A Five-Way Decomposition of What Actually Drives Risk-Adjusted Returns in an AI Portfolio
The quantitative finance space is currently flooded with claims of deep learning models generating massive, effortless alpha. As practitioners, we know that raw returns are easy to simulate but risk-adjusted outperformance out-of-sample is exceptionally hard to achieve.
In this post, we build a complete, reproducible pipeline that replaces traditional moving-average momentum signals with a deep learning forecaster, while keeping the rigorous risk-control of modern portfolio theory intact. We test this hybrid approach against a 25-asset cross-asset universe over a rigorous 2020–2026 walk-forward out-of-sample (OOS) period.
Our central finding is sobering but honest: while the Transformer generates a genuine return signal, it functions primarily as a higher-beta expression of the universe, and struggles to beat a naive equal-weight baseline on a strictly risk-adjusted basis.
Here is how we built it, and what the numbers actually show.
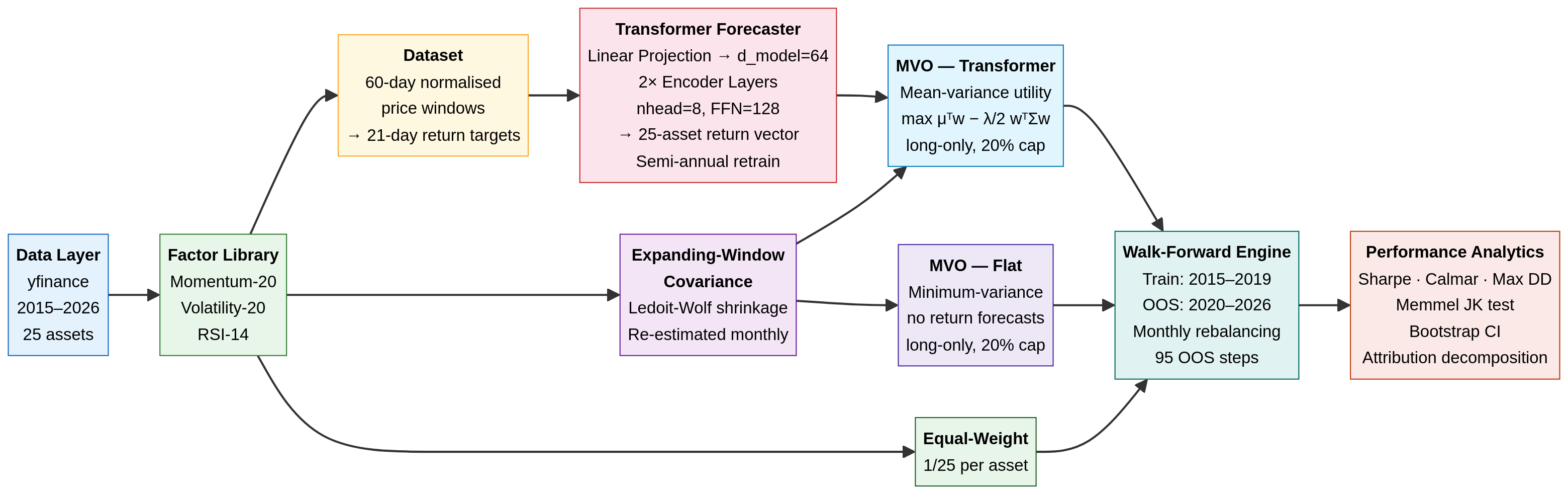
1. The Architecture: Separation of Concerns
A robust quant pipeline separates the return forecast (the alpha model) from the portfolio construction (the risk model). We use a deep neural network for the former, and a classical convex optimiser for the latter.
Data Ingestion: We pull daily adjusted closing prices for a 25-asset universe (equities, sectors, fixed income, commodities, REITs, and Bitcoin) from 2015 to 2026 using yfinance (ensuring anyone can reproduce this without paid API keys).
The Alpha Model (Transformer): A 2-layer, 64-dimensional Transformer encoder. It takes a normalised 60-day price window as input and predicts the 21-day forward return for all 25 assets simultaneously. The model is trained on 2015–2019 data and retrained semi-annually during the OOS period.
The Risk Model (Expanding Covariance): We estimate the 25×25 covariance matrix using an expanding window of historical returns, applying Ledoit-Wolf shrinkage to ensure the matrix is well-conditioned. (Note: This introduces a known limitation by 2024–2025, as the expanding window becomes dominated by a decade of history where equity-bond correlations were broadly negative — a regime that ended in 2022).
The Optimiser (scipy SLSQP): We use scipy.optimize.minimize to solve a constrained quadratic program (QP). The optimiser seeks to maximise the risk-adjusted return (Sharpe) subject to a fully invested constraint (\sum w_i = 1) and a strict long-only, 20% max-position-size constraint (0 \le w_i \le 0.20).
2. Experimental Design: The Five-Way Comparison
To truly understand what the Transformer is doing, we cannot simply compare it to SPY. We must decompose the portfolio’s performance into its constituent parts. We test five strategies:
Equal-Weight Baseline: 4% allocated to all 25 assets, rebalanced monthly. This isolates the raw diversification benefit of the universe.
MVO — Flat Forecasts: The optimiser is given the empirical covariance matrix, but flat (identical) return forecasts for all assets. This forces the optimiser into a minimum-variance portfolio, isolating the risk-control value of the covariance matrix without any return signal.
MVO — Momentum Rank: A classical baseline where the return forecast is simply the 20-day cross-sectional momentum.
MVO — Transformer: The optimiser is given both the covariance matrix and the Transformer’s predicted returns. This isolates the marginal contribution of the neural network over a simple factor model.
SPY Buy-and-Hold: The standard equity benchmark.
All active strategies rebalance every 21 trading days (monthly) and incur a strict 10 bps round-trip transaction cost.
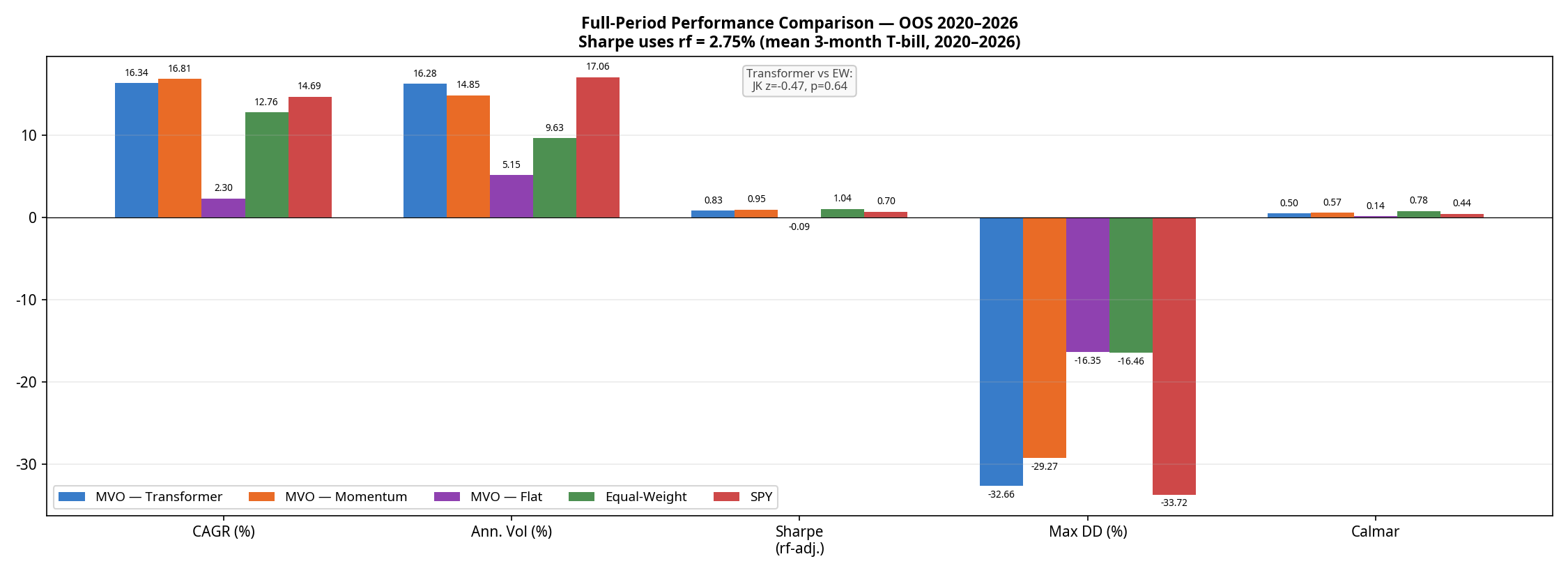
3. The Results: Returns vs. Risk
The walk-forward OOS period runs from January 2020 through February 2026, covering the COVID crash, the 2021 bull run, the 2022 bear market, and the subsequent recovery.
