

The SPDR S&P 500 ETF (SPY) is one of the widely traded ETF products on the market, with around $200Bn in assets and average turnover of just under 200M shares daily. So the likelihood of being able to develop a money-making trading system using publicly available information might appear to be slim-to-none. So, to give ourselves a fighting chance, we will focus on an attempt to predict the overnight movement in SPY, using data from the prior day’s session.
In addition to the open/high/low and close prices of the preceding day session, we have selected a number of other plausible variables to build out the feature vector we are going to use in our machine learning model:
- The daily volume
- The previous day’s closing price
- The 200-day, 50-day and 10-day moving averages of the closing price
- The 252-day high and low prices of the SPY series
We will attempt to build a model that forecasts the overnight return in the ETF, i.e. [O(t+1)-C(t)] / C(t)

In this exercise we use daily data from the beginning of the SPY series up until the end of 2014 to build the model, which we will then test on out-of-sample data running from Jan 2015-Aug 2016. In a high frequency context a considerable amount of time would be spent evaluating, cleaning and normalizing the data. Here we face far fewer problems of that kind. Typically one would standardized the input data to equalize the influence of variables that may be measured on scales of very different orders of magnitude. But in this example all of the input variables, with the exception of volume, are measured on the same scale and so standardization is arguably unnecessary.
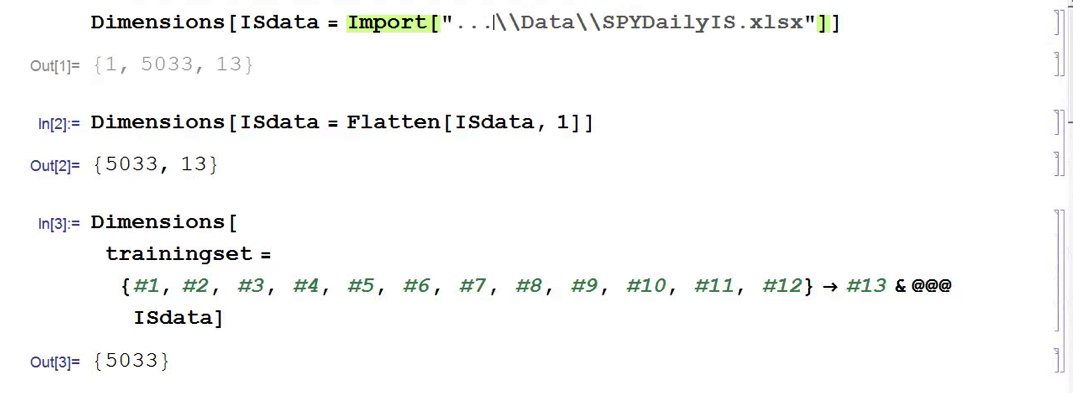
First, the in-sample data is loaded and used to create a training set of rules that map the feature vector to the variable of interest, the overnight return:
In Mathematica 10 Wolfram introduced a suite of machine learning algorithms that include regression, nearest neighbor, neural networks and random forests, together with functionality to evaluate and select the best performing machine learning technique. These facilities make it very straightfoward to create a classifier or prediction model using machine learning algorithms, such as this handwriting recognition example:
{kind=link}

We create a predictive model on the SPY trainingset, allowing Mathematica to pick the best machine learning algorithm:

