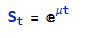
One of the main criticisms levelled at systematic trading over the last few years is that the over-use of historical market data has tended to produce curve-fitted strategies that perform poorly out of sample in a live trading environment. This is indeed a valid criticism – given enough attempts one is bound to arrive eventually at a strategy that performs well in backtest, even on a holdout data sample. But that by no means guarantees that the strategy will continue to perform well going forward.
The solution to the problem has been clear for some time: what is required is a method of producing synthetic market data that can be used to build a strategy and test it under a wide variety of simulated market conditions. A strategy built in this way is more likely to survive the challenge of live trading than one that has been developed using only a single historical data path.
The problem, however, has been in implementation. Up until now all the attempts to produce credible synthetic price data have failed, for one reason or another, as I described in an earlier post:
I have been able to devise a completely new algorithm for generating artificial price series that meet all of the key requirements, as follows:
- Computational simplicity & efficiency. Important if we are looking to mass-produce synthetic series for a large number of assets, for a variety of different applications. Some deep learning methods would struggle to meet this requirement, even supposing that transfer learning is possible.
- The ability to produce price series that are internally consistent (i.e High > Low, etc) in every case .
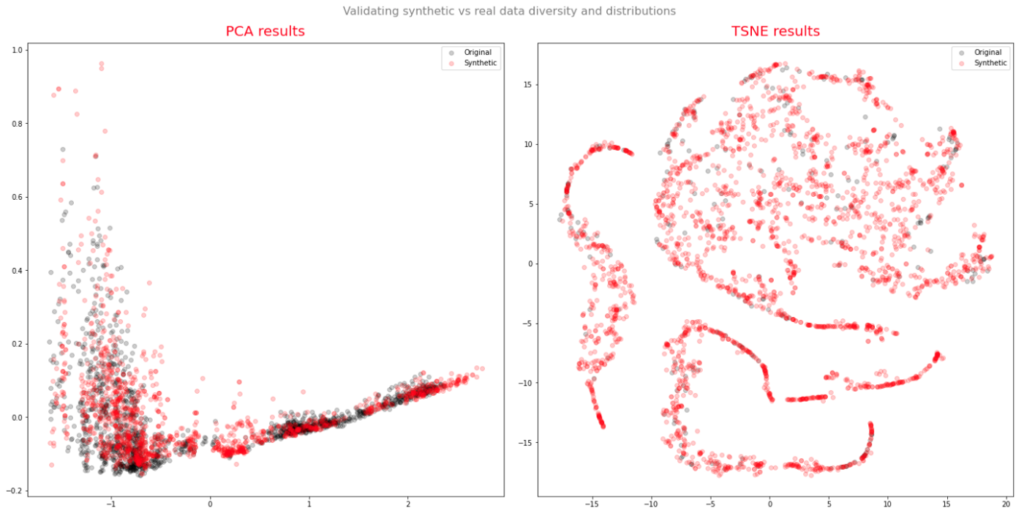
- Should be able to produce a range of synthetic series that vary widely in their correspondence to the original price series. In some case we want synthetic price series that are highly correlated to the original; in other cases we might want to test our investment portfolio or risk control systems under extreme conditions never before seen in the market.
