As we have discussed before, there is no standard definition of high frequency trading. For some, trading more than once or twice a day constitutes high frequency, while others regard anything less than several hundred times a session as low, or medium frequency trading. Hence in this post I have referred to “daytrading” since we can at least agree on that description for a strategy that exits all positions by the close of the session.
As we have discussed before, there is no standard definition of high frequency trading. For some, trading more than once or twice a day constitutes high frequency, while others regard anything less than several hundred times a session as low, or medium frequency trading. Hence in this post I have referred to “daytrading” since we can at least agree on that description for a strategy that exits all positions by the close of the session.
HFT Trading in ETFs – Challenges and Opportunities
High frequency trading in equities and ETFs offer their own opportunities and challenges compared to futures. Amongst the opportunities we might list:
- Arbitrage between destinations (exchanges, dark pools) where the stock is traded
- Earning rebates from the exchanges willing to pay for order flow
- Arbitraging news flows amongst pairs or baskets of equities
When it comes to ETFs, unfortunately, the set of possibilities is more restricted than for single names and one is often obliged to dig deeply into the basket/replication/cointegration type of approach, which can be very challenging in a high frequency context. The risk of one leg of a multi-asset trade being left unfilled is such that one has to be willing to cross the spread to get the trade on. Depending on the trading platform and the quality of the execution algorithms, this can make trading the strategy prohibitively expensive.
In that case you have a number of possibilities to consider. You can simplify the trade, limit the number of stocks in the basket and hope that there is enough alpha left in the reduced strategy. You can focus on managing the trade execution sufficiently well that aggressive trading becomes necessary on relatively few occasions and you look to minimize the costs of paying the spread when they arise. You can design strategies with higher profit factors that are able to withstand the performance drag entailed in trading aggressively. Or you can design slower versions of the strategy where latency, fill rates and execution costs are not such critical factors.

Developing high frequency strategies in the volatility ETFs presents special challenges. Being fairly new, the products have limited histories, which makes modeling more of a challenge. One way to address this is to create synthetic series priced from the VIX futures, using the published methodology for constructing the ETFs. Be warned, though, that these synthetic series are likely to inflate your backtest results since they aren’t traded instruments.
Another practical problem that crops up regularly in products like UVXY and VXX is that the broker has difficulty locating stock for short selling. So you are limited to taking the strategy offline when that occurs, designing strategies that trade long only, or as we do, switching to other products when the ETF is unavailable to short.
Then there is the capacity issue. Despite their fast-growing popularity, volatility ETF funds are in many cases quite small, totaling perhaps a few hundred millions of dollars in AUM. You are never going to be able to construct a strategy capable of absorbing billions of dollars of investment in the ETF products alone.
Volatility and Alpha
 For these reasons, volatility ETFs are not a natural choice for many investment strategists. But they do have one great advantage compared to other products: volatility. Volatility implies uncertainty about the true value of a security, which means that market participants can have very different views about what it is worth at any moment in time. So the prospects for achieving competitive advantage through superior analytical methods is much greater than for a stock that hardly moves at all and on whose value everyone concurs. Furthermore, volatility creates regular opportunities for hitting stops, and creating mini crashes or short squeezes, in which the security is temporarily under- or over-valued. If ever there was a security offering the potential for generating alpha, it is the volatility ETF.
For these reasons, volatility ETFs are not a natural choice for many investment strategists. But they do have one great advantage compared to other products: volatility. Volatility implies uncertainty about the true value of a security, which means that market participants can have very different views about what it is worth at any moment in time. So the prospects for achieving competitive advantage through superior analytical methods is much greater than for a stock that hardly moves at all and on whose value everyone concurs. Furthermore, volatility creates regular opportunities for hitting stops, and creating mini crashes or short squeezes, in which the security is temporarily under- or over-valued. If ever there was a security offering the potential for generating alpha, it is the volatility ETF.
The volatility of the VIX ETFs is enormous, by the standards of regular stocks. A typical stock might have an annual volatility of 30% to 60%. The lowest level ever seen in the VVIX index series so far is 70%. To give you an idea of how extreme it can become, during the latest market swoon in August the VVIX, the volatility-of-volatility for the S&P500 index, reached over 200% a year.
