

History does not repeat itself, but it often rhymes – Mark Twain
You certainly wouldn’t know it from a reading of the CBOE S&P500 Volatility Index (CBOE:VIX), which printed a low of 11.44 on Friday, but there is a great deal of uncertainty about the prospects for the market as we move further into the third quarter, traditionally the most challenging period of the year. Reasons for concern are not hard to fathom, with the Fed on hold and poised to start raising rates, despite anemic growth in the economy; gloom over the “earnings recession”; and an abundance of political risk factors in play, not least of which is the upcoming presidential election.
At times like these investors need a little encouragement to stay the course – and where better to look for it than in the history books. More specifically, the question is whether the past has anything to teach us about the prospects for the market, going forward. Academic theory says no; but Wall Street traders controlling trillions of dollars of investments believe that, on the contrary, history contains valuable information that can be helpful in predicting the likely future outcome for the market.

Correlation, Drift and Volatility
There are several difficulties in making historical comparisons. Firstly, while it maybe intuitively obvious what one means when speaking about a “comparable” historical period, it is not as easy as one might think to translate that concept into mathematical form. And it does need to be translated, because unless you plan to study market history comprising tens or hundreds of thousands of historical patterns by hand (eye), you are going to have to rely on computers to do the heavy lifting.
Perhaps the most well-known measure of “similarity” is correlation; but this is entirely unsuited to the task at hand. The reason is that correlation removes the very thing that traders are most interested in: the trend, or drift. Let me illustrate the point with a simple example. The following chart illustrates two, perfectly correlated series (technically, Wiener processes) that simulate the evolution of returns in two stocks.
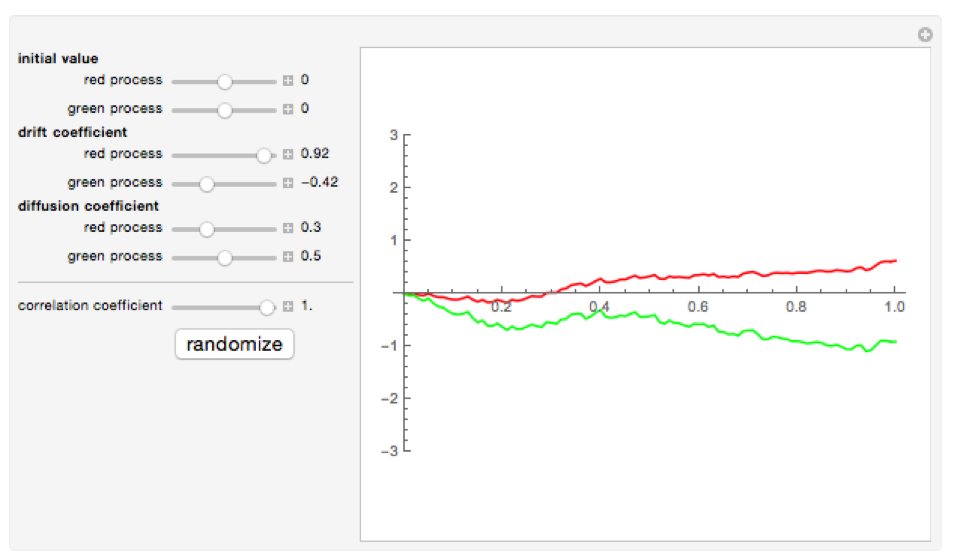
Source: Wolfram Research
Even though the processes are perfectly correlated, they end up producing very different outcomes, chiefly because the red process has a strongly positive drift, or trend, while the green process has a strongly negative drift. It is highly implausible that the path realized by the green process would be regarded as similar to that of the red process, despite their correlation. The moral is simple: whatever else we mean by “similar”, it must entail a comparable result in terms of the overall appreciation (or depreciation) of the stock; i.e. the two periods must show a similar degree of trending behavior.
Now let’s consider a second illustrative example. Here, not only are the two processes perfectly correlated, they also have an identical drift (14%).