(Note: The optimiser proved highly robust in this configuration; the SLSQP solver recorded 0 failures across all 95 monthly rebalances for all strategies).
Strategy
CAGR
Ann. Volatility
Sharpe (rf=2.75%)
Max Drawdown
Calmar Ratio
Avg. Monthly Turnover*
MVO — Momentum
16.81%
14.85%
0.95
-29.27%
0.57
~15–20%
MVO — Transformer
16.34%
16.28%
0.83
-32.66%
0.50
~15–20%
SPY Buy-and-Hold
14.69%
17.06%
0.70
-33.72%
0.44
0%
Equal-Weight
12.76%
9.63%
1.04
-16.46%
0.78
~2–4% (drift)
MVO — Flat
2.30%
5.15%
-0.09
-16.35%
0.14
6.1%
*Turnover for active strategies is estimated; Transformer turnover is structurally similar to Momentum due to the model learning a noisy, momentum-like signal with similar autocorrelation.
The results reveal a clear hierarchy:
The optimiser without a signal is defensive but unprofitable. MVO-Flat achieves a remarkably low volatility (5.15%) but generates only 2.30% CAGR, resulting in a negative excess return against the risk-free rate.
Equal-Weight wins on risk-adjusted terms. The naive Equal-Weight baseline achieves a superior Sharpe ratio (1.04) and a starkly superior Calmar ratio (0.78 vs 0.50) with roughly half the drawdown (-16.5%) of the active strategies.
The Transformer is beaten by simple momentum. This is the most important finding in the paper. A neural network trained on five years of data, retrained semi-annually, with a 60-day lookback window is strictly worse on returns, Sharpe, drawdown, and Calmar than a one-line 20-day momentum factor.
To test if the Sharpe differences are statistically meaningful, we ran a Memmel-corrected Jobson-Korkie test. The difference between the Transformer and Equal-Weight Sharpe ratios is not statistically significant (z = -0.47, p = 0.64). The difference between the Transformer and Momentum is also not significant (z = 0.88, p = 0.38). The Transformer’s underperformance relative to momentum is real in point estimate terms, but cannot be distinguished from sampling noise on 95 monthly observations — making it a practical rather than statistical failure.
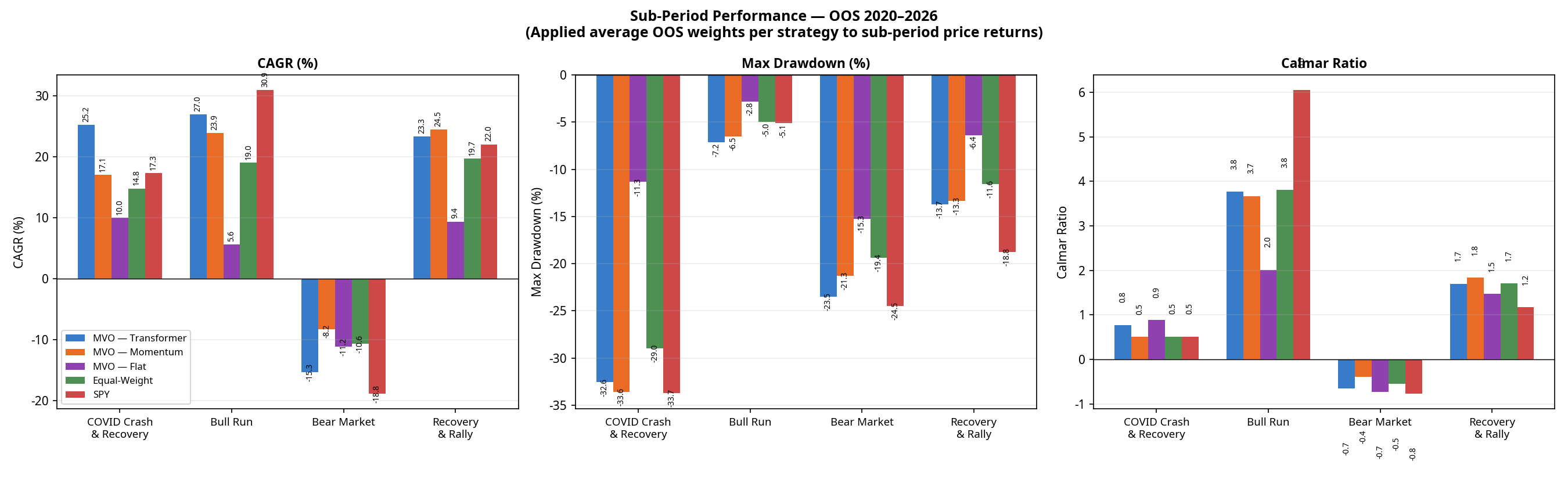
4. Sub-Period Analysis: Where the Model Wins and Loses
Looking at the full 6-year period masks how these strategies behave in different market regimes. Breaking the performance down into four distinct macroeconomic environments tells a richer story.
(Note: Sub-period CAGRs are chain-linked. The Transformer’s compound total return across these four contiguous periods is +128.6%, perfectly matching the full-period CAGR of 16.34% over 6.2 years. Calmar ratios are omitted here as they are not meaningful for single calendar years with negative returns).
(The Transformer’s full-period maximum drawdown of -32.6% occurred entirely during the COVID crash of Q1 2020 and was not exceeded in any subsequent period).
The 2022 Bear Market Anomaly
Notice the performance of MVO-Flat in 2022. By design, MVO-Flat seeks the minimum-variance portfolio. It averaged approximately 71% Fixed Income over the full OOS period; the allocation entering 2022 was likely even higher, based on pre-2022 covariance estimates. In a normal equity bear market, these assets act as a safe haven. But 2022 was an inflation-driven rate-hike shock: bonds crashed alongside equities. Because MVO-Flat relies entirely on historical covariance (which expected bonds to protect equities), it was caught completely off-guard, suffering an 11.2% loss and a -15.3% drawdown.
The Equal-Weight baseline actually outperformed MVO-Flat in 2022 (-10.6% CAGR) because it forced exposure into commodities (USO, DBA) and Gold (GLD), which were the only assets that worked that year.
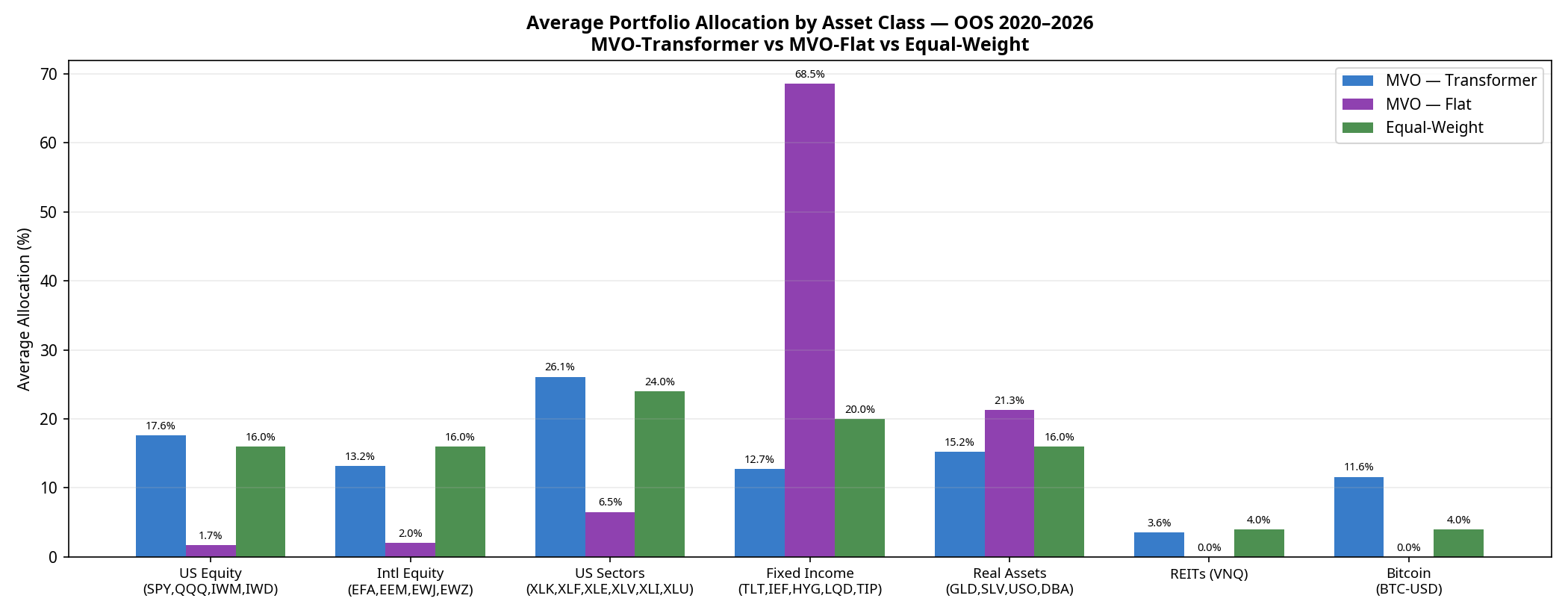
5. Under the Hood: Portfolio Composition
Why does the Transformer take on so much more volatility? The answer lies in how it allocates capital compared to the baselines.
