values to the tree’s inputs, compare each output to the measured Y values, and sum a measure of the error over all the data; that sum would be the measure of how well the current tree matches the measure data. The “genetic” part of the name derives from the way it tries to evolve the population of trees its using to find the best.
The main evolution technique is “crossover”. When two parent animals create offspring, each offspring will get part of its DNA from one parent and part from the other; improvement of the species happens if some of the offspring get DNA component combinations that suit the environment better than their parents are suited. The GP optimiser emulates this process by selecting two parent trees, and swapping a section of one of those trees with a section of tree from the other parent, to create two offspring. Eg given parent trees
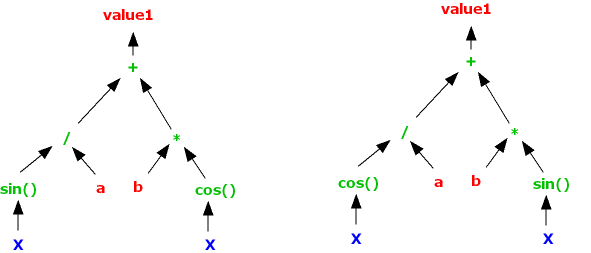
representing equations
value1 = sin( X )/a + b * cos( X )
and
value1 = cos( X ) / a + b * sin( X )
the offspring might be
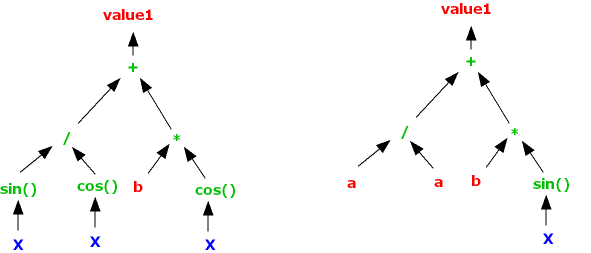
representing equations
value1 = sin( X )/cos( X ) + b * cos( X )
and
value1 = a / a + b * sin( X )
Those specific changes are unlikely to both be an improvement, but that’s the way with random processes; the changes made aren’t guided by any sort of principle, its just a case of “change something, anything, and see if its any better”.
A secondary change process that can be used is “mutation”, in which something about a single tree is simply changed, not swapped. This is intended to introduce diversity, so that if none of the current trees is a particularly good performer, there’s a chance that something radically better might be brought into the pool.
The push trying to steer the evolution towards a better result comes from deciding which parents are allowed to create offspring. The original idea was that all the current trees were ranked in sorted order of their fitness, the worst ones were removed from the population to be replaced by new offspring, amd the trees that were the best performing are selected to be parents – so the weak die, and the strongest breed, hoping their offspring will be at least as good as the parents.
One reservation I have about a product like Adaptrade Builder is that it doesn’t follow this original pattern. It chooses “a few” (2 by default) trees to be considered as parents, by entering a “tournament” and the best tree in the tournament is selected as a parent. This seems to me to reduce the bias towards breeding strength with strength, but I’m no expert.
Rather than being simply mathematical, Builder seems to generate tests for entry and exit orders. It takes arithmetic and comparison operators for granted, and allows trees to be built from technical indicators rather than mathematical functions like sin() and cos(). So where an EL programmer might write
if average( Close, fast ) crosses above Average( ( High + Low )/2, slow ) and CCI( length ) > overbought then buy
Builder would have a tree
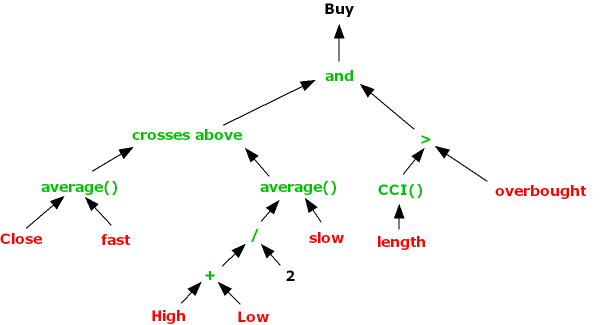
from which an offspring might be generated as :
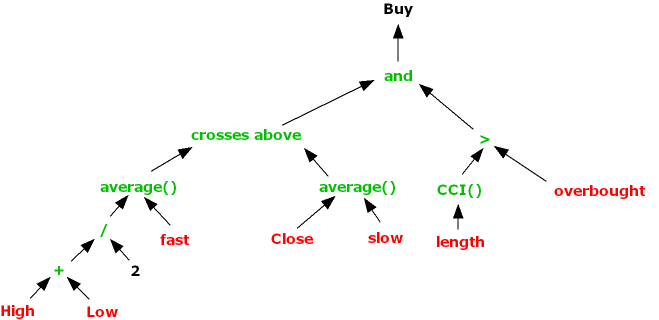
to use a Buy test
if average( ( High + Low )/2, fast ) crosses above Average( Close, slow ) and CCI( length ) > overbought then buy
The structure of the test to go long has changed, but in a random rather than the guided way a human might do when trying to develop a strategy.