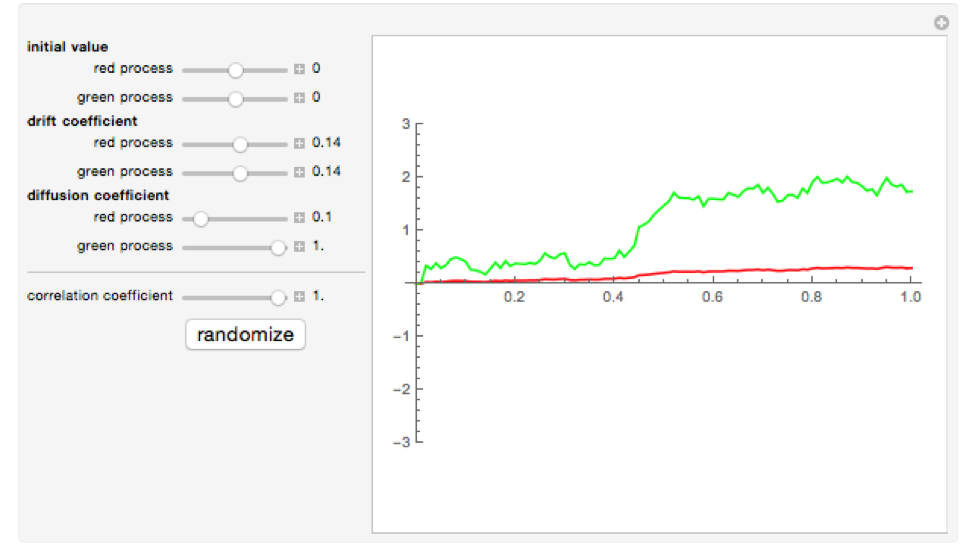
Source: Wolfram Research
Despite their commonalities, it is again very unlikely that we would regard the behavior of the green process as being sufficiently “similar” to that of the red process. Here the problem is not the difference in drift, but in volatility, which is ten times higher for the green process than for the red process. Even though both processes are expected to appreciate at the same average rate, the high volatility of the green process means that it may appreciate at a much faster, or slower, rate than the mean. We say that the volatility “drowns out” the drift in the process, at least over the short term.
So, in conclusion, what we are looking for in our quest for “similarity” is a period in which the process has displayed, not only a similar trend, but also a comparable level of volatility.
The challenges don’t end there, however. Let’s say we find a period in history in which the overall appreciation and volatility of the process is “similar” to that of the period of interest, but the historical period is shorter, or longer, than the period we are evaluating. Does that matter? Well to some degree, it must: if during the historical period the stock appreciated by 50% in 3 days, vs the same percentage over a term of 3 months during the current period, it is again unlikely that we would regard the historical period as similar. On the other hand, if the two periods differed in length by, say, only 4-5 days out of a total of 30, would that be enough to make you discard the historical precedent? Probably not, other things being equal. So there has to be scope for some, but not unlimited, flexibility in making historical comparisons using periods of slightly differing durations.
Solving the Correspondence Problem with Dynamic Time Warping