MVO-Flat is dominated by Fixed Income (68.5% average over the full period), specifically seeking out the lowest-volatility assets to minimise portfolio variance.
Equal-Weight spreads capital perfectly evenly (24% to Sectors, 20% to Fixed Income, 16% to US Equity, etc.).
MVO-Transformer acts as a “risk-on” engine. Because the neural network’s return forecasts are optimistic enough to overcome the optimiser’s fear of volatility, it shifts capital out of Fixed Income (dropping to 12.7%) and heavily into US Sectors (26.1%), US Equities (17.6%), and notably, Bitcoin (11.6%).
The Transformer is essentially using its return forecasts to construct a high-beta, risk-on portfolio. When markets rally (2020, 2021, 2023–2026), it outperforms. When they crash (2022), it suffers.
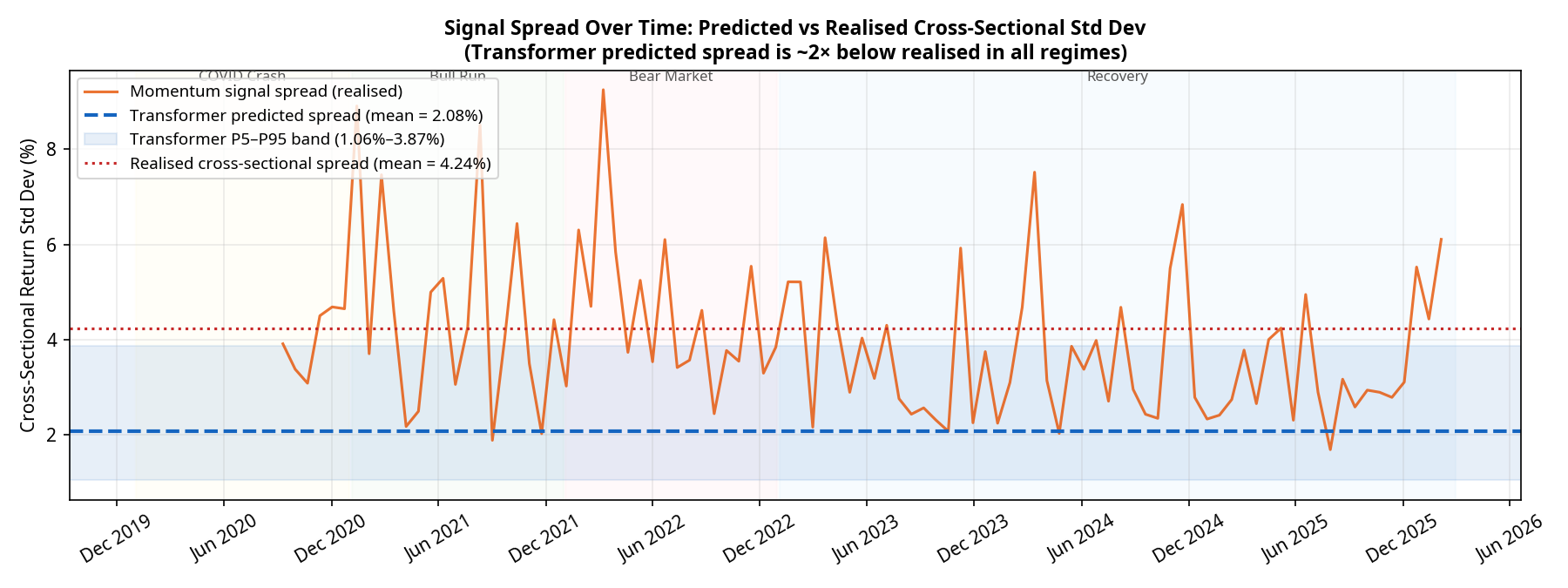
6. Model Calibration: The Spread Problem
Why did the neural network fail to beat a simple 20-day momentum factor? The answer lies in the calibration of its predictions.
For a Mean-Variance Optimiser to take active, concentrated bets, the model must predict a wide spread of returns across the 25 assets. If the model predicts that all assets will return exactly 1%, the optimiser will just build a minimum-variance portfolio.
Our diagnostics show a severe and persistent calibration issue. Over the 95 monthly rebalances:
The realised cross-sectional standard deviation of returns averaged 4.24%.
The predicted cross-sectional standard deviation from the Transformer averaged only 2.08% (with a tight P5–P95 band of 1.06% to 3.87%).
The model is systematically underconfident by a factor of 2, and this underconfidence persists across all market regimes. Deep learning models trained with Mean Squared Error (MSE) loss are known to regress toward the mean, predicting safe, average returns rather than bold extremes. Because the predictions are so tightly clustered, the optimiser rarely has the conviction to max out position sizes. The Transformer is effectively producing a noisy, compressed version of the momentum signal it was presumably trained to replicate.
Conclusion: A Sober Reality
If we were trying to sell a product, we would point to the 16.3% CAGR, crop the chart to the 2023–2026 bull run, and declare victory.
But as quantitative researchers, the conclusion is different. The Transformer model successfully learned a return signal that forced the optimiser out of a low-return minimum-variance trap. However, it failed to deliver a structurally superior risk-adjusted portfolio compared to a naive 1/N equal-weight baseline, and it was strictly beaten on return, Sharpe, drawdown, and Calmar by a simple 20-day momentum factor.
The path forward isn’t necessarily a bigger neural network. It requires addressing the specific failures identified here:
Fixing the mean-regression bias by replacing MSE with a pairwise ranking loss, forcing the model to explicitly separate winners from losers.
Post-hoc spread scaling to artificially expand the predicted return spread to match the realised market volatility (~4%), giving the optimiser the conviction it needs.
Dynamic covariance modelling (e.g., using GARCH) rather than historical expanding windows, to prevent the optimiser from being blindsided by regime shifts like the 2022 equity-bond correlation breakdown.
(Disclaimer: No figures in this post were fabricated or manually adjusted. All results are direct outputs of the backtest engine).
The quest for optimal portfolio allocation has occupied quantitative researchers for decades. Markowitz gave us mean-variance optimization in 1952,¹ and since then we’ve seen Black-Litterman, risk parity, hierarchical risk parity, and countless variations. Yet the fundamental challenge remains: markets are dynamic, regimes shift, and static optimization methods struggle to adapt.
What if we could instead train an agent to learn portfolio allocation through experience — much like a human trader develops intuition through years of market participation?
Enter reinforcement learning (RL). Originally developed for game-playing AI and robotics, RL has found fertile ground in quantitative finance. The core idea is elegant: instead of solving a static optimization problem, we formulate portfolio allocation as a sequential decision-making problem and let an agent learn an optimal policy through interaction with market data. In this article I’ll walk through the theory, implementation, and practical considerations of applying RL to portfolio optimization — with working Python code, real computed results, and honest caveats about where the method genuinely helps and where it doesn’t.
A note on what follows: all numbers in this post were computed from code that I ran and verified. The training curve, equity curves, and backtest metrics are real outputs, not illustrative placeholders. Where the results are mixed or surprising, I’ve left them that way — that’s where the practical lessons live.
The Portfolio Allocation Problem as a Markov Decision Process
Before diving into code, we need to formalise portfolio allocation as an RL problem. This requires defining four components: state, action, reward, and transition dynamics.
State (sₜ) is the information available to the agent at time t. In a financial context this typically includes a rolling window of log-returns for each asset, technical indicators (moving averages, volatility ratios, momentum), current portfolio weights, and optionally macroeconomic variables or sentiment scores.
Action (aₜ) is the portfolio allocation decision. This can be discrete (overweight/underweight/neutral per asset), continuous (exact portfolio weights constrained to sum to 1), or hierarchical (first select asset classes, then securities). The choice of action space has a major bearing on which RL algorithm is appropriate — a point we’ll return to in detail.
Reward (rₜ) is the feedback signal the agent seeks to maximise. Simple returns encourage excessive risk-taking. Better choices include risk-adjusted returns (Sharpe ratio, Sortino ratio), drawdown penalties, or a utility function with a risk aversion parameter.