A Daytrading Strategy in the VXX
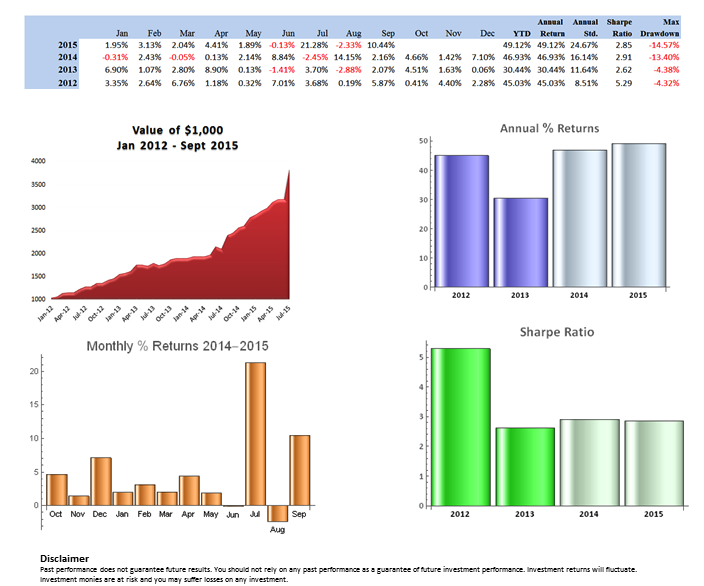
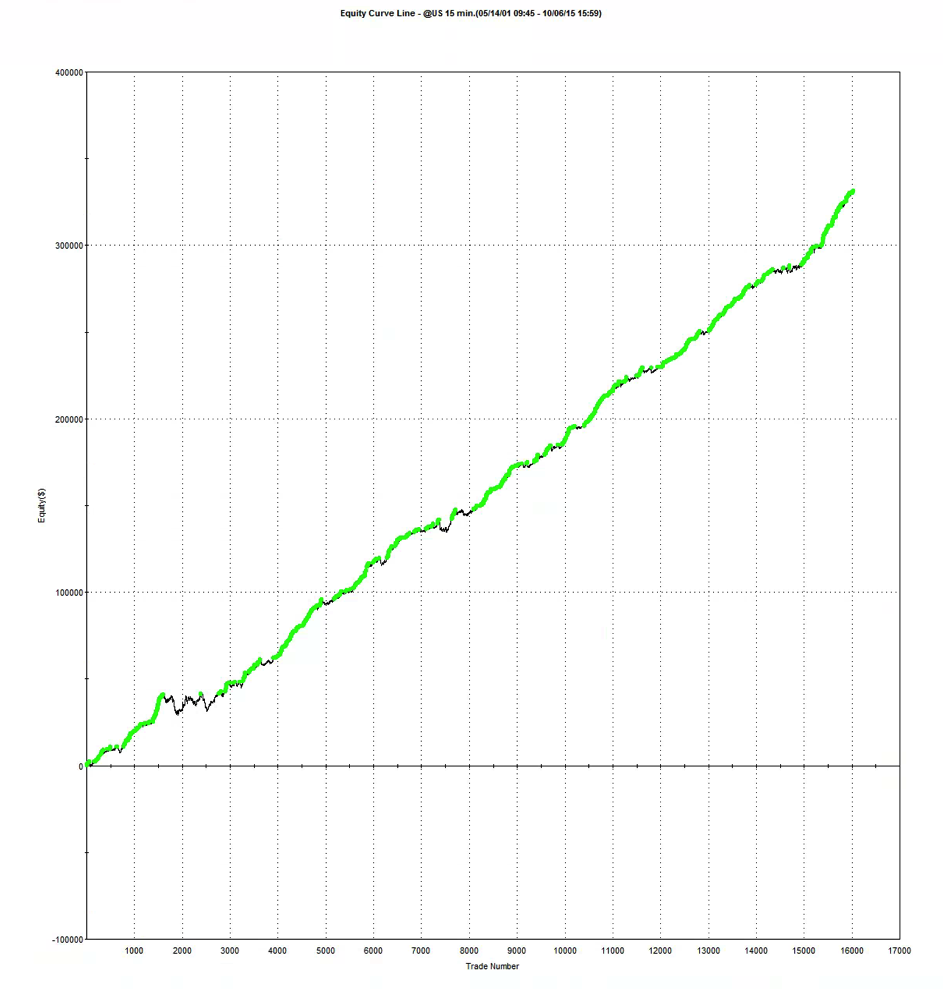
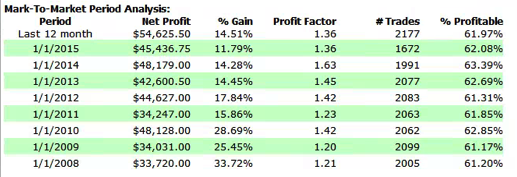
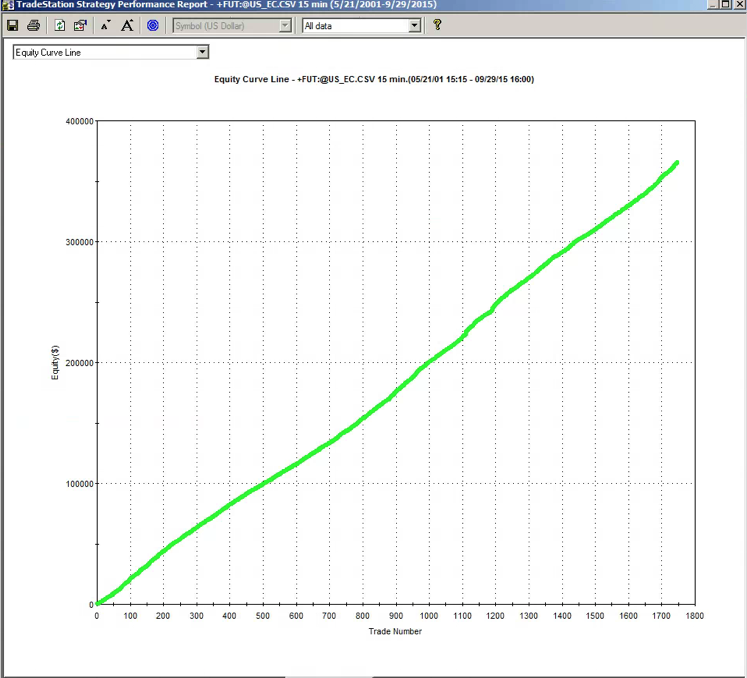
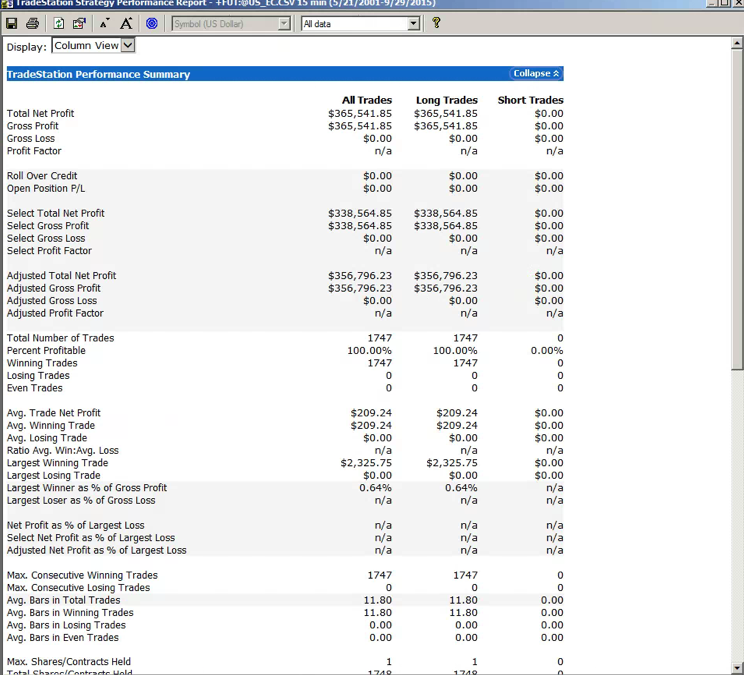
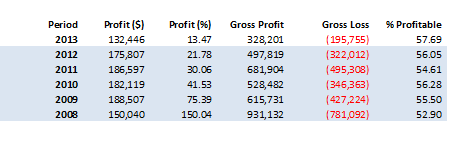