Having presented the problem, let me now turn to the solution.
Dynamic Time Warping (DTW) is a machine learning algorithm originally developed for speech recognition that aims two align two sequences by warping the time axis iteratively until a match is found between the two sequences.
Consider two sequences
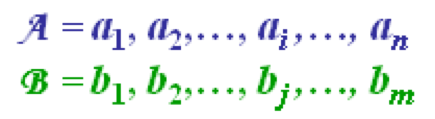
The two sequences can be arranged on the sides of a grid, with one on the top and the other up the left hand side. Both sequences start on the bottom left of the grid.
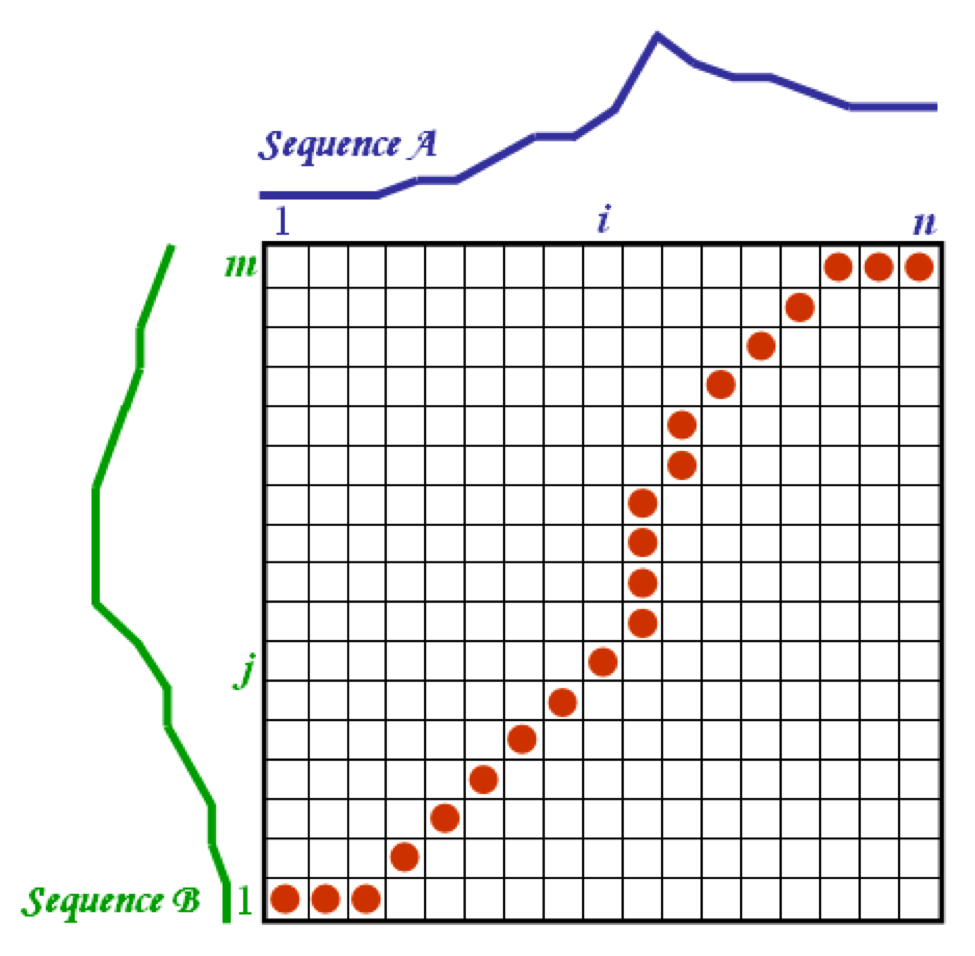
Inside each cell a distance measure is used to compare the corresponding elements of the two sequences. To find the best match or alignment between these two sequences one needs to find a path through the grid which minimizes the total distance between them. The procedure for computing this overall distance involves finding all possible routes through the grid and computing the overall distance for each one. The overall distance is the minimum of the sum of the distances between the individual elements on the path divided by the sum of the weighting function.
A great many measures of “distance” (the inverse of “similarity”) have been developed over the years, in fields as disparate as image analysis, signal processing and machine learning. In what follows we shall be using Euclidean Distance as our preferred distance metric, but there are a large number of alternative options:
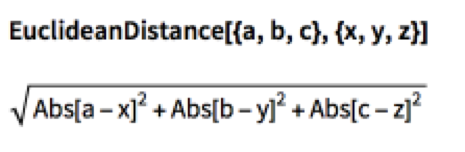
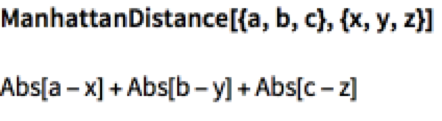
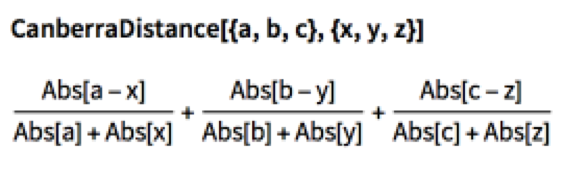
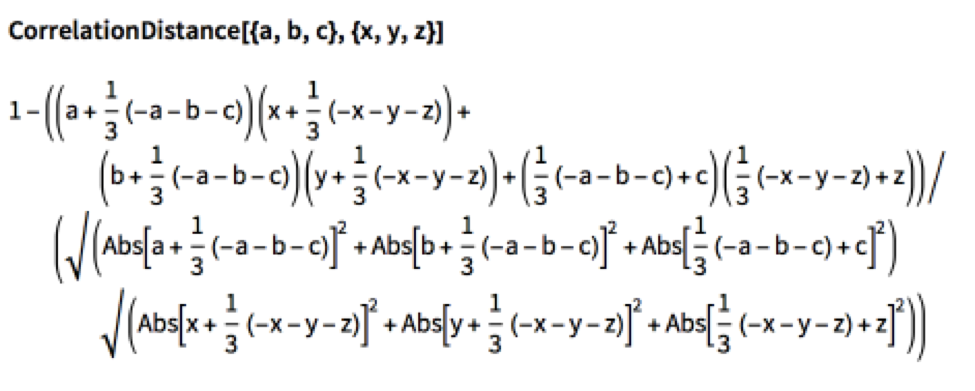
The DTW algorithm optimizes the distance, constrained by limits on acceptable paths through the grid:
- Monotonic condition: the path will not turn back on itself, both the i and j indexes either stay the same or increase, they never decrease.
