

During the 1990’s the advent of Neural Networks unleashed a torrent of research on their applications in financial markets, accompanied by some rather extravagant claims about their predicative abilities. Sadly, much of the research proved to be sub-standard and the results illusionary, following which the topic was largely relegated to the bleachers, at least in the field of financial market research.
With the advent of new machine learning techniques such as Random Forests, Support Vector Machines and Nearest Neighbor Classification, there has been a resurgence of interest in non-linear modeling techniques and a flood of new research, a fair amount of it supportive of their potential for forecasting financial markets. Once again, however, doubts about the quality of some of the research bring the results into question.

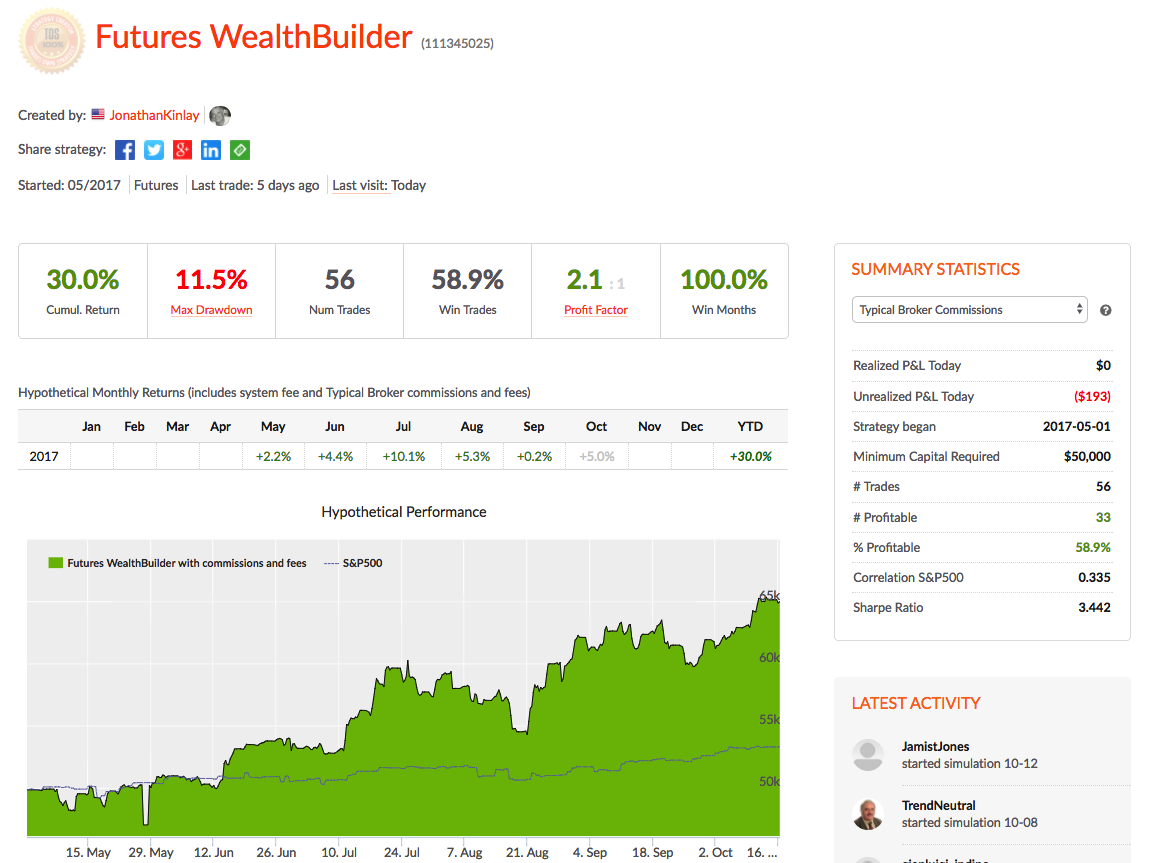
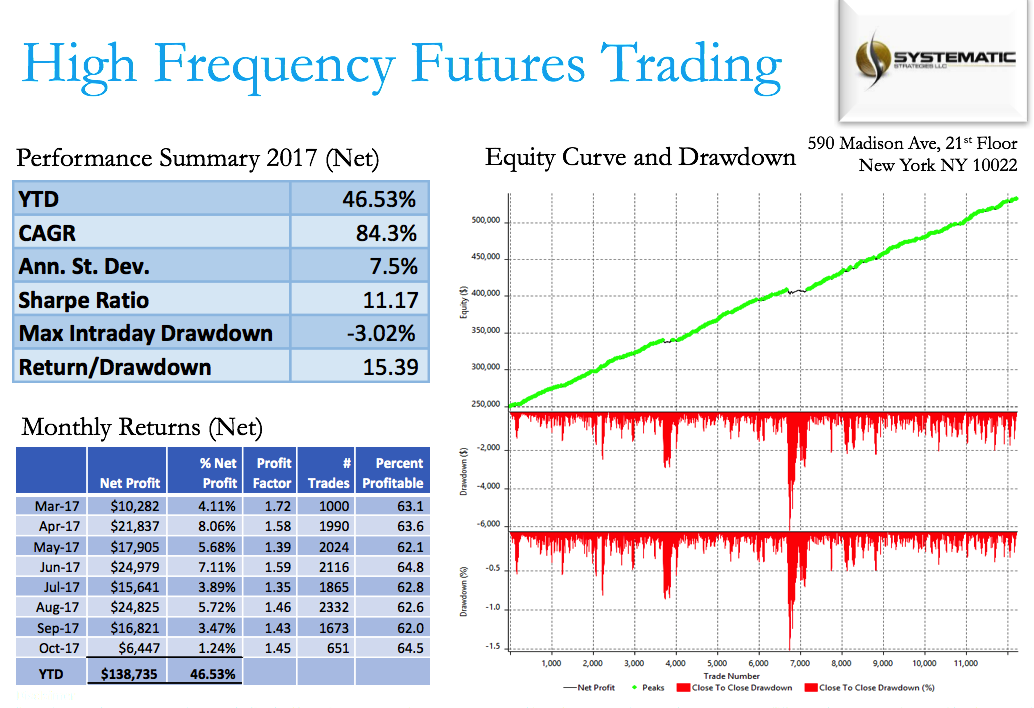
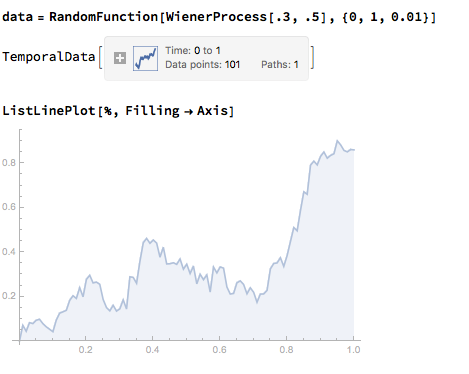
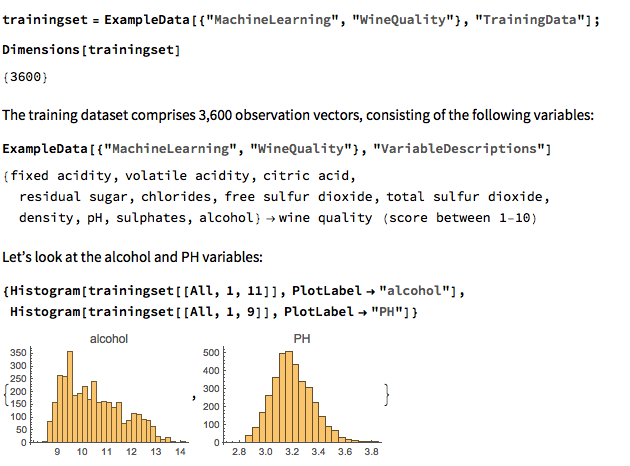
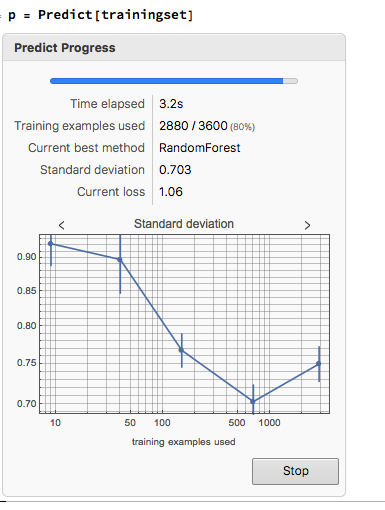
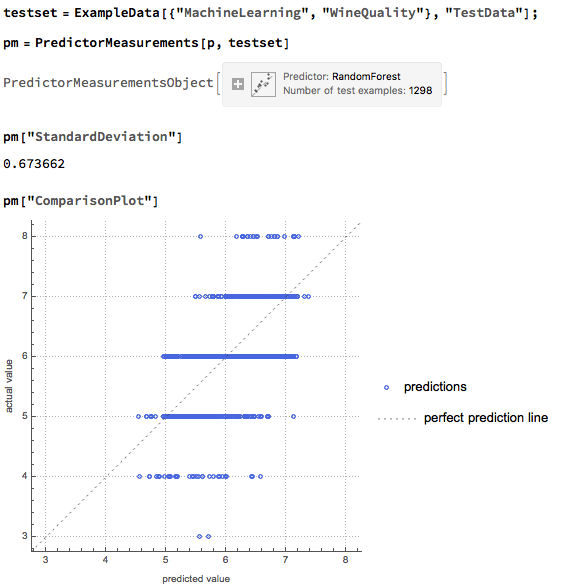
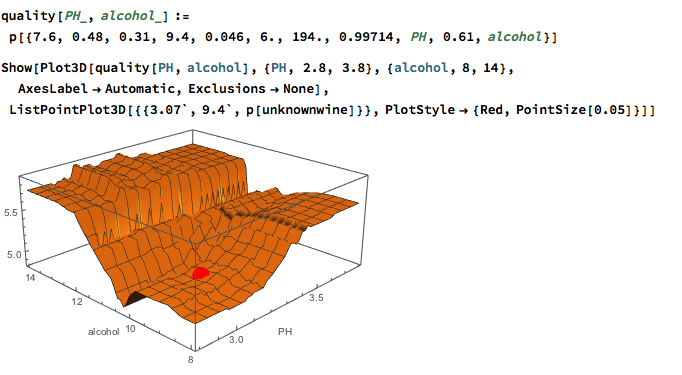
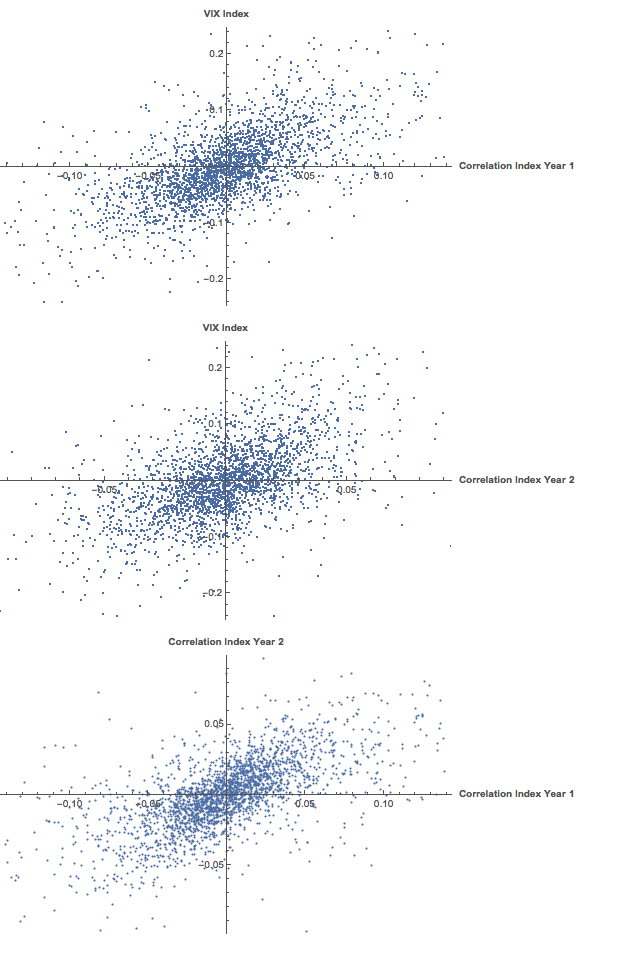
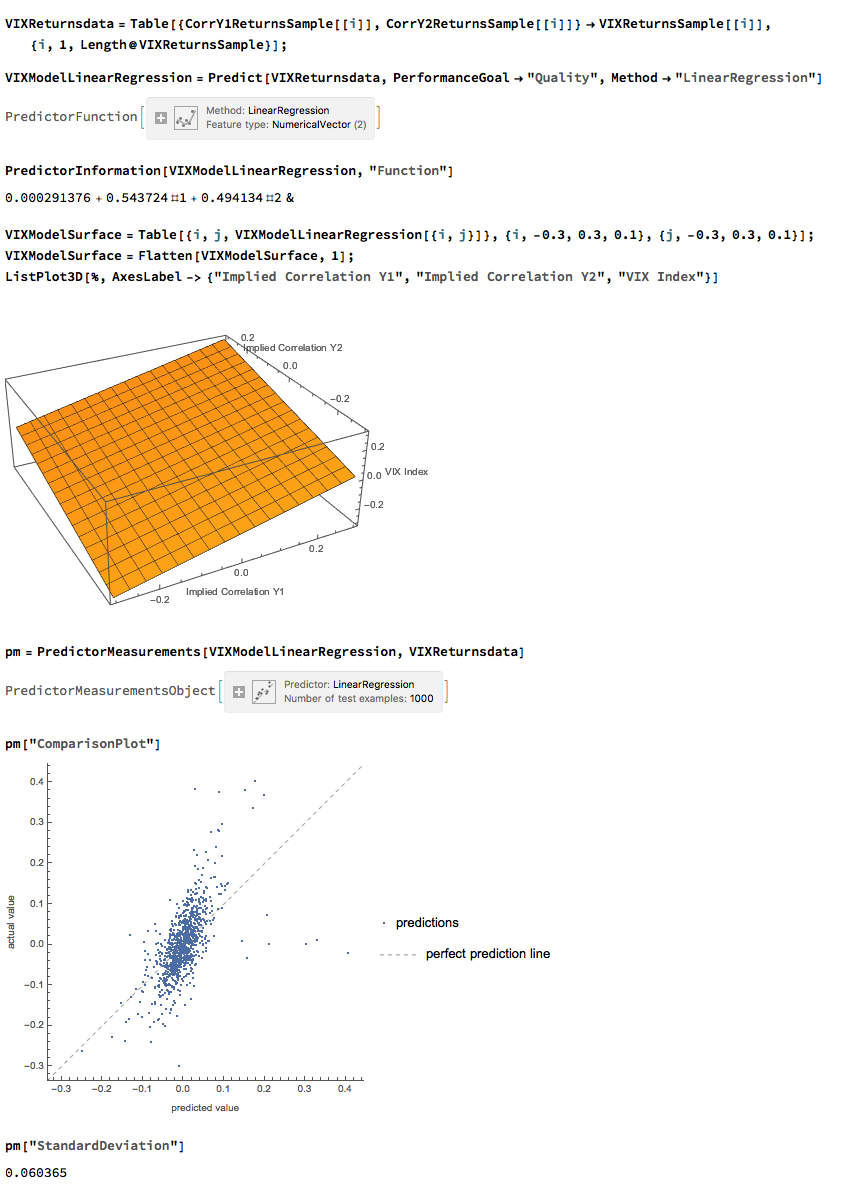
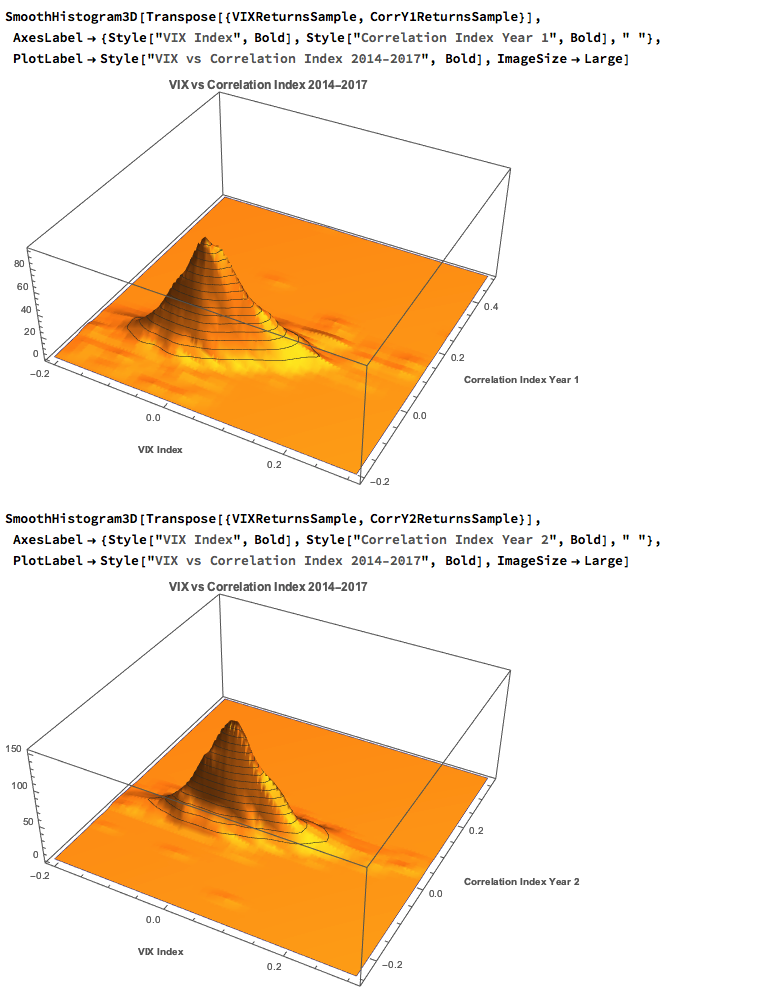
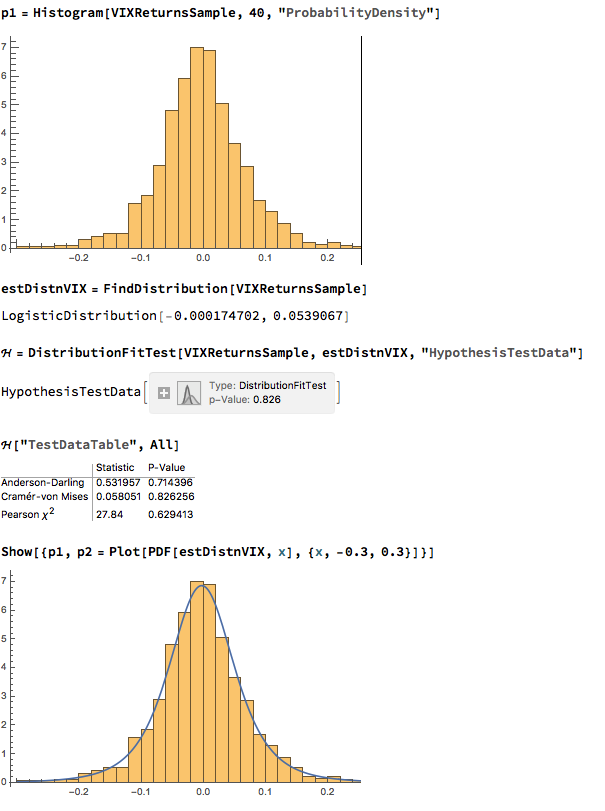