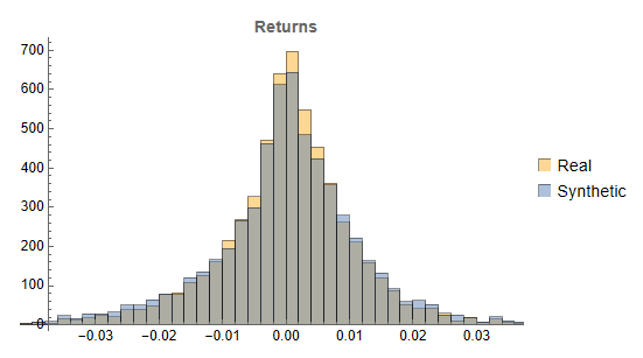
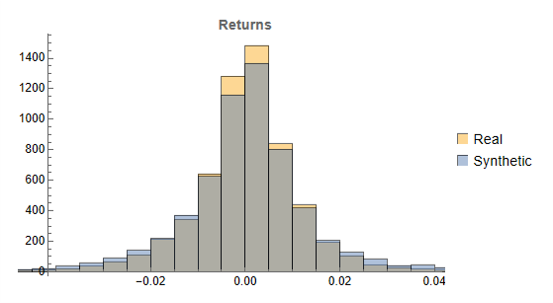
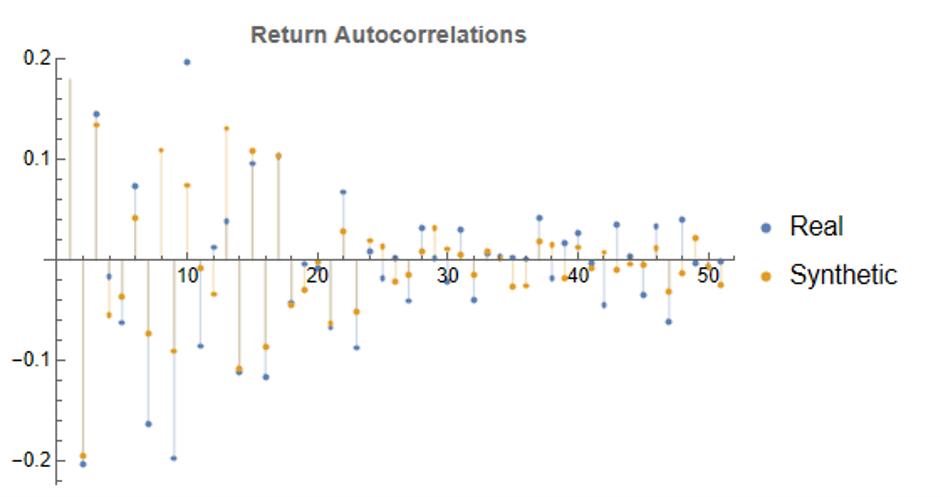
- The distribution of returns in the synthetic series should closely match the historical series, being non-Gaussian and with “fat-tails”.
- The ability to incorporate long memory effects in the sequence of returns.
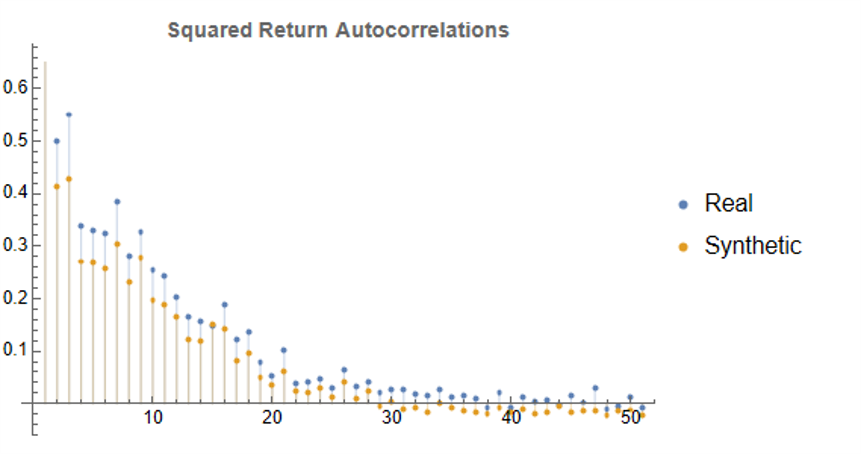
- The ability to model GARCH effects in the returns process.
This means that we are now in a position to develop trading strategies without any direct reference to the underlying market data. Consequently we can then use all of the real market data for out-of-sample back-testing.