- Continuity condition: the path advances one step at a time. Both i and j can only increase by at most 1 on each step along the path.
- Boundary condition: the path starts at the bottom left and ends at the top right.
- Warping window condition: a good path is unlikely to wander very far from the diagonal. The distance that the path is allowed to wander is the window width.
- Slope constraint condition: The path should not be too steep or too shallow. This prevents short sequences matching too long ones. The condition is expressed as a ratio p/q where p is the number of steps allowed in the same (horizontal or vertical) direction. After p steps in the same direction is not allowed to step further in the same direction before stepping at least q time in the diagonal direction.
These constraints allow to restrict the moves that can be made from any point in the path and so limit the number of paths that need to be considered. The power of the DTW algorithm lies in that instead finding all possible routes through the grid which satisfy the above conditions, it works by keeping track of the cost of the best path to each point in the grid. During the calculation process of the DTW grid it is not known which path is minimum overall distance path, but this can be traced back when the end point is reached.
Market Outlook Using Dynamic Time Warping
Let’s apply the DTW approach to find a similar period in the history of the SPDR S&P 500 ETF (NYSEArca:SPY).
We download data for the SPY ETF and look for periods in the history of the series from 1995 that are similar to how the process has evolved in Q3 2016. Note that we are using log-returns rather than raw prices. This is because what we care about is that the rate at which the ETF has appreciated relative to its initial starting value should be comparable for both periods.
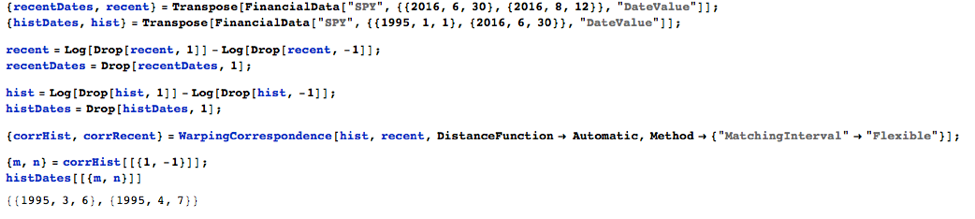
The algorithm picks out a 21-day period from 3/6/1995 to 4/7/1995 as being the most similar to the way the SPY ETF has progressed in Q3 2016. Let’s take a look at the two periods and assess their similarity. Note that we set the initial starting price at 100 in each case.
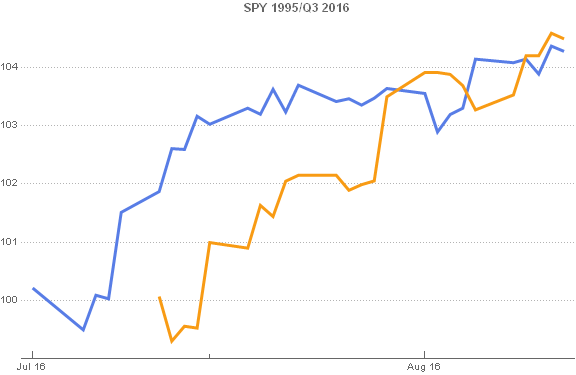

Source: Author
It is clear that the SPY appreciates by approximately the same percentage over the two periods, but the way in which it evolves looks rather different in each case. That’s because the earlier period covers only 25 business days, compared to the 51 days from the start of Q3 2016 period. If you can imagine dilating the shorter time span of the orange line in the above chart to cover the same span as the blue line, the patterns look very similar indeed.
We are going to use the historical period to forecast how the ETF is likely to evolve of the next 35 days to the end of Q3. We do this by mapping the evolution of the ETF over the 35 days following the end of the historical period on 4/7/95 and projecting that pattern onto the end of the current period, from 8/12/16. The result is as follows.
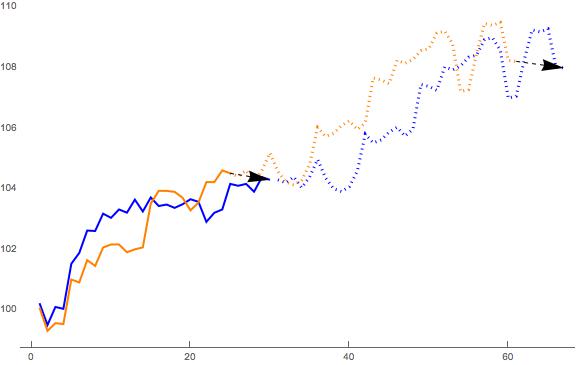

Source: Author
In other words, if the closely parallel history of the series from 1995 were to repeat itself in 2016, we might expect a further gain of perhaps 3.5% to 4% in the SPY ETF between now and the end of September.