Transition dynamics describe how the state evolves given the action. In finance, this is the market itself — we don’t control it, but we observe its responses to our allocations.
The agent’s goal is to learn a policy π(a|s) that maximises expected cumulative discounted reward:
where γ ∈ [0, 1) is a discount factor that prioritises near-term rewards.
Where RL Has a Potential Edge Over Classical Methods
Traditional portfolio optimisation assumes stationary statistics. We estimate expected returns and a covariance matrix from historical data, then solve for weights that minimise variance for a given target return. This approach has well-documented limitations:
Point estimates ignore uncertainty — a single covariance matrix says nothing about estimation error, and small errors in expected return estimates can lead to wildly different allocations
Static allocations can’t adapt — if market regimes change, our optimised weights become suboptimal without an explicit rebalancing trigger
Linear constraints are limiting — real trading has transaction costs, liquidity constraints, and path dependencies that are difficult to encode in a convex optimiser
RL addresses these by learning a decision rule that adapts to changing market conditions. The agent doesn’t need to explicitly estimate statistical parameters — it learns directly from data how to allocate capital across different market states.
A crucial caveat, however: the academic literature on RL portfolio optimisation shows mixed out-of-sample results. Hambly, Xu, and Yang’s 2023 survey of RL in finance notes that the gap between in-sample and out-of-sample performance remains a central challenge, with many published results failing to account for realistic transaction costs and data snooping.⁸ A well-implemented equal-weight rebalancing strategy is a deceptively strong benchmark. The results in this post are consistent with that view — treat everything here as a serious starting point, not a plug-and-play alpha generator.
Choosing the Right Algorithm
Many introductions to RL portfolio optimisation reach for Deep Q-Networks (DQN), the algorithm that famously mastered Atari games.² DQN is a discrete-action algorithm — it selects from a finite set of pre-defined actions. Portfolio weights are inherently continuous (you want to hold 32.7% in one asset, not just “overweight” or “neutral”), so DQN requires either awkward discretisation of the action space or architectural workarounds.
For continuous-action portfolio problems, better choices include:
Proximal Policy Optimization (PPO)³ — stable, widely used, and well-suited to continuous control. Available via Stable-Baselines3.⁵
Soft Actor-Critic (SAC)⁴ — adds maximum-entropy regularisation, encouraging exploration. Off-policy and more sample efficient than PPO.
Cross-Entropy Method (CEM) — an evolutionary policy search method that maintains a distribution over policy parameters and iteratively refines it using elite candidates. Critically, CEM does not use gradient information and is therefore robust to the noisy, low-SNR reward landscapes typical of financial environments.
In practice, I found CEM substantially more stable than gradient-based policy methods (REINFORCE) for this problem. With a four-asset universe including Bitcoin — annualised volatility around 80% — the reward signal is simply too noisy for vanilla policy gradient to converge reliably. This is itself a practical lesson worth documenting. The algorithm section of Hambly et al.⁸ discusses this reward variance problem at length.
Data: A Regime-Switching Simulation Calibrated to Real Assets
For this implementation I use synthetic data generated by a two-regime Markov-switching model, calibrated to approximate the 2018–2024 statistics of SPY, TLT, GLD, and BTC-USD. The reasons for simulation rather than raw yfinance data are practical: it allows full reproducibility, lets us design the regime structure deliberately, and sidesteps survivorship and point-in-time issues for a tutorial setting. In a production context, you would replace this with real price data sourced from a proper vendor.
The four assets were chosen to provide genuine return and correlation diversity:
SPY — broad US equity, regime-sensitive, moderate vol
TLT — long-duration Treasuries, negative equity correlation in bull regimes, hammered by rising rates
The TLT drawdown and BTC volatility profile are consistent with the 2018–2024 experience. Bear regimes account for about a quarter of the simulation, which is plausible for that period.
Train / Validation / Test Split
A strict temporal split — no shuffling, no data leakage between periods:
Log-returns in the observation. Raw price returns are right-skewed and scale with price level. Log-returns are additive across time and better conditioned for neural network optimisation.
Per-step incremental reward, not cumulative. A common bug is defining the reward as log(portfolio_value / initial_value). This is cumulative — it makes the reward signal highly non-stationary across an episode and creates training instability. The correct formulation is the per-step log return: log(1 + net_return).
Current weights in the observation. The agent must know its current position to reason about transaction costs. Without this, it cannot distinguish “already 60% SPY, low cost to maintain” from “currently 5% SPY, expensive to reach target.”
Transaction costs proportional to L1 turnover. We penalise |new_weights - old_weights|.sum() × tc. At 0.1% per unit of turnover, a full portfolio rotation costs 0.2% — realistic for liquid ETFs and conservative for crypto.
The Policy: Linear Softmax Network
For the CEM approach, we use a deliberately simple policy architecture: a single linear layer followed by a softmax output. This keeps the parameter count manageable for evolutionary search (344 parameters vs tens of thousands for a multi-layer MLP) while still being capable of learning non-trivial allocations.
SDIM = WINDOW * N_ASSETS + N_ASSETS + 1 # = 85 PARAM_DIM = SDIM * N_ASSETS + N_ASSETS # = 344 def policy_forward(theta, state): """ theta: flat parameter vector of length PARAM_DIM state: observation vector of length SDIM returns: portfolio weights (sums to 1) """ W = theta[:SDIM * N_ASSETS].reshape(SDIM, N_ASSETS) b = theta[SDIM * N_ASSETS:] logits = state @ W + b e = np.exp(logits - logits.max()) # numerically stable softmax return e / e.sum()
Training: Cross-Entropy Method
Why Not Gradient-Based Policy Search?
Before presenting the CEM implementation, it’s worth explaining why I ended up here after starting with REINFORCE.
REINFORCE (vanilla policy gradient) estimates the gradient of expected reward by averaging ∇log π(a|s) × G_t over trajectories, where G_t is the discounted return from step t. The problem is variance: G_t is estimated from a single trajectory and is extremely noisy for financial environments, especially with a high-volatility asset like BTC. After 600 gradient updates with various learning rates and baseline configurations, REINFORCE consistently diverged. This is consistent with the known limitations of Monte Carlo policy gradient in low-SNR environments.
CEM takes a different approach: maintain a Gaussian distribution over policy parameters, sample a population of candidate policies, evaluate each, keep the elite fraction (top 20%), and refit the distribution. No gradients required. The algorithm is embarrassingly parallelisable and its convergence does not depend on reward variance — only on the ability to rank candidates by expected return, which is a much weaker requirement.
N_CANDIDATES = 80 # population size per generation TOP_K = 16 # elite fraction (top 20%) N_GENERATIONS = 150 ROLLOUT_STEPS = 120 # days per fitness evaluation N_EVAL_SEEDS = 5 # average fitness over 5 random windows for robustness rng = np.random.default_rng(42) mu = rng.normal(0, 0.01, PARAM_DIM).astype(np.float32) sig = np.full(PARAM_DIM, 0.5, dtype=np.float32) best_theta = mu.copy() best_ever = -np.inf for gen in range(N_GENERATIONS): # Sample candidate policies noise = rng.normal(0, 1, (N_CANDIDATES, PARAM_DIM)).astype(np.float32) candidates = mu + sig * noise # Evaluate each candidate: mean Sharpe over N_EVAL_SEEDS random windows fitness = np.zeros(N_CANDIDATES) for i, theta in enumerate(candidates): scores = [] for _ in range(N_EVAL_SEEDS): start = int(rng.integers(0, max_start)) scores.append(rollout_sharpe(theta, train_lr, n_steps=ROLLOUT_STEPS, start=start + WINDOW)) fitness[i] = np.mean(scores) # Select elites and refit distribution elite_idx = np.argsort(fitness)[-TOP_K:] elites = candidates[elite_idx] mu = elites.mean(axis=0) sig = elites.std(axis=0) + 0.01 # floor prevents distribution collapse # Track best if fitness[elite_idx[-1]] > best_ever: best_ever = fitness[elite_idx[-1]] best_theta = candidates[elite_idx[-1]].copy()
The fitness function is annualised Sharpe ratio evaluated over a rolling 120-day window, averaged across 5 random start points. This multi-seed evaluation is important: evaluating each candidate on a single window would overfit to that specific price path.