Developing a Trading Strategy for the S&P 500 Index Using Synthetic Market Data
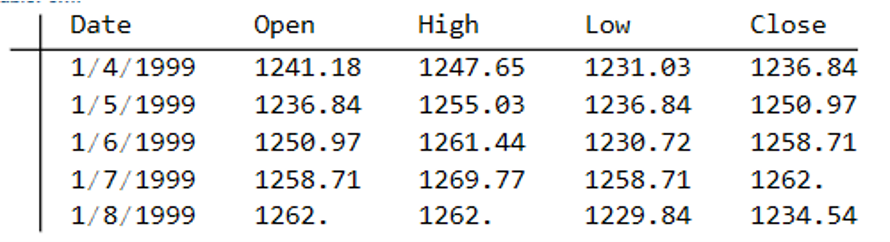
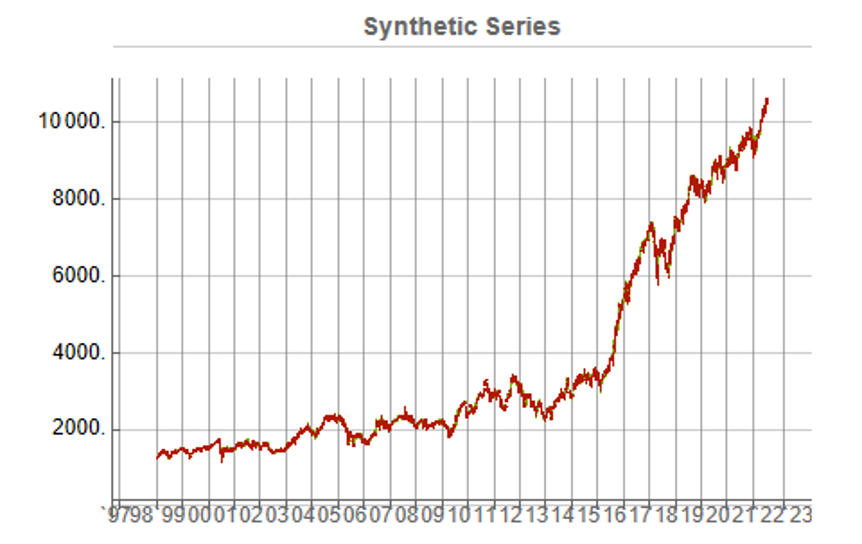
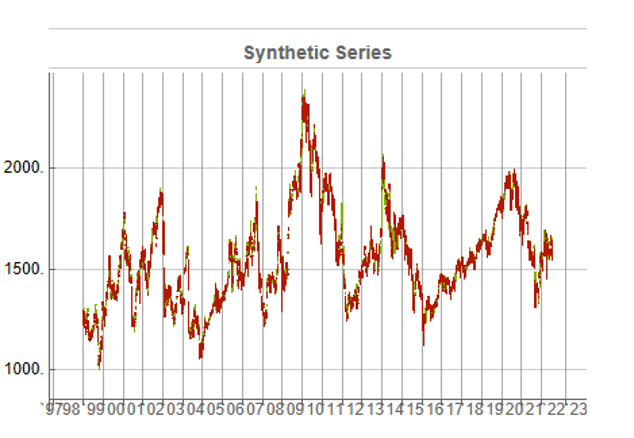
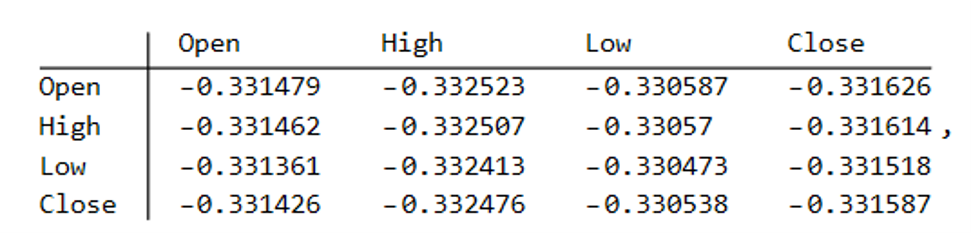
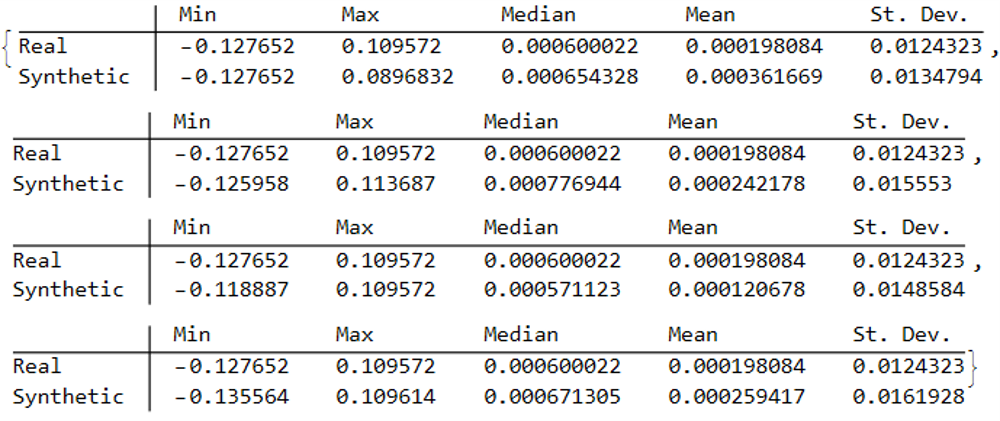
To illustrate the procedure I am going to use daily synthetic price data for the S&P 500 Index over the period from Jan 1999 to July 2022. Details of the the characteristics of the synthetic series are given in the post referred to above.