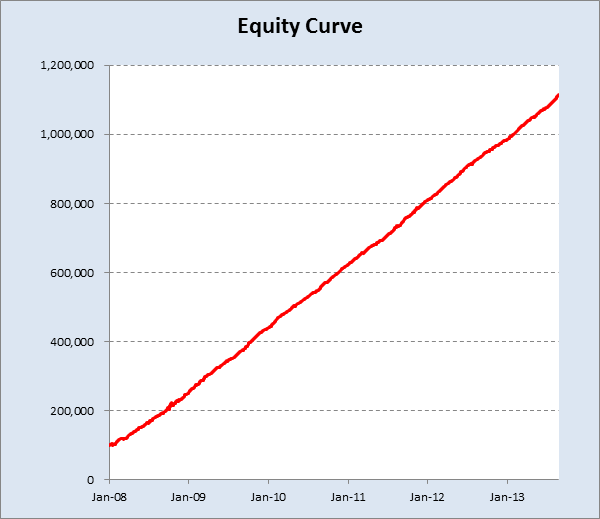
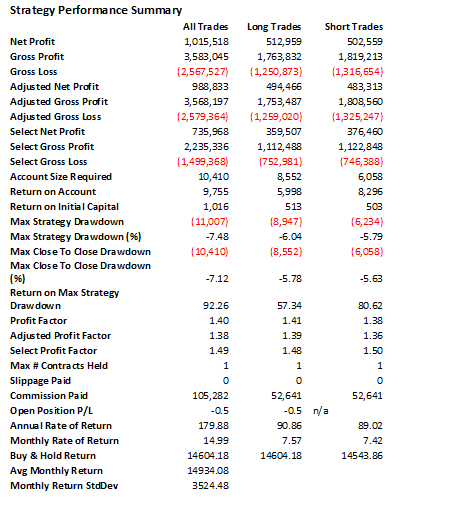
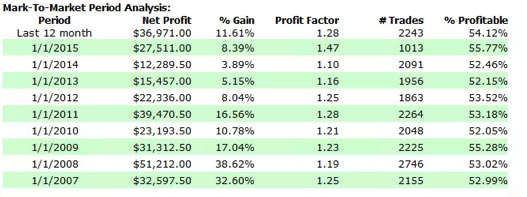
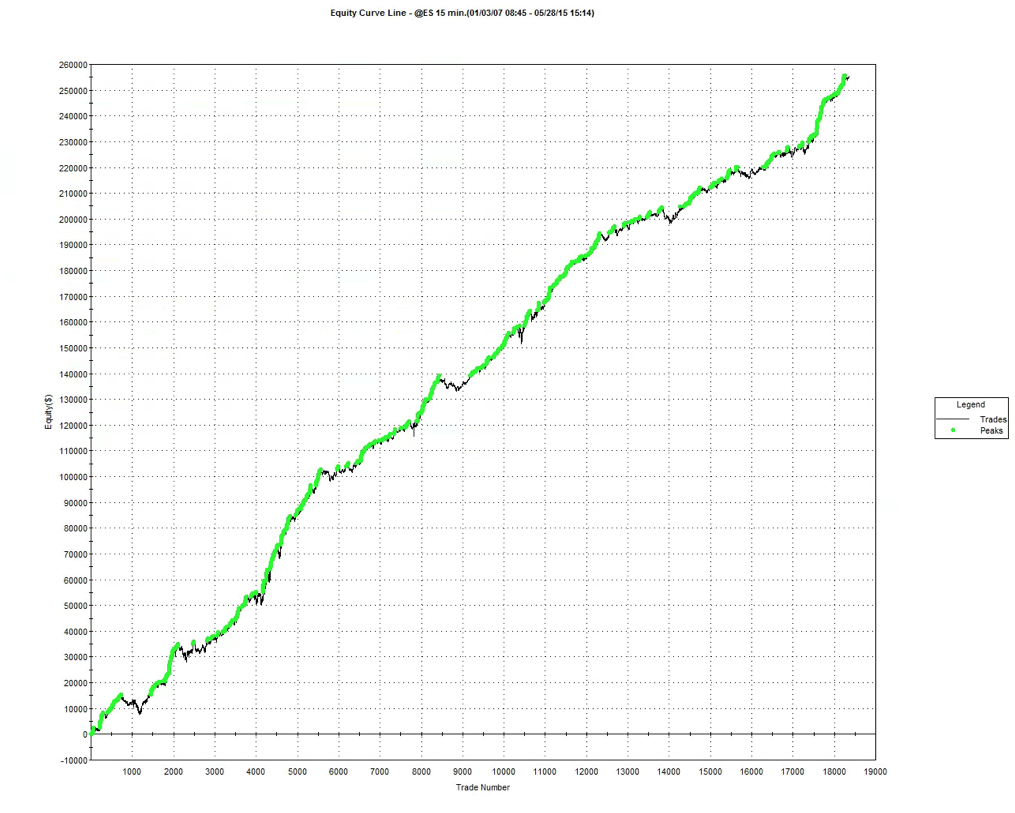
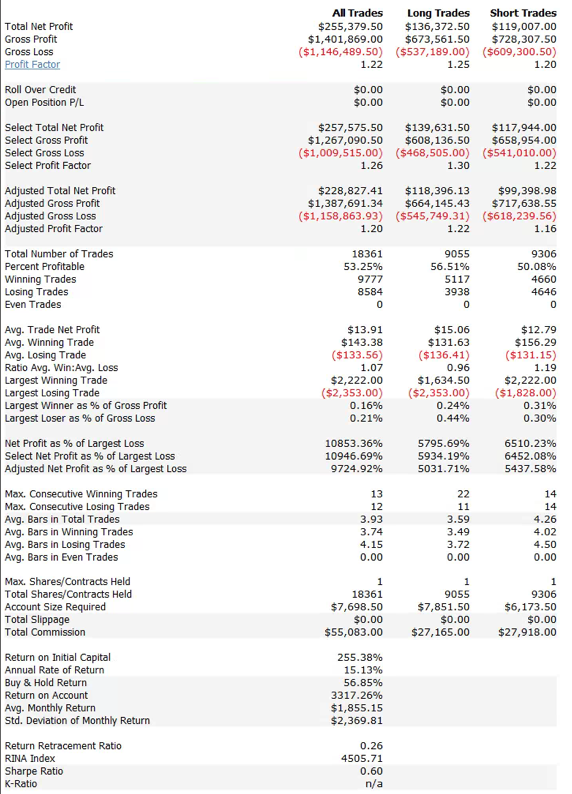
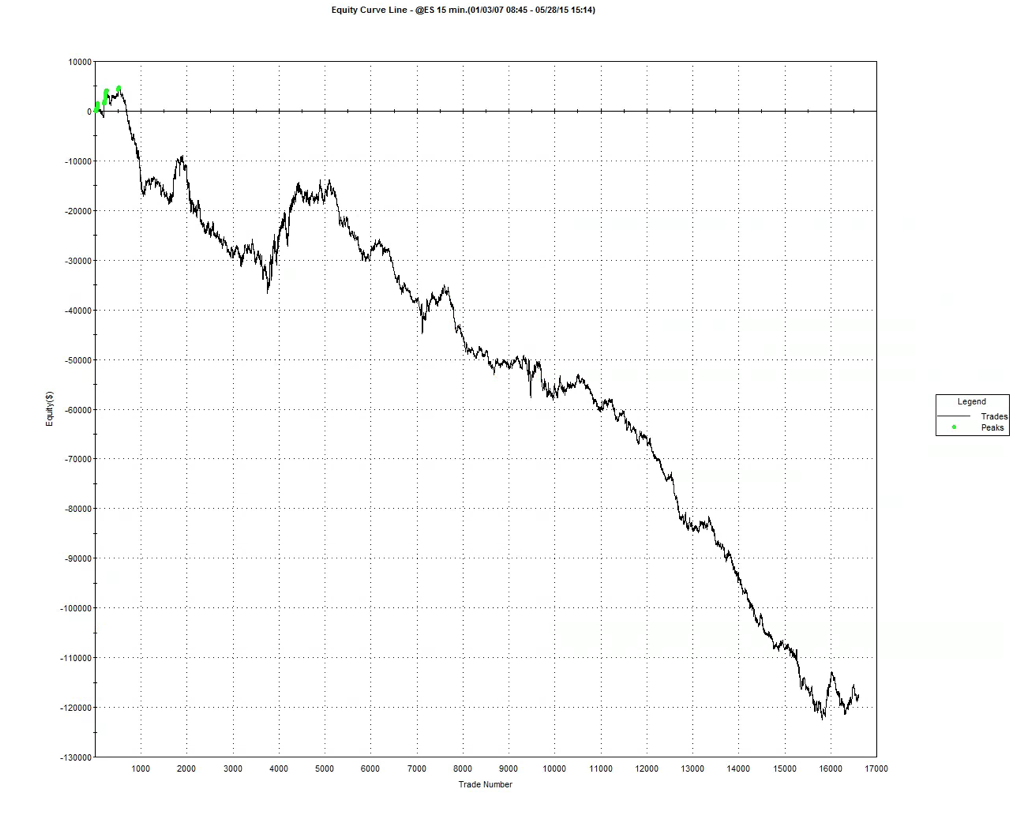
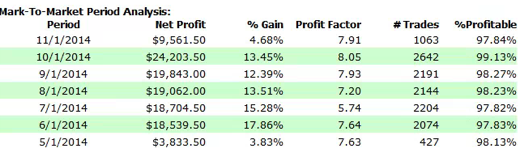