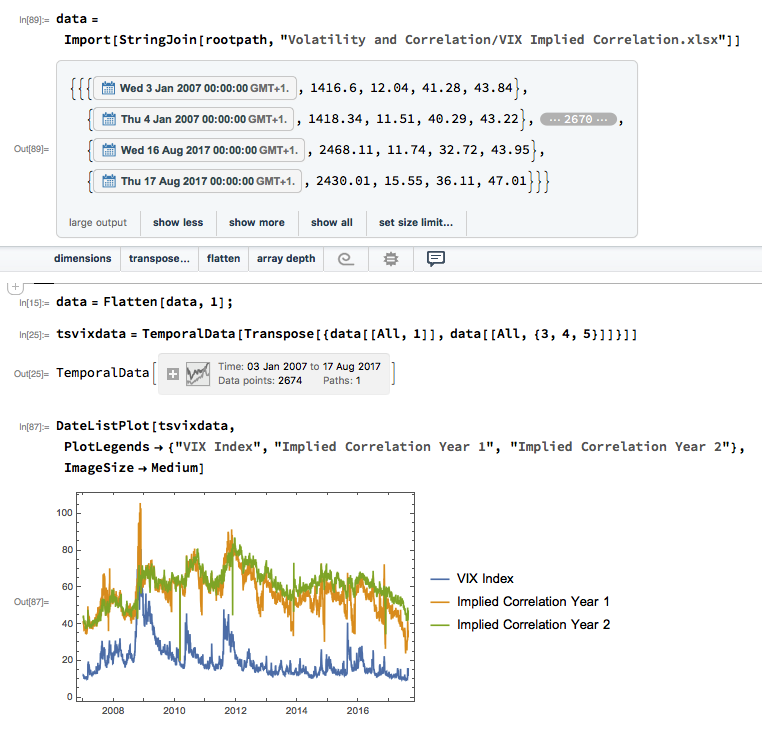
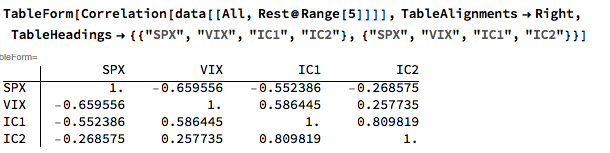
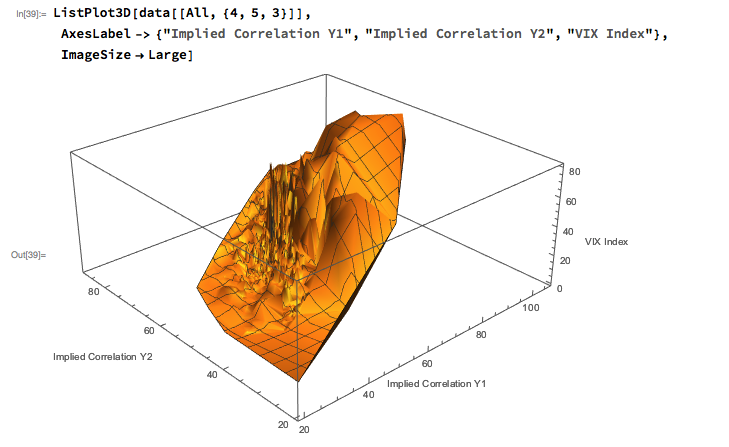
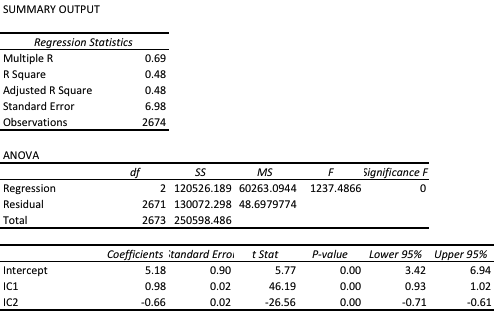
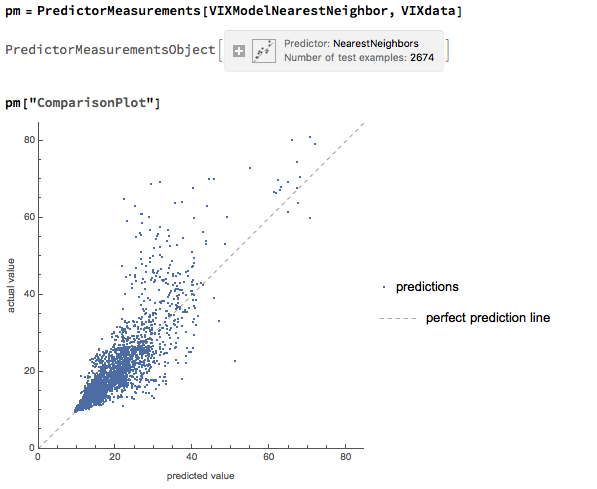
Against this background I and my co-researcher Dan Rico set out to address the question of whether these new techniques really do have predicative power, more specifically the ability to forecast market direction. Using some excellent MatLab toolboxes and a new software package, an Excel Addin called 11Ants, that makes large scale testing of multiple models a snap, we examined over 1,000,000 models and model-ensembles, covering