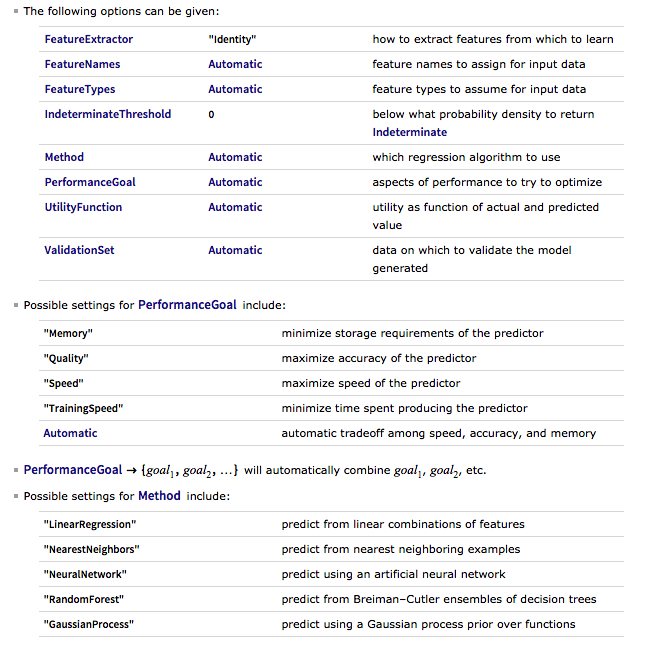
There are a number of options for the Predict function that can be used to control the feature selection, algorithm type, performance type and goal, rather than simply accepting the defaults, as we have done here:
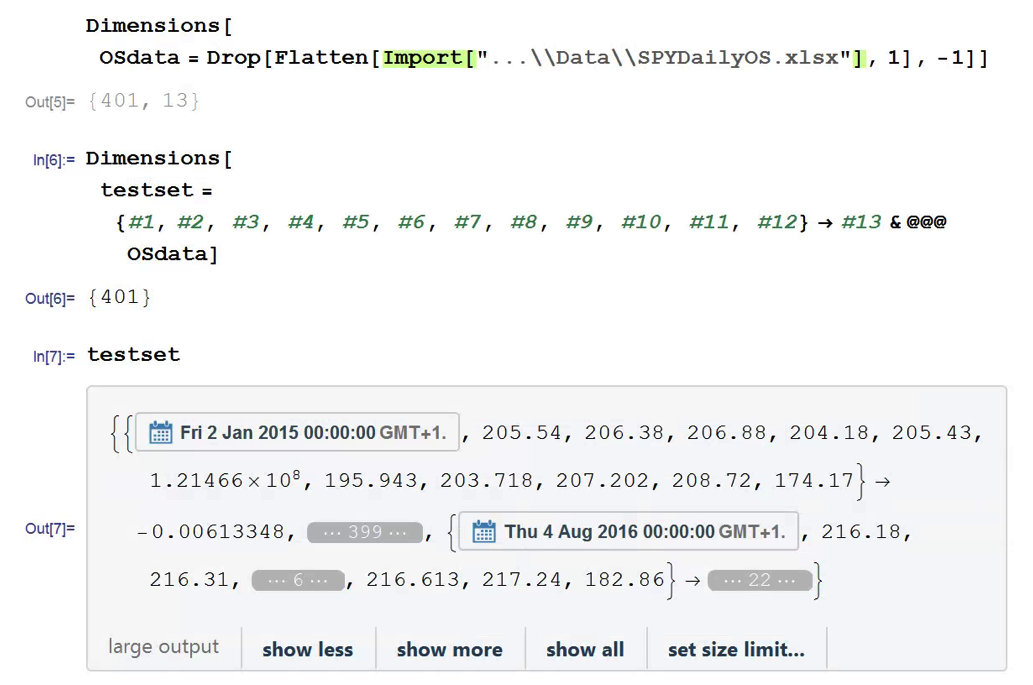
Having built our machine learning model, we load the out-of-sample data from Jan 2015 to Aug 2016, and create a test set:
We next create a PredictionMeasurement object, using the Nearest Neighbor model , that can be used for further analysis:

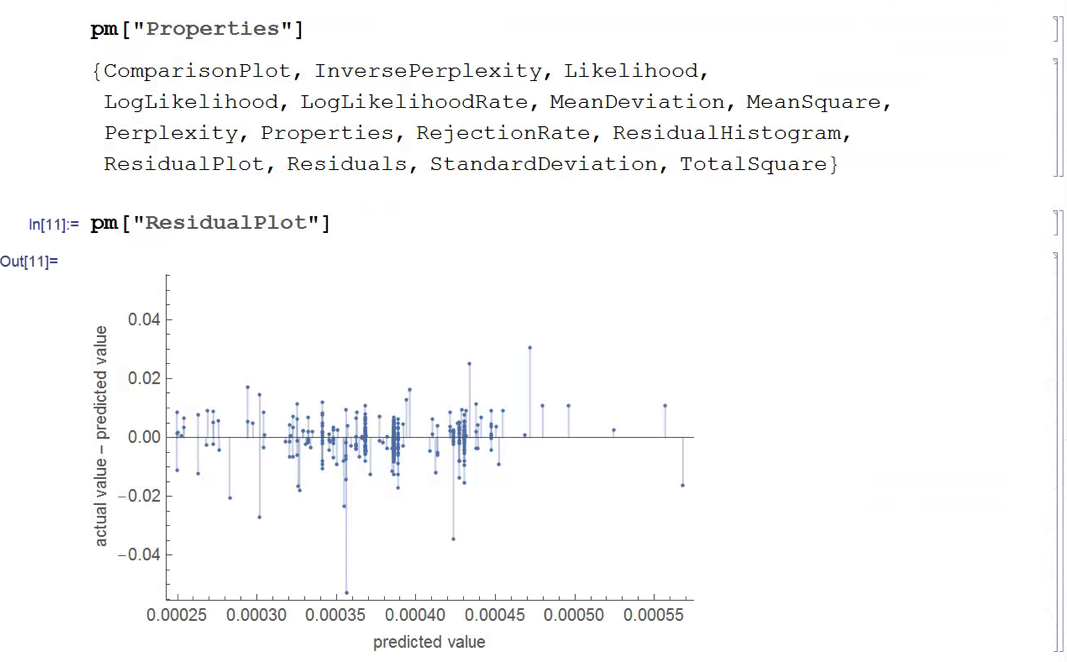
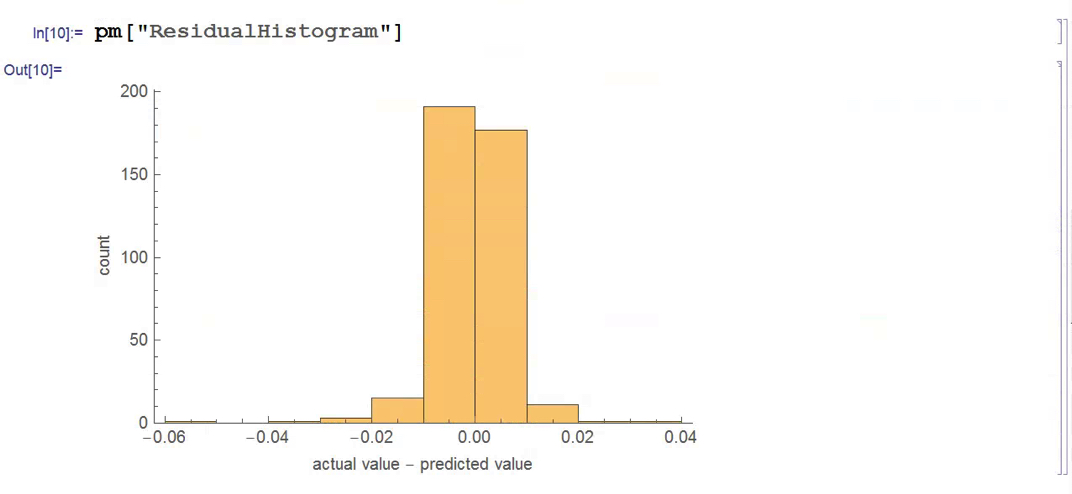
There isn’t much dispersion in the model forecasts, which all have positive value. A common technique in such cases is to subtract the mean from each of the forecasts (and we may also standardize them by dividing by the standard deviation).
The scatterplot of actual vs. forecast overnight returns in SPY now looks like this:

There’s still an obvious lack of dispersion in the forecast values, compared to the actual overnight returns, which we could rectify by standardization. In any event, there appears to be a small, nonlinear relationship between forecast and actual values, which holds out some hope that the model may yet prove useful.
From Forecasting to Trading
There are various methods of deploying a forecasting model in the context of creating a trading system. The simplest route, which we will take here, is to apply a threshold gate and convert the filtered forecasts directly into a trading signal. But other approaches are possible, for example:
- Combining the forecasts from multiple models to create a prediction ensemble
- Using the forecasts as inputs to a genetic programming model
- Feeding the forecasts into the input layer of a neural network model designed specifically to generate trading signals, rather than forecasts
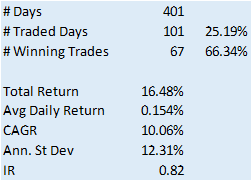
In this example we will create a trading model by applying a simple filter to the forecasts, picking out only those values that exceed a specified threshold. This is a standard trick used to isolate the signal in the model from the background noise. We will accept only the positive signals that exceed the threshold level, creating a long-only trading system. i.e. we ignore forecasts that fall below the threshold level. We buy SPY at the close when the forecast exceeds the threshold and exit any long position at the next day’s open. This strategy produces the following pro-forma results:

Conclusion
The system has some quite attractive features, including a win rate of over 66% and a CAGR of over 10% for the out-of-sample period.
Obviously, this is a very basic illustration: we would want to factor in trading commissions, and the slippage incurred entering and exiting positions in the post- and pre-market periods, which will negatively impact performance, of course. On the other hand, we have barely begun to scratch the surface in terms of the variables that could be considered for inclusion in the feature vector, and which may increase the explanatory power of the model.
In other words, in reality, this is only the beginning of a lengthy and arduous research process. Nonetheless, this simple example should be enough to give the reader a taste of what’s involved in building a predictive trading model using machine learning algorithms.
One Reply to “Machine Learning Trading Systems”
Comments are closed.