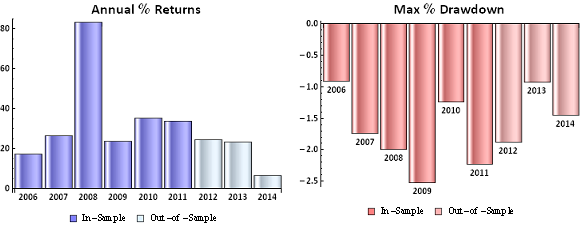
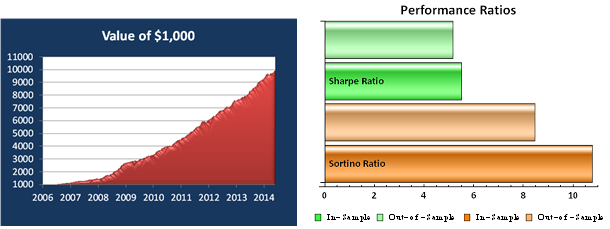
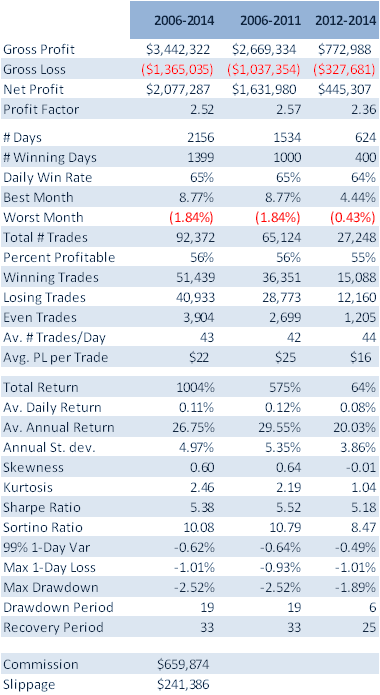
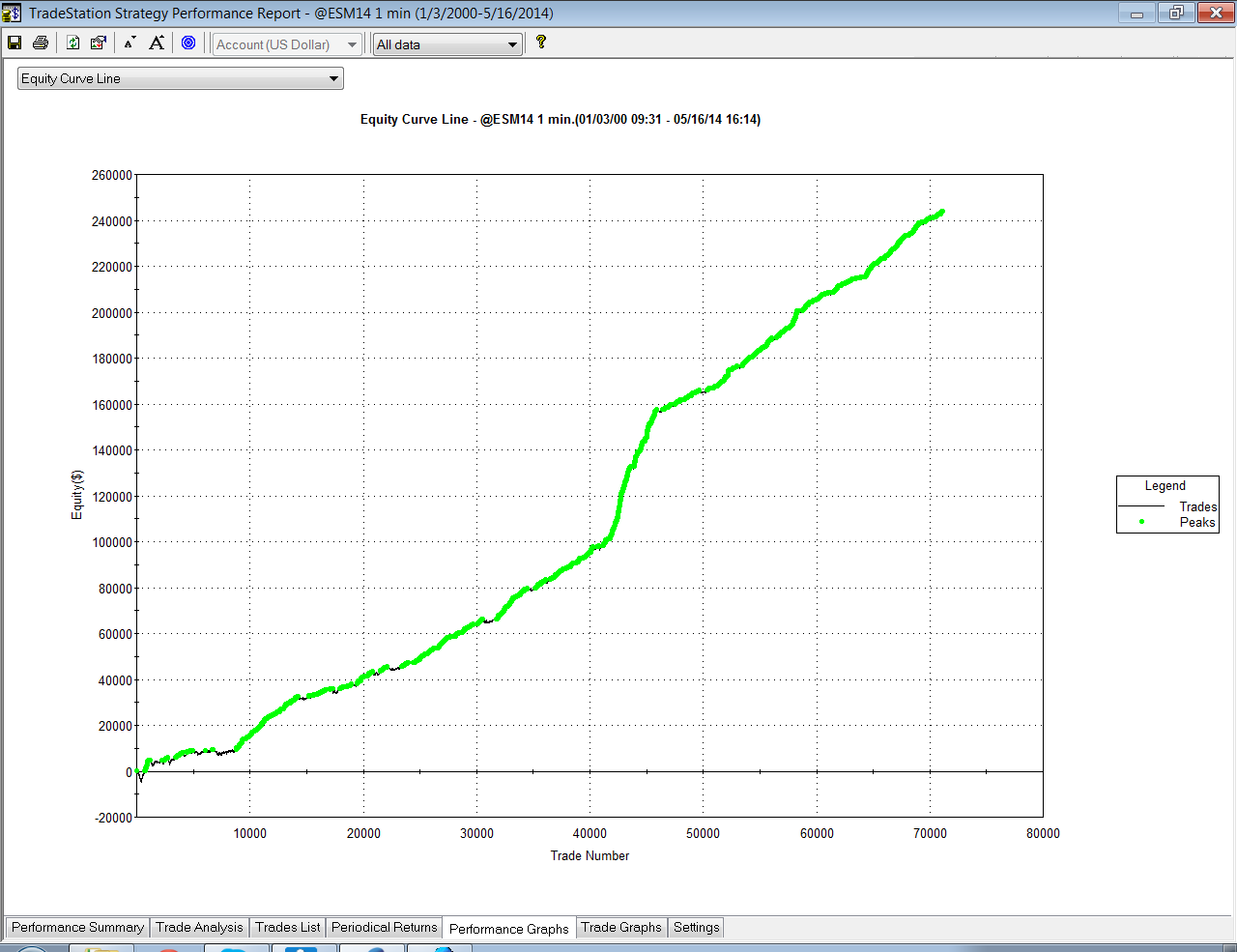
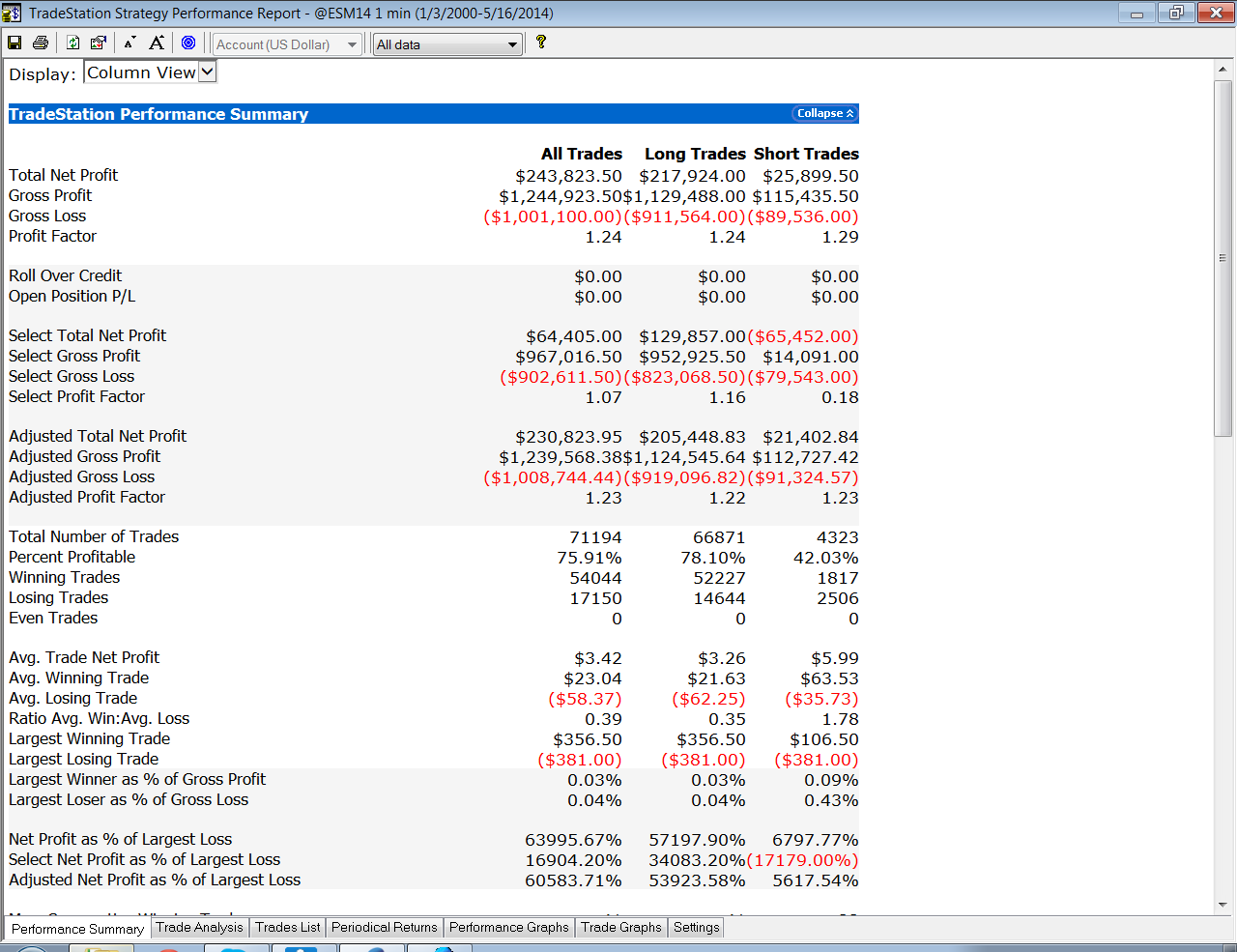
So, despite the challenges and difficulties, there are very good reasons to make the attempt to develop strategies for the volatility ETF products. My firm, Systematic Strategies, has developed several such algorithms that are combined to create a strategy that trades the volatility ETFs very successfully. Until recently, however, all of the sub-strategies we employ were longer term in nature, and entailed holding positions overnight. We wanted to develop higher frequency algorithms that could react more quickly to changes in the volatility landscape. We had to dig pretty deep into the arsenal of trading ideas to get there, but eventually we succeeded. After six months of live trading we were ready to release the new VXX daytrading algorithm into production for our volatility ETF strategy investors. Here’s how it looks (results are for a $100,000 account).