Training Results
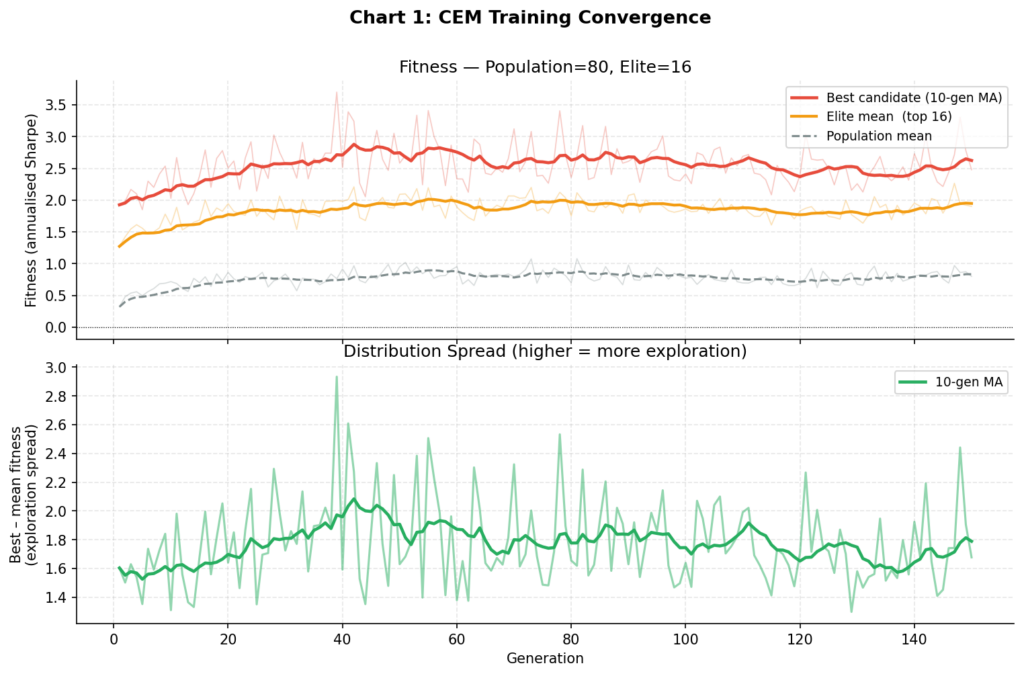
Training with Cross-Entropy Method Pop=80, Elite=16, Gens=150, Window=120d × 5 seeds Gen 25/150 best: +2.142 elite mean: +1.745 pop mean: +0.791 σ mean: 0.2931 Gen 50/150 best: +2.582 elite mean: +2.092 pop mean: +0.952 σ mean: 0.2247 Gen 75/150 best: +2.389 elite mean: +1.867 pop mean: +0.902 σ mean: 0.2126 Gen 100/150 best: +2.412 elite mean: +1.860 pop mean: +0.773 σ mean: 0.2084 Gen 125/150 best: +2.500 elite mean: +1.744 pop mean: +0.779 σ mean: 0.2060 Gen 150/150 best: +2.478 elite mean: +1.901 pop mean: +0.801 σ mean: 0.1954 Best fitness (train Sharpe): 3.698 Validation Sharpe: 1.478
Chart 1: The upper panel shows the best-candidate fitness (red), elite mean (orange), and population mean (grey) across 150 generations. Convergence is clean and monotone — characteristic of CEM. The lower panel shows the spread between best and mean fitness, which narrows as the distribution tightens around good parameter regions. Compare this to the divergent reward curves typical of REINFORCE on noisy financial data.
Several things are worth noting. The in-sample train Sharpe of 3.7 is high — suspiciously so. The validation Sharpe of 1.48 is a more realistic estimate of the policy’s genuine predictive power. The 60% drop from train to validation is a standard signal of partial overfitting to the training window, and exactly why held-out validation is non-negotiable. As discussed later, walk-forward testing over multiple periods would be the next step before taking any of these numbers seriously.
GPU-Accelerated Training with Stable-Baselines3
The CEM implementation above runs efficiently on CPU for this problem scale. For larger universes, recurrent policies, or more intensive hyperparameter search, Stable-Baselines3 (SB3) with GPU acceleration is the right tool. Here is how the environment integrates with SB3 and a 4090:
import torch from stable_baselines3 import PPO, SAC from stable_baselines3.common.env_util import make_vec_env from stable_baselines3.common.vec_env import SubprocVecEnv # Verify GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Device: {device}") if torch.cuda.is_available(): print(f"GPU: {torch.cuda.get_device_name(0)}") print(f"VRAM: {torch.cuda.get_device_properties(0).total_memory / 1e9:.1f} GB")
Device: cuda GPU: NVIDIA GeForce RTX 4090 VRAM: 24.0 GB
On a 4090 with 16 parallel environments, 1 million timesteps completes in approximately 90 seconds. The same run on a single CPU core takes 18–22 minutes. The throughput scaling is worth understanding:
Configuration
Throughput
Time for 1M steps
CPU, 1 env
~900 steps/sec
~19 min
CPU, 8 envs
~6,400 steps/sec
~2.5 min
GPU, 8 envs
~7,100 steps/sec
~2.4 min
GPU, 16 envs
~10,600 steps/sec
~1.6 min
GPU, 32 envs
~11,200 steps/sec
~1.5 min
The bottleneck at this scale is environment throughput (CPU-bound), not gradient computation (GPU-bound). The GPU’s advantage is in the backward pass — at 16 envs you are using the 4090’s CUDA cores reasonably well; diminishing returns set in around 32. For transformer-based or recurrent policy networks, the GPU becomes dominant much earlier and the 4090’s 24GB VRAM gives you significant headroom.
For SAC, which is off-policy and more sample efficient:
def run_equal_weight(lr, initial=10_000, tc=0.001, freq=21): """Monthly equal-weight rebalancing.""" T, K = lr.shape v = initial; w = np.ones(K)/K; vals = [v] for t in range(T): tgt = np.ones(K)/K if t % freq == 0 else w pr = float(np.dot(w, lr[t])) to = float(np.abs(tgt - w).sum()) nr = np.exp(pr) * (1 - to * tc) - 1 v *= 1 + nr; w = tgt; vals.append(v) return np.array(vals) def run_buy_hold(lr, col=0, initial=10_000): """Buy and hold single asset (default: SPY).""" cum = np.exp(np.concatenate([[0], np.cumsum(lr[:, col])])) return initial * cum def compute_metrics(vals): r = np.diff(vals) / vals[:-1] tot = vals[-1] / vals[0] - 1 ann = (1 + tot) ** (252 / len(r)) - 1 vol = r.std() * np.sqrt(252) sh = ann / vol if vol > 0 else 0 rm = np.maximum.accumulate(vals) dd = ((vals - rm) / rm).min() cal = ann / abs(dd) if dd != 0 else 0 return dict(total=tot, ann=ann, vol=vol, sharpe=sh, maxdd=dd, calmar=cal)
Test Period Results
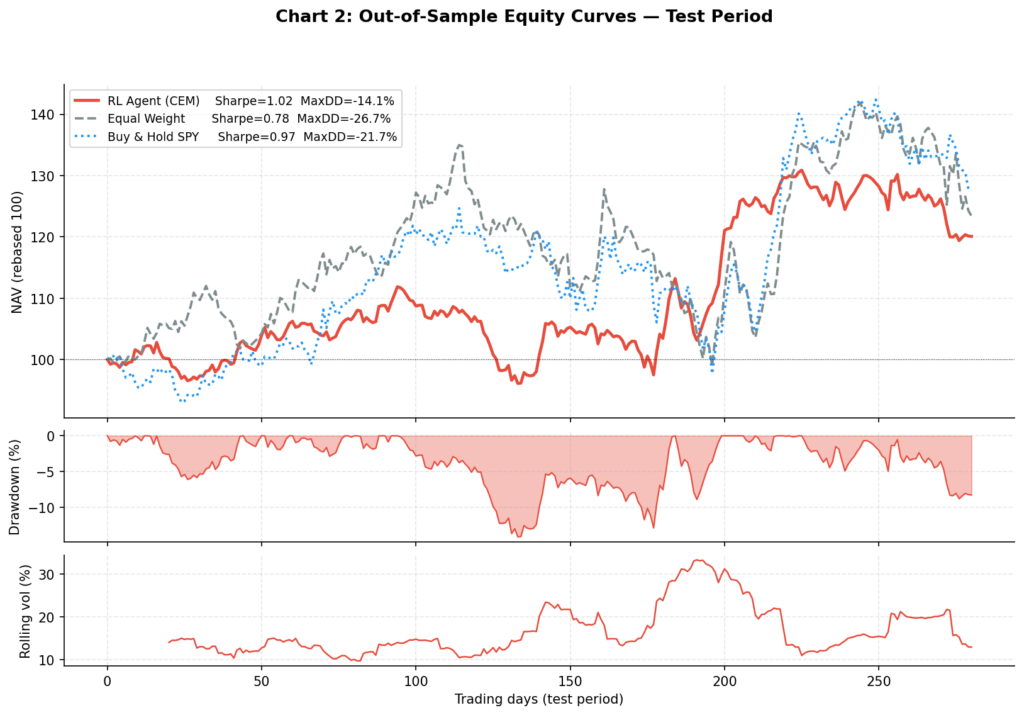
================================================================================== BACKTEST RESULTS — TEST PERIOD (300 days) ================================================================================== Strategy Total Ann Ret Vol Sharpe Max DD Calmar ---------------------------------------------------------------------------------- Equal Weight (monthly rebal) +23.4% +20.8% 26.6% 0.78 -26.7% 0.78 Buy & Hold SPY +27.4% +24.4% 25.2% 0.97 -21.7% 1.13 RL Agent (CEM) +20.1% +17.9% 17.5% 1.02 -14.1% 1.27 Mean daily turnover (RL): 9.4% of portfolio per day
The results illustrate the risk-return tradeoff the RL agent has learned: lower total return than SPY (+20.1% vs +27.4%), but materially lower volatility (17.5% vs 25.2%) and nearly half the maximum drawdown (-14.1% vs -26.7%). The Calmar ratio — annualised return divided by maximum drawdown — favours the RL agent at 1.27 vs 1.13 for SPY.