Caveats
Whether you hold this approach as valid or not depends largely on how credible you regard the thesis that history is inclined to repeat itself. There are significant differences in fundamental factors that are likely to affect the outcome over the next several months, compared to the similar period in 1995.
The early part of 1995 marked the beginning of a powerful market surge driven by an economic boom that lasted until late 1999. By contrast, in the more recent period, the economy has been emerging very slowly from the long-running credit crisis commencing in 2008. Likewise, in contrast to 1995 when the Fed was at the early stage of reducing interest rates, the Fed is now more likely to start raising rates at some point before the end of 2016.
While these and other aspects of the economic landscape are fundamentally different, there are parallels. The recent slowdown in productivity, for example, often cited as a cause for concern, mirrors a similar slowdown in 1995. As Bloomberg points out, such pauses are not uncommon and in fact the plateaus in 1993-1996 and 2003-2005 occurred at a time when the economy was pretty healthy. Conversely, several of the biggest productivity jumps have happened during recessions, in 2001 and 2009.
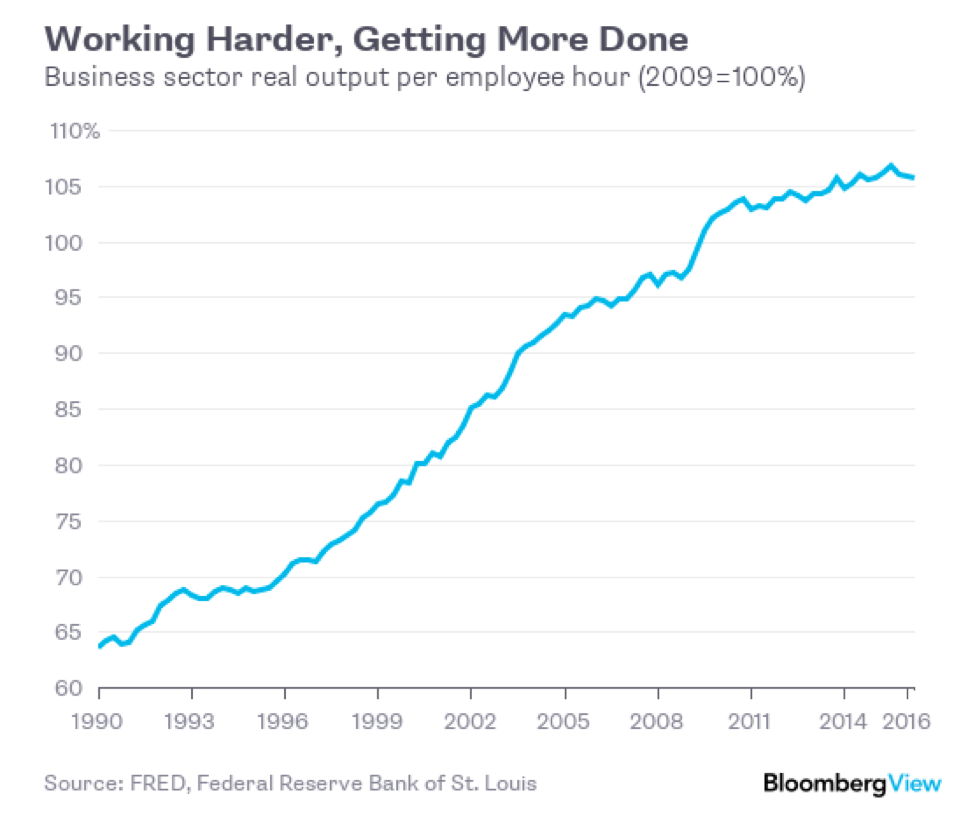
Source: Bloomberg
Conclusion
Doom-mongering is at record levels these days, as the market continues to make new highs. The Wall Street Journal, for example, recently ran a piece entitled “This Tech Bubble Is Bursting”, drawing parallels with the dot-com bust of 2000.
They could be right.
On the other hand, if history repeats itself we could see the market 4% higher going into the final quarter of 2016.
References
Sakoe,H. and Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. on Acoust., Speech, and Signal Process., ASSP 26, 43-49 (1978).
One Reply to “Dynamic Time Warping”
Comments are closed.