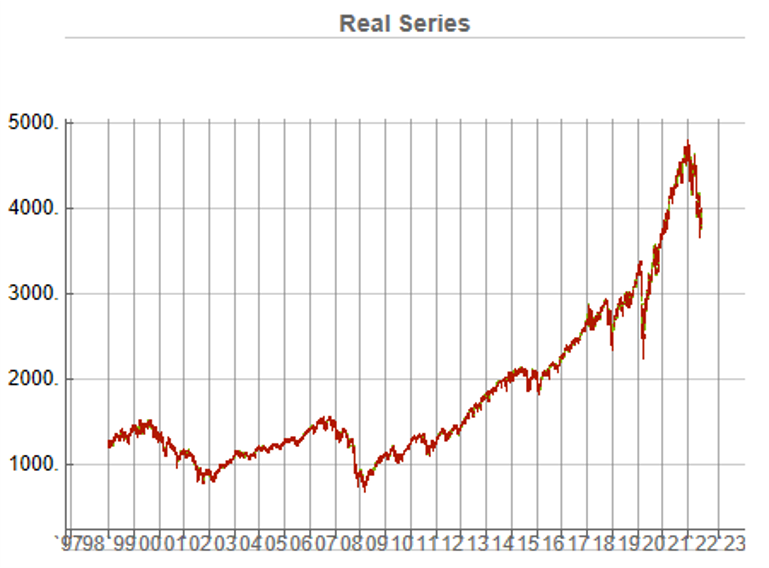
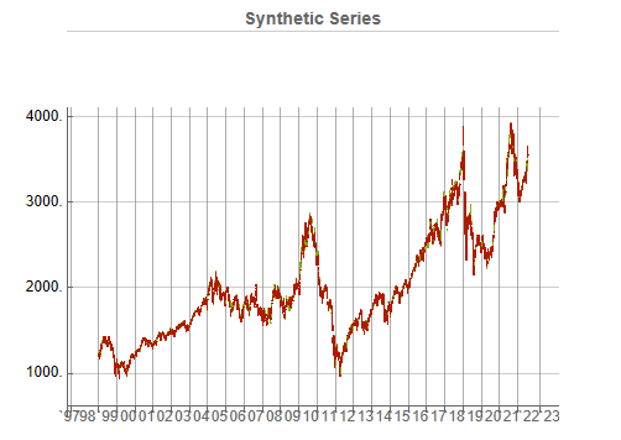
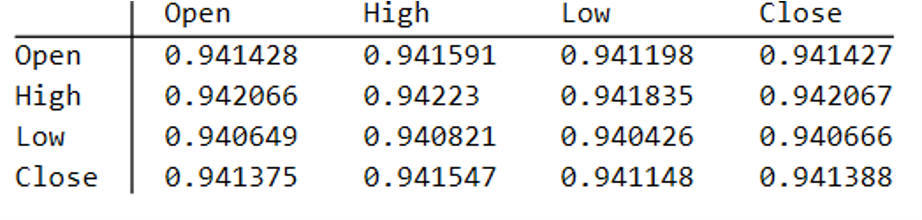
Because we want to create a trading strategy that will perform under market conditions close to those currently prevailing, I will downsample the synthetic series to include only those that correlate quite closely, i.e. with a minimum correlation of 0.75, with the real price data.
Why do this? Surely if we want to make a strategy as robust as possible we should use all of the synthetic data series for model development?
The reason is that I believe that some of the more extreme adverse scenarios generated by the algorithm may occur quite rarely, perhaps once in every few decades. However, I am principally interested in a strategy that I can apply under current market conditions and I am prepared to take my chances that the worst-case scenarios are unlikely to come about any time soon. This is a major design decision, one that you may disagree with. Of course, one could make use of every available synthetic data series in the development of the trading model and by doing so it is likely that you would produce a model that is more robust. But the training could take longer and the performance during normal market conditions may not be as good.