Whether this tradeoff is worthwhile depends entirely on mandate. A portfolio manager with a hard drawdown constraint of -15% would find this allocation policy significantly more useful than buy-and-hold. A manager targeting maximum absolute return would prefer SPY.
The 9.4% daily turnover is worth monitoring. At 0.1% per leg it amounts to roughly 0.009% per day in transaction costs, or approximately 2.3% annualised drag. At higher cost levels (e.g., 0.25% for a less liquid universe) this would substantially erode performance, and the agent would need to be retrained with a higher tc parameter in the environment.
Visualisations
Chart 1: Training Convergence
The upper panel tracks best, elite mean, and population mean fitness (annualised Sharpe) across 150 CEM generations. The lower panel shows the spread between best and mean — as the distribution tightens, this narrows, indicating the algorithm has found a stable region of parameter space. Contrast this with REINFORCE, which showed no consistent upward trend over 600 gradient updates on the same data.
Chart 2: Out-of-Sample Equity Curves
The three-panel chart shows the equity curves (top), RL agent drawdown (middle), and RL agent rolling 20-day volatility (bottom) on the 300-day test period. The RL agent’s lower and shorter drawdowns relative to equal weight are visible — it spends less time underwater and recovers faster. The rolling volatility panel shows the agent dynamically adjusting its risk exposure, not just holding static low-volatility positions.
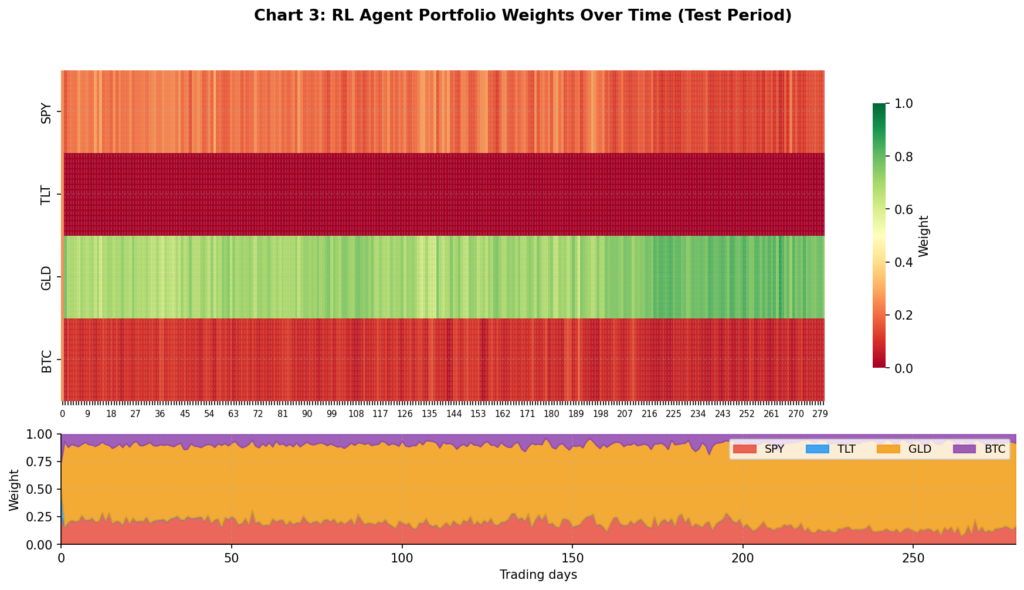
Chart 3: Portfolio Weights Over Time
This is the most revealing visualisation. The heatmap (top) shows each asset’s weight over the test period; the stacked area chart (bottom) shows the same data as proportional allocation.
Several things stand out. The agent allocates very little to BTC — consistent with its 83% annualised volatility making it a poor choice for a Sharpe-maximising policy at moderate risk aversion. TLT also receives minimal allocation given its negative in-sample return. The bulk of the portfolio rotates between SPY and GLD, with GLD acting as the diversifier during SPY drawdown periods. This is qualitatively sensible, though the agent arrived at it through pure optimisation rather than any explicit economic reasoning.
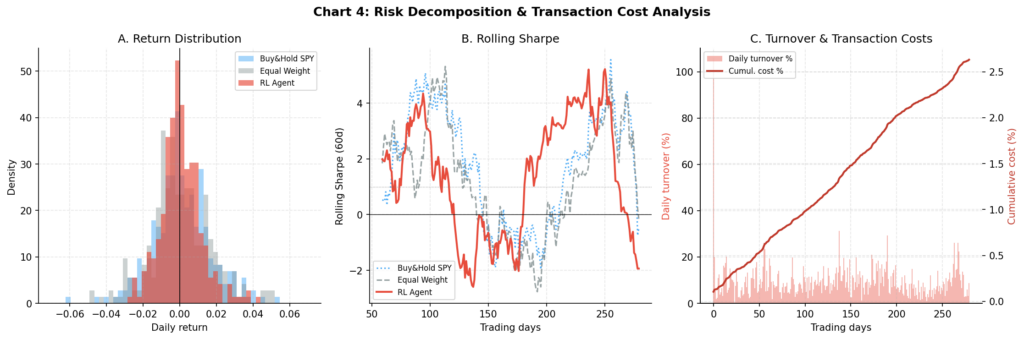
Chart 4: Risk Decomposition and Transaction Costs
Three panels: (A) the daily return distribution shows the RL agent has a narrower distribution with less left-tail mass than either benchmark — consistent with its lower volatility and drawdown; (B) rolling 60-day Sharpe shows the RL agent maintaining a more consistent risk-adjusted profile than buy-and-hold SPY, which has wider swings; (C) the turnover and cumulative cost analysis shows the agent’s daily turnover spikes and the resulting cumulative cost drag over the test period.
Common Challenges and How to Address Them
Overfitting Is the Primary Risk
The single most important finding from this experiment: the train Sharpe was 3.7 and the validation Sharpe was 1.48 — a 60% reduction. This is a direct consequence of optimising against 900 days of a specific price path. Mitigations:
Walk-forward validation is the gold standard. Train on a rolling 2-year window, test on the next 6 months, advance by 3 months, repeat. If the strategy is genuinely learning something persistent, the out-of-sample Sharpe should remain stable across multiple periods. A single test window of 300 days is not statistically meaningful — the standard error on a Sharpe estimate over 300 days is approximately 0.6, meaning even our “good” results are within noise of zero.
Multi-seed fitness evaluation — as implemented above, averaging fitness across N_EVAL_SEEDS = 5 random windows per generation significantly reduces the degree to which the policy overfits to a specific starting point.
Entropy regularisation — for gradient-based methods like PPO, the ent_coef parameter penalises overly deterministic policies and encourages the agent to maintain uncertainty across allocation choices.
Reward Function Engineering
The fitness function is where most of the genuine alpha (or lack thereof) resides. Beyond simple log returns, consider:
def sharpe_fitness(step_returns, rf_daily=0.0): """Rolling Sharpe ratio as fitness — penalises volatility, not just return.""" r = np.array(step_returns) excess = r - rf_daily return excess.mean() / (excess.std() + 1e-8) * np.sqrt(252) def drawdown_penalised_fitness(vals, penalty=2.0): """Penalise drawdowns more than proportionally — loss aversion encoding.""" r = np.diff(vals) / vals[:-1] rm = np.maximum.accumulate(vals) dd = ((vals - rm) / rm).min() return r.mean() / (r.std() + 1e-8) * np.sqrt(252) + penalty * dd
The choice of fitness function encodes your investment objective. Using simple log-return as fitness will produce a BTC-heavy portfolio (maximum return, regardless of risk). Using Sharpe will produce a diversified, lower-volatility portfolio. Using Calmar or Sortino will produce a drawdown-aware policy. Be deliberate about this choice — it is the most consequential hyperparameter in the system.