just about every available non-linear technique. The data set for our study comprised daily prices for a selection of US equity securities, together with a large selection of technical indicators for which some other researchers have claimed explanatory power.

The answer provided by our research was, without exception, in the negative: not one of the models tested showed any significant ability to predict the direction of any of the securities in our data set. Furthermore, our study found that the best-performing models favored raw price data over technical indicator variables, suggesting that the latter have little explanatory power.
As with Neural Networks, the principal difficulty with non-linear techniques appears to be curve-fitting and a failure to generalize: while it is very easy to find models that provide an excellent fit to in-sample data, the forecasting performance out-of-sample is often very poor.

Some caveats about our own research apply. First and foremost, it is of course impossible to prove a hypothesis in the negative. Secondly, it is plausible that some markets are less efficient than others: some studies have claimed success in developing predictive models due to the (relative) inefficiency of the F/X and futures markets, for example. Thirdly, the choice of sample period may be criticized: it could be that the models were over-conditioned on a too- lengthy in-sample data set, which in one case ran from 1993 to 2008, with just two years (2009-2010) of out-of-sample data. The choice of sample was deliberate, however: had we omitted the 2008 period from the “learning” data set, it would be very easy to criticize the study for failing to allow the algorithms to learn about the exceptional behavior of the markets during that turbulent year.
Despite these limitations, our research casts doubt on the findings of some less-extensive studies, that may be the result of sample-selection bias. One characteristic of the most credible studies finding evidence in favor of market predictability, such as those by Pesaran and Timmermann, for instance (see paper for citations), is that the models they employ tend to incorporate independent explanatory variables, such as yield spreads, which do appear to have real explanatory power. The finding of our study suggest that, absent such explanatory factors, the ability to predict markets using sophisticated non-linear techniques applied to price data alone may prove to be as illusionary as it was in the 1990’s.
ONE MILLION MODELS



















{kind=link}
{kind=link}