Having generated the price series, the process I am going to follow is to use genetic programming to develop trading strategies that will be evaluated on all of the synthetic data series simultaneously. I will then use the performance of the aggregate portfolio, i.e. the outcome of all of the trades generated by the strategy when applied to all of the synthetic series, to assess the overall performance. In order to be considered, candidate strategies have to perform well under all of the different market scenarios, or at least the great majority of them. This ensures that the strategy is likely to prove more robust across different types of market conditions, rather than on just the single type of market scenario observed in the real historical series.
As usual in these cases I will reserve a portion (10%) of each data series for testing each strategy, and a further 10% sample for out-of-sample validation. This isn’t strictly necessary: since the real data series has not be used directly in the development of the trading system, we can later test the strategy on all of the historical data and regard this as an out-of-sample backtest.
To implement the procedure I am going to use Mike Bryant’s excellent Adaptrade Builder software.
This is an exemplar of outstanding software engineering and provides a broad range of features for generating trading strategies of every kind. One feature of Builder that is particularly useful in this context is its ability to construct strategies and test them on up to 20 data series concurrently. This enables us to develop a strategy using all of the synthetic data series simultaneously, showing the performance of each individual strategy as well for as the aggregate portfolio.
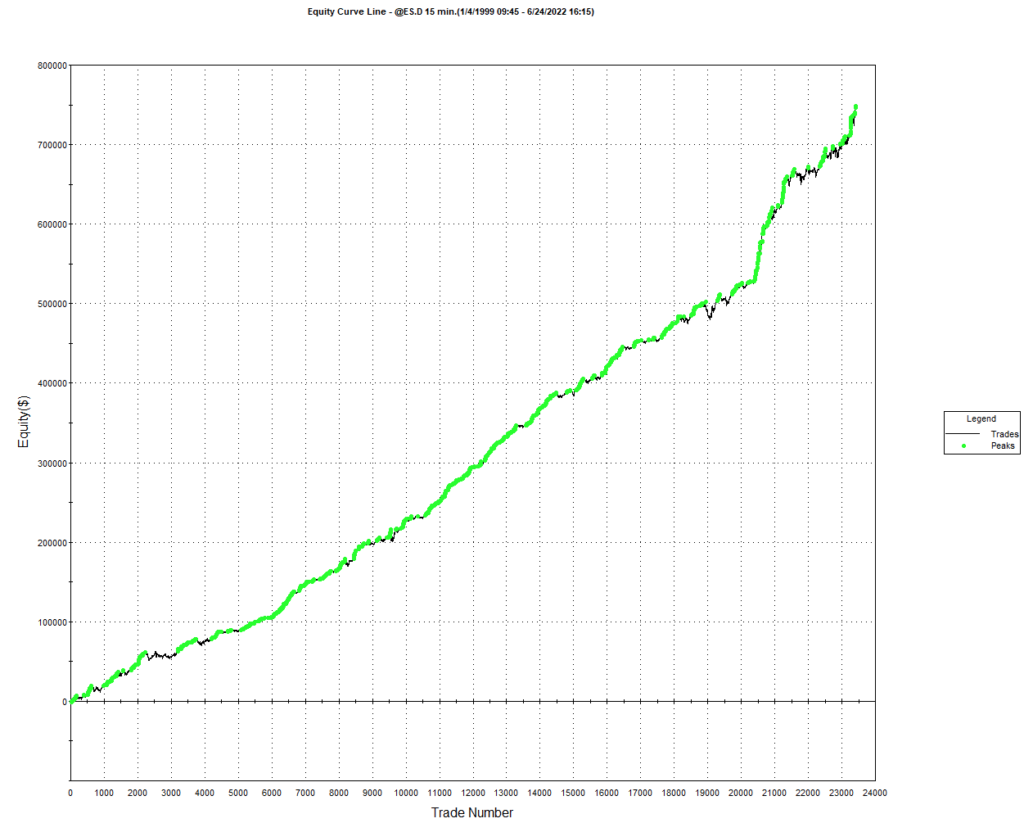
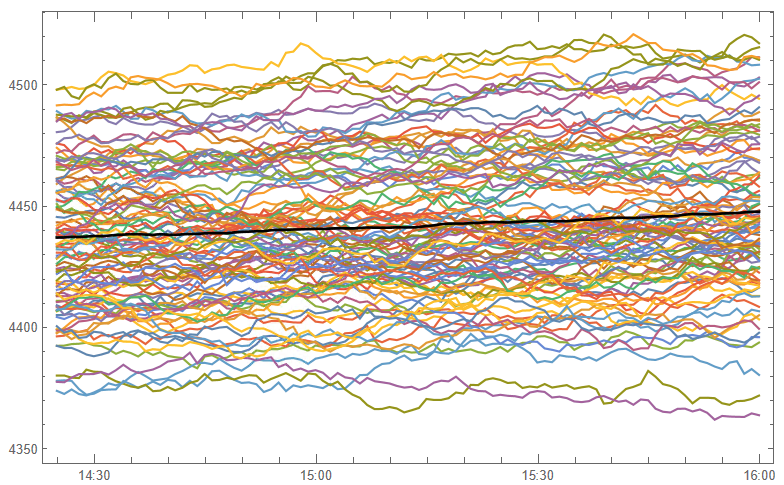
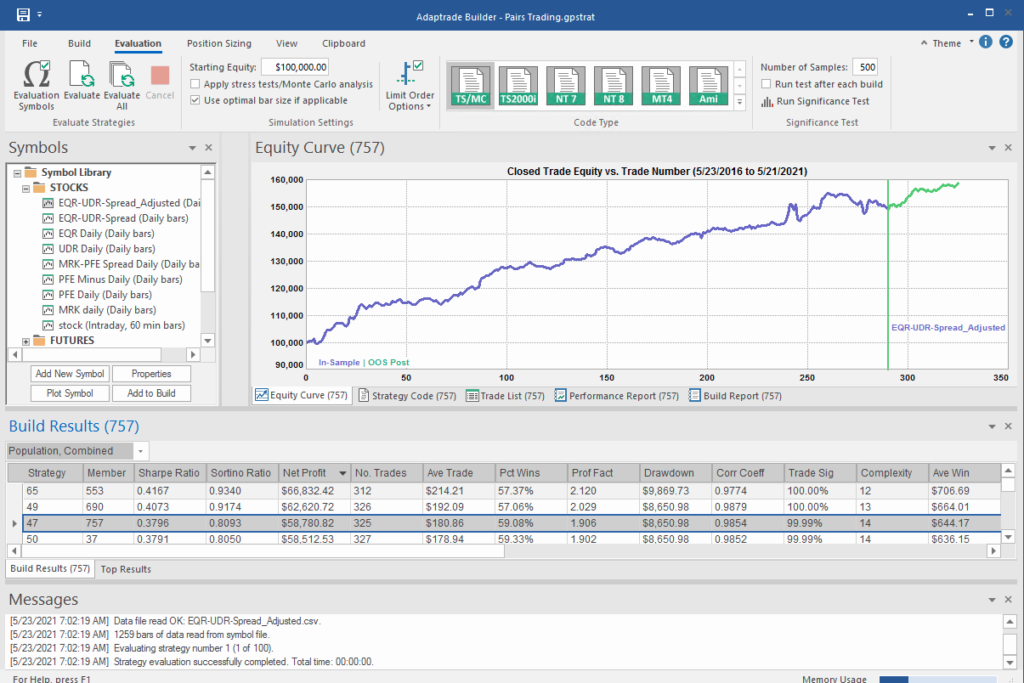
After evolving strategies for 50 generations we arrive at the following outcome:
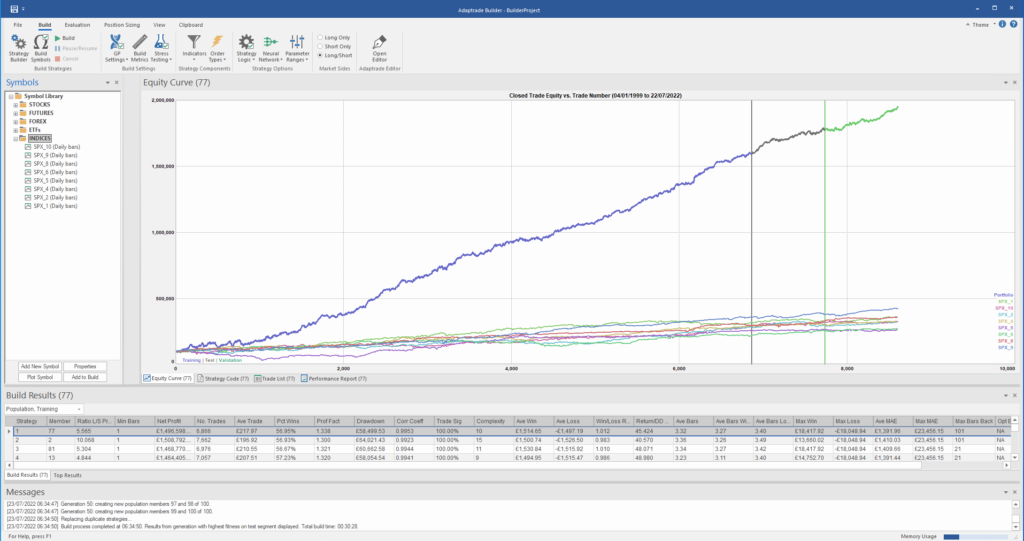
The equity curve for the aggregate portfolio is shown in blue, while the equity curves for the strategy applied to individual synthetic data series are shown towards the bottom of the chart. Of course, the performance of the aggregate portfolio appears much superior to any of the individual strategies, because it is effectively the arithmetic sum of the individual equity curves. And just because the aggregate portfolio appears to perform well both in-sample and out-of-sample, that doesn’t imply that the strategy works equally well for every individual market scenario. In some scenarios it performs better than in others, as can be observed from the individual equity curves.