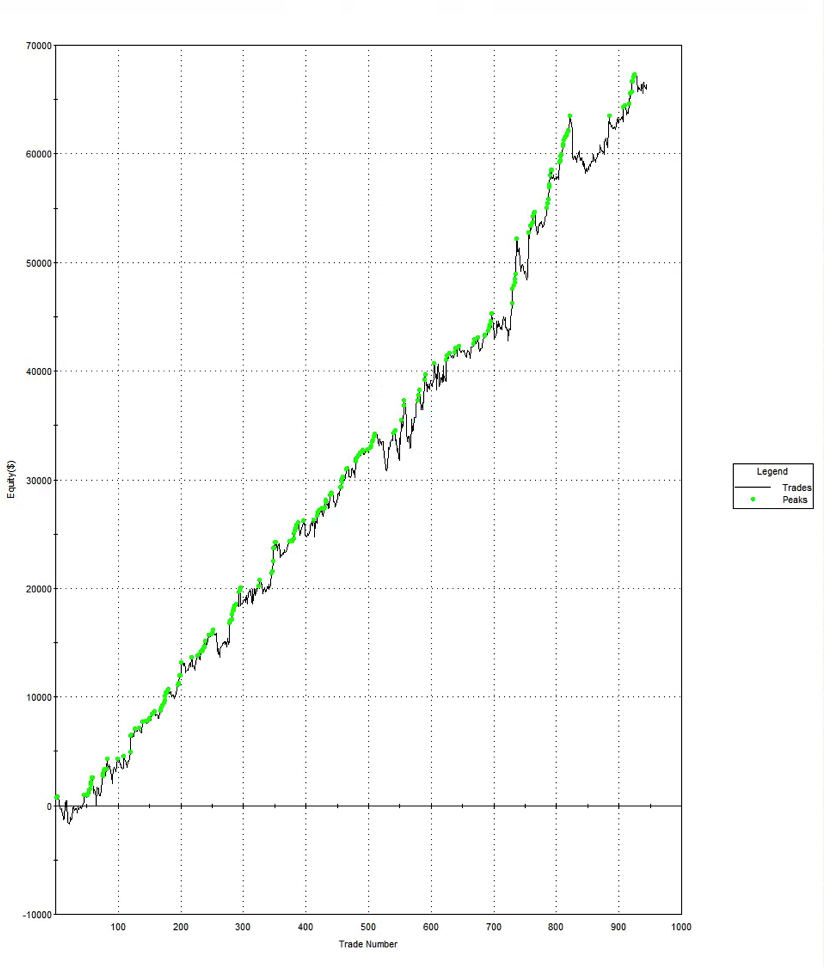

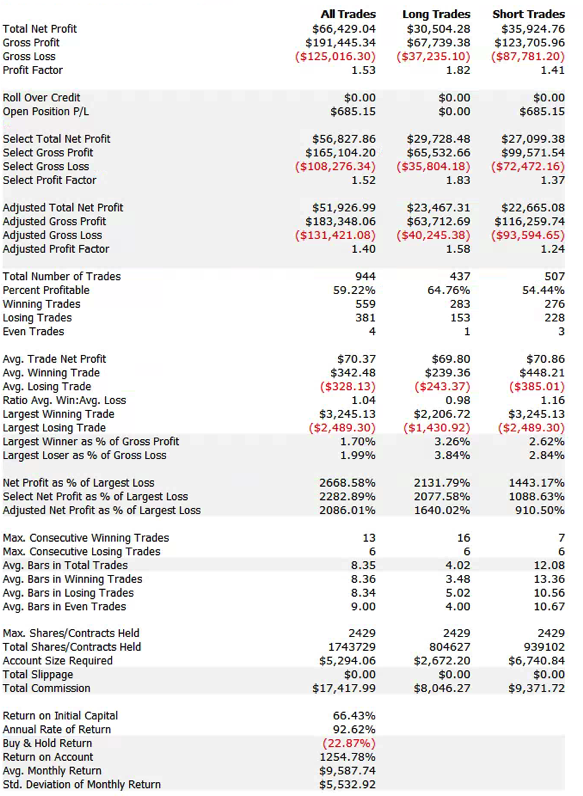
As you can see, the strategy trades up to around 10 times a day with a reasonable profit factor (1.53) and win rate of just under 60%. By itself, the strategy has a Sharpe Ratio of around 6, so it is well worth trading on its own. But its real value (for us) emerges when it is combined in appropriate proportion with the other, lower frequency algorithms in the volatility strategy. The additional alpha from the VXX strategy reduces the size of the loss in August and produces a substantial gain in September, taking the YTD return to just under 50%. Returns for Oct MTD are already at 16%.