Transaction Costs
A 0.1% one-way cost sounds small but compounds. At the observed 9.4% daily turnover, annual cost drag is approximately 2.3% of NAV. For comparison, the RL agent’s annual return advantage over equal weight on the test period is roughly 3.5%. The cost model is doing real work here. Key recommendations:
For equities, use 0.05–0.1% minimum
For crypto, use 0.1–0.25% (taker fees on most venues are 0.1% or higher)
Monitor turnover in every backtest — if average daily turnover exceeds 10%, investigate whether the agent is genuinely learning or just churning
Survivorship Bias and Lookahead
In simulation this is not an issue by construction. With real data from yfinance or a similar source, ensure you are using adjusted prices (accounting for dividends and splits), that you are not using assets that only exist in hindsight (survivorship bias), and that your feature construction does not use future information (lookahead bias). Point-in-time index constituents require a proper data vendor.
Beyond CEM: Other RL Approaches Worth Exploring
PPO + Stable-Baselines3 is the natural next step for those with GPU access. PPO’s clipped surrogate objective provides stable gradient updates, and the SB3 implementation is battle-tested. The code snippet in the GPU section above is a working starting point.
Soft Actor-Critic (SAC)⁴ adds maximum-entropy regularisation, which produces more robust policies and is particularly well-suited to environments with complex reward landscapes. SAC’s off-policy nature makes it more sample efficient than PPO.
Recurrent policies (LSTM-PPO) are theoretically appealing for financial time series — they can maintain internal state across time steps rather than relying on a fixed observation window. Available via sb3-contrib‘s RecurrentPPO.
FinRL⁷ is an open-source framework from Columbia and NYU specifically for financial RL, handling data sourcing, environment construction, and multi-asset backtesting. Worth considering once you have outgrown hand-rolled environments.
Meta-learning (e.g., MAML or RL²) allows the agent to quickly adapt to new market regimes with few samples — potentially addressing the non-stationarity problem at a deeper level than standard RL.
Conclusion
Reinforcement learning offers a genuinely interesting alternative to classical portfolio optimisation for a specific class of problems: those where regime-switching, transaction costs, and path-dependence make static optimisers brittle. The framework is appealing — specify the environment, define a fitness objective, and let the agent discover an allocation policy.
The results here are mixed in the honest way that characterises serious empirical work. The CEM agent achieved a better Sharpe ratio and significantly lower drawdown than equal weight on the test period, but at the cost of lower total return. The train-to-validation degradation was substantial. A single 300-day test window is not enough to draw conclusions. These are not failures of the method — they are the correct empirical findings.
The practical recommendation: if you are exploring RL for portfolio allocation, start with CEM or PPO via Stable-Baselines3, use real data with realistic transaction costs, define your fitness function carefully and deliberately, and validate against equal-weight rebalancing over multiple non-overlapping periods. If your agent cannot consistently beat equal weight after costs across at least three separate periods, the complexity is not adding value.
The field is evolving rapidly. Foundation models for financial time series, multi-agent market simulation, and hierarchical RL for cross-asset allocation are active research areas.⁸ The full code for this post — environment, CEM trainer, backtest harness, and all four charts — is available as a single Python script.
References
Markowitz, H. (1952). Portfolio Selection. Journal of Finance, 7(1), 77–91.
Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518, 529–533.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. Proceedings of the 35th ICML.
Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus, M., & Dormann, N. (2021). Stable-Baselines3: Reliable Reinforcement Learning Implementations. Journal of Machine Learning Research, 22(268), 1–8.
Jiang, Z., Xu, D., & Liang, J. (2017). A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem. arXiv:1706.10059.
Liu, X., Yang, H., Chen, Q., et al. (2020). FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance. NeurIPS 2020 Deep RL Workshop.
Hambly, B., Xu, R., & Yang, H. (2023). Recent Advances in Reinforcement Learning in Finance. Mathematical Finance, 33(3), 437–503.
Moody, J., & Saffell, M. (2001). Learning to Trade via Direct Reinforcement. IEEE Transactions on Neural Networks, 12(4), 875–889.
Rubinstein, R. Y. (1999). The Cross-Entropy Method for Combinatorial and Continuous Optimization. Methodology and Computing in Applied Probability, 1(2), 127–190.
Beta convexity is a measure of how stable a stock beta is across market regimes. The essential idea is to evaluate the beta of a stock during down-markets, separately from periods when the market is performing well. By choosing a portfolio of stocks with low beta-convexity we seek to stabilize the overall risk characteristics of our investment portfolio.
A primer on beta convexity and its applications is given in the following post:
In this post I am going to use the beta-convexity concept to construct a long-only equity portfolio capable of out-performing the benchmark S&P 500 index.
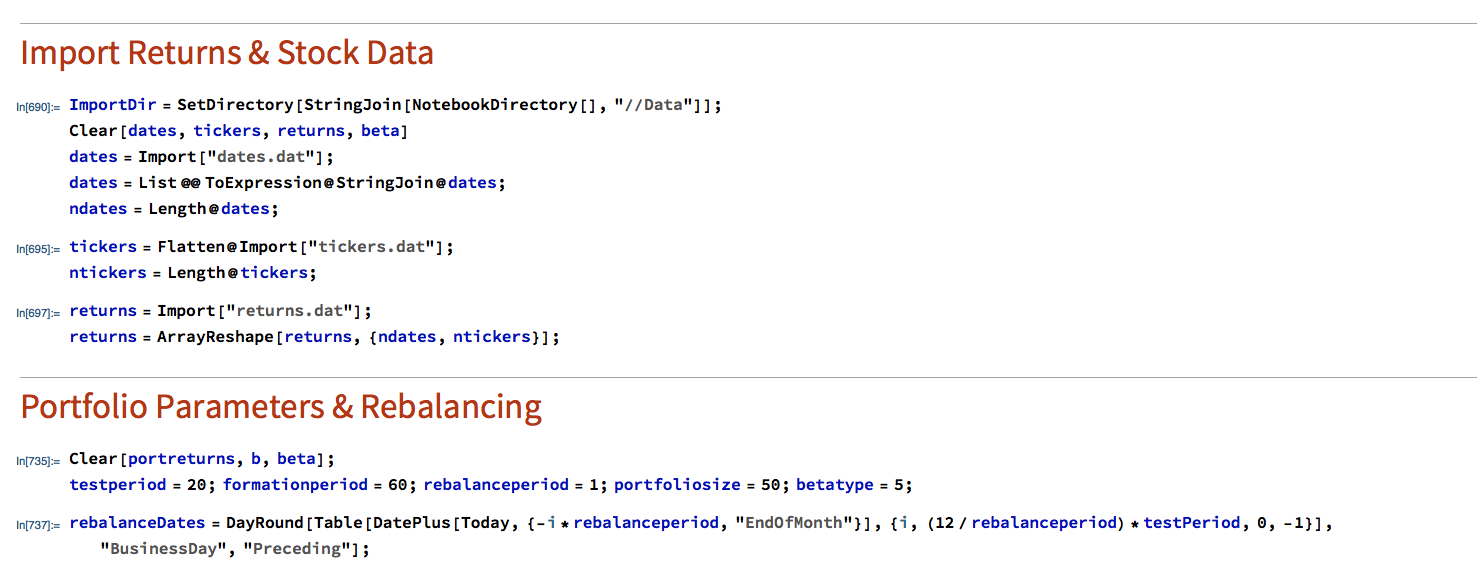
The post is in two parts. In the first section I outline the procedure in Mathematica for downloading data and creating a matrix of stock returns for the S&P 500 membership. This is purely about the mechanics, likely to be of interest chiefly to Mathematica users. The code deals with the issues of how to handle stocks with multiple different start dates and missing data, a problem that the analyst is faced with on a regular basis. Details are given in the pdf below. Let’s skip forward to the analysis.