But, in any case, our objective here is not to create a stock portfolio strategy, but rather to trade a single asset – the S&P 500 Index. The role of the aggregate portfolio is simply to suggest that we may have found a strategy that is sufficiently robust to work well across a variety of market conditions, as represented by the various synthetic price series.
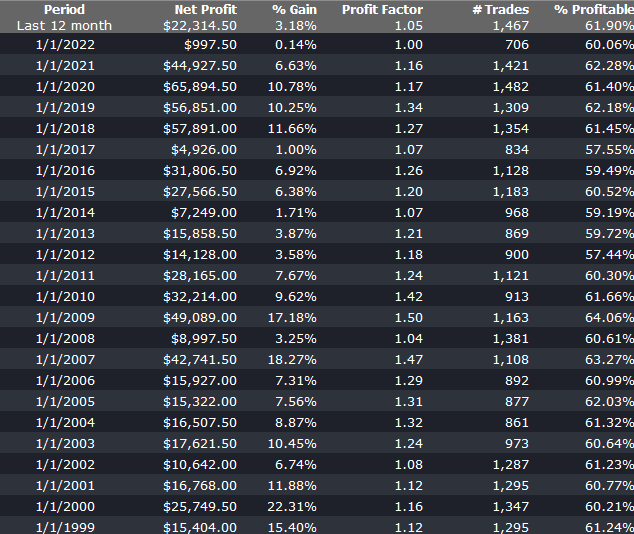
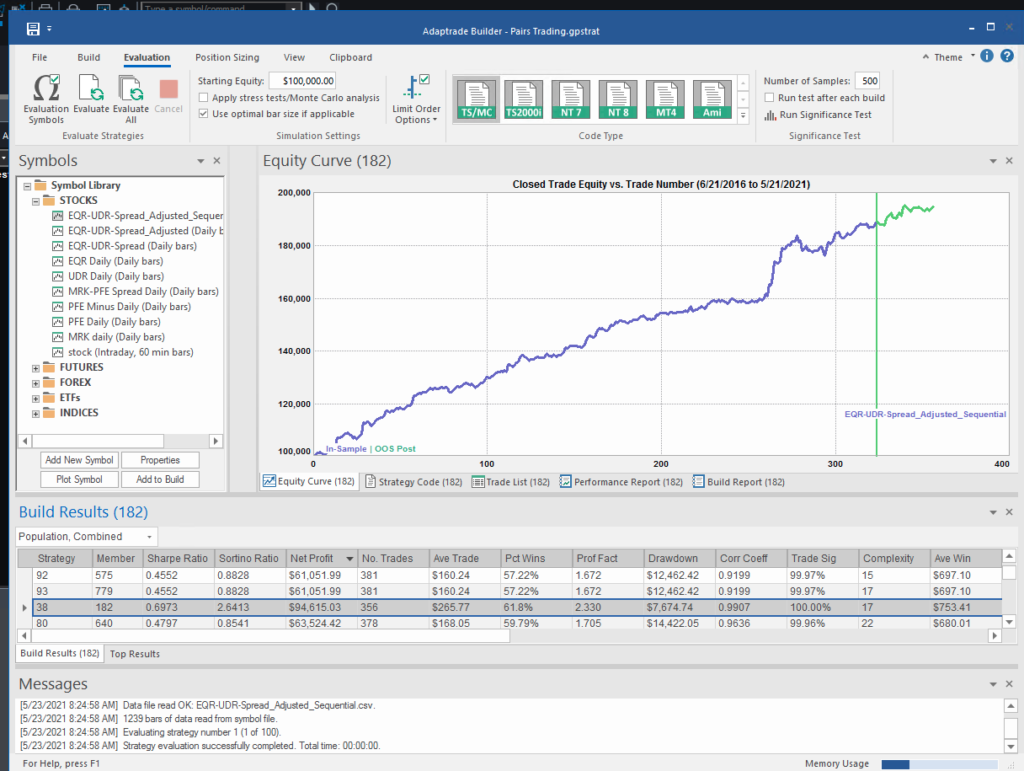
Builder generates code for the strategies it evolves in a number of different languages and in this case we take the EasyLanguage code for the fittest strategy #77 and apply it to a daily chart for the S&P 500 Index – i.e. the real data series – in Tradestation, with the following results:
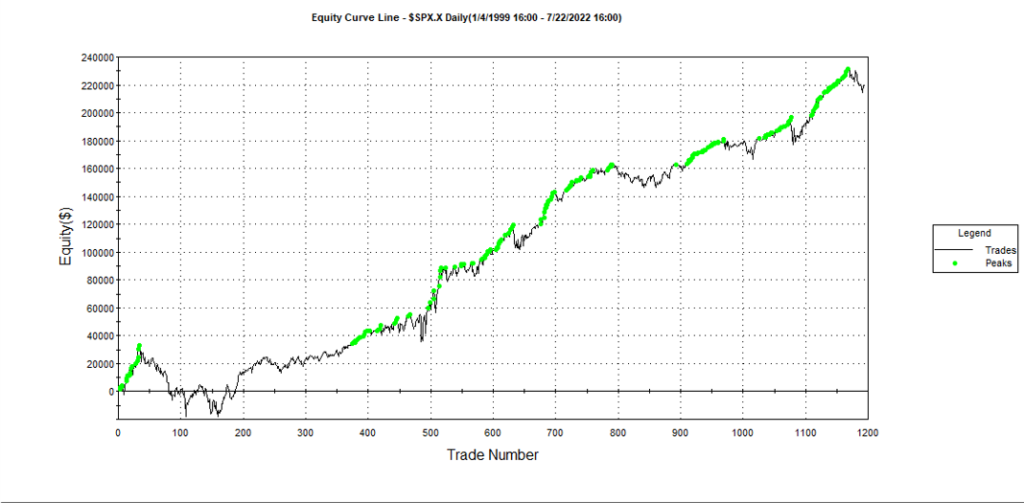
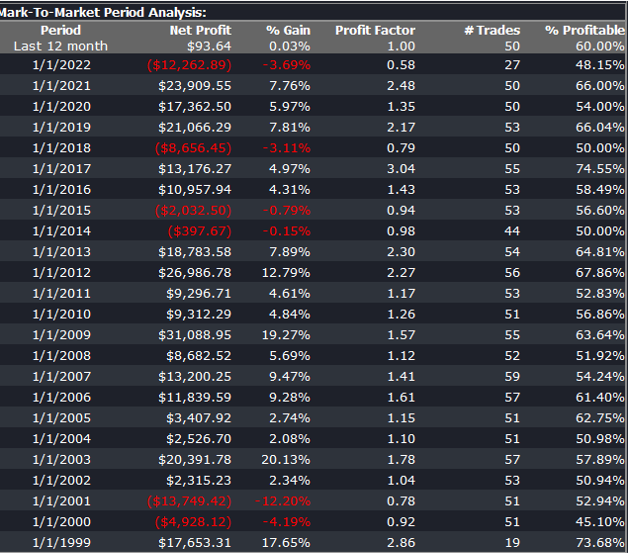
The strategy appears to work well “out-of-the-box”, i,e, without any further refinement. So our quest for a robust strategy appears to have been quite successful, given that none of the 23-year span of real market data on which the strategy was tested was used in the development process.
We can take the process a little further, however, by “optimizing” the strategy. Traditionally this would mean finding the optimal set of parameters that produces the highest net profit on the test data. But this would be curve fitting in the worst possible sense, and is not at all what I am suggesting.
Instead we use a procedure known as Walk Forward Optimization (WFO), as described in this post:
The goal of WFO is not to curve-fit the best parameters, which would entirely defeat the object of using synthetic data. Instead, its purpose is to