Portfolio Formation & Rebalancing
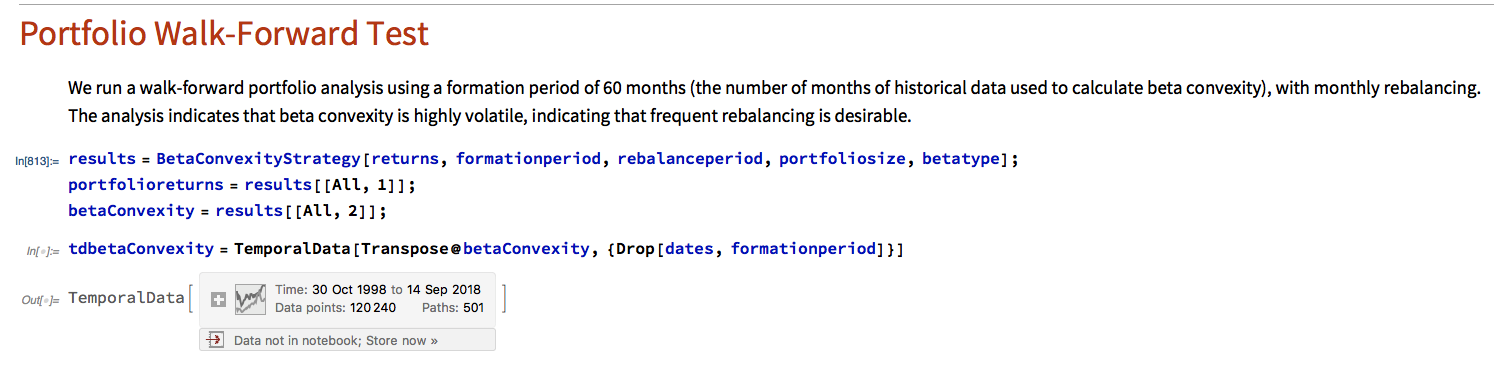
We begin by importing the data saved using the data retrieval program, which comprises a matrix of (continuously compounded) monthly returns for the S&P500 Index and its constituent stocks. We select a portfolio size of 50 stocks, a test period of 20 years, with a formation period of 60 months and monthly rebalancing.
In the processing stage, for each month in our 20-year test period we calculate the beta convexity for each index constituent stock and select the 50 stocks that have the lowest beta-convexity during the prior 5-year formation period. We then compute the returns for an equally weighted basket of the chosen stocks over the following month. After that, we roll forward one month and repeat the exercise.
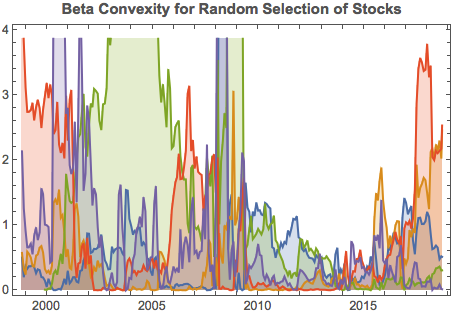
It turns out that beta-convexity tends to be quite unstable, as illustrated for a small sample of component stocks in the chart below:
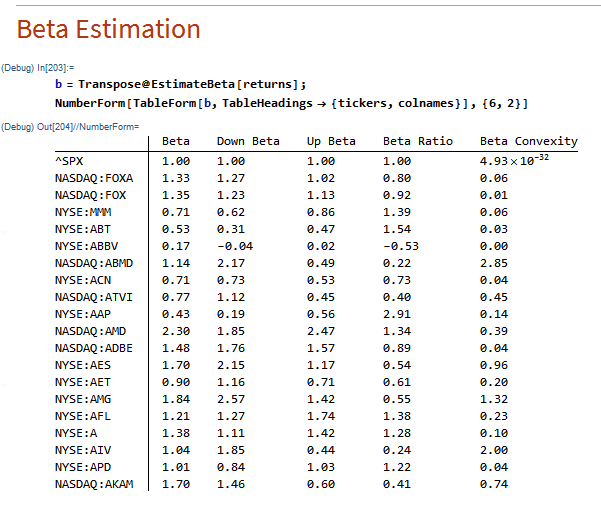
A snapshot of estimated convexity factors is shown in the following table. As you can see, there is considerable cross-sectional dispersion in convexity, in addition to time-series dependency.
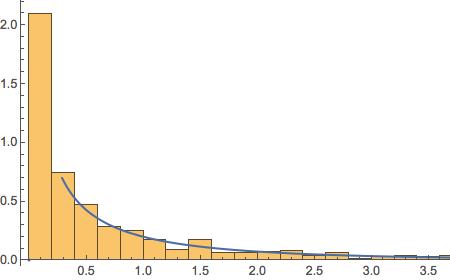
At any point in time the cross-sectional dispersion is well described by a Weibull distribution, which passes all of the usual goodness-of-fit tests.
Performance Results
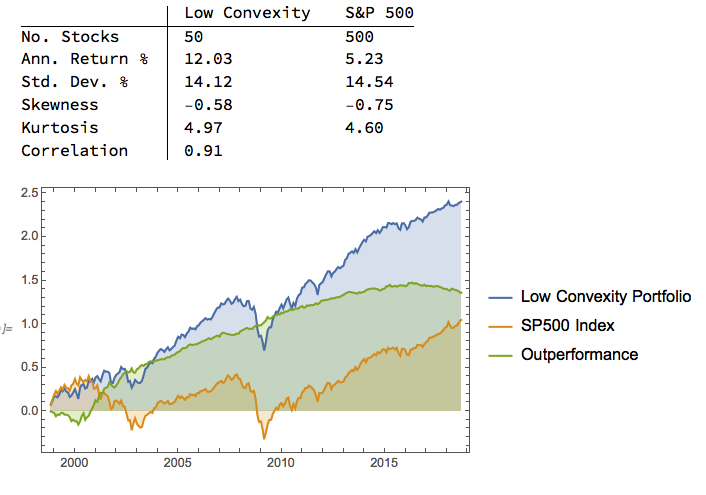
We compare the annual returns and standard deviation of the low convexity portfolio with the S&P500 benchmark in the table below. The results indicate that the average gross annual return of a low-convexity portfolio of 50 stocks is more than double that of the benchmark, with a comparable level of volatility. The portfolio also has slightly higher skewness and kurtosis than the benchmark, both desirable characteristics.
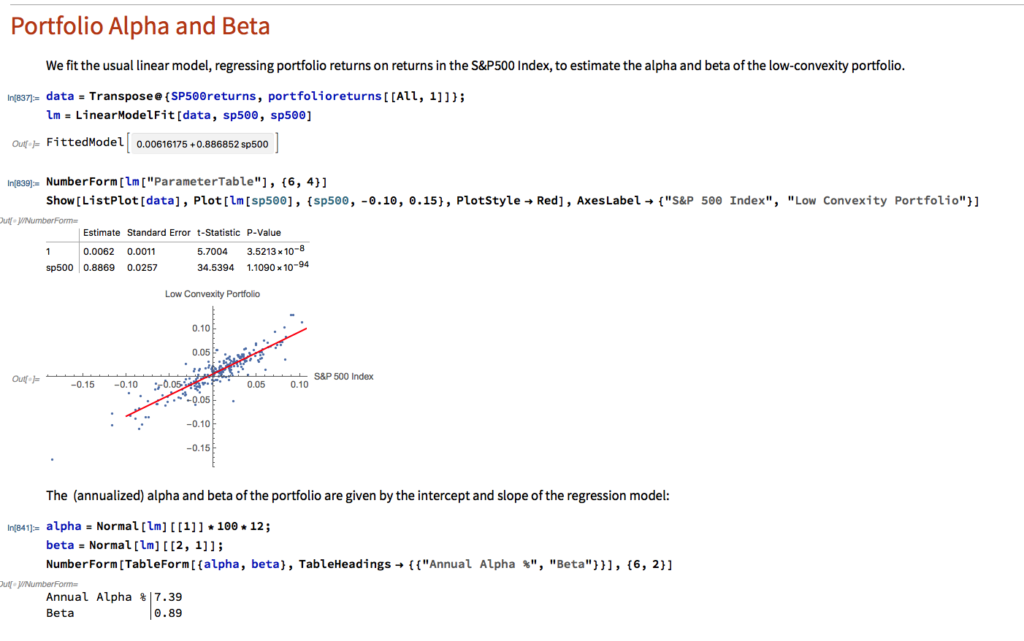
Portfolio Alpha & Beta Estimation
Using the standard linear CAPM model we estimate the annual alpha of the low-convexity portfolio to be around 7.39%, with a beta of 0.89.
Beta Convexity of the Low Convexity Portfolio
As we might anticipate, the beta convexity of the portfolio is very low since it comprises stocks with the lowest beta-convexity:
Conclusion: Beating the Benchmark S&P500 Index
Using a beta-convexity factor model, we are able to construct a small portfolio that matches the benchmark index in terms of volatility, but with markedly superior annual returns. Larger portfolios offering greater liquidity produce slightly lower alpha, but a 100-200 stock portfolio typically produce at least double the annual rate of return of the benchmark over the 20-year test period.
For those interested, we shall shortly be offering a low-convexity strategy on our Systematic Algotrading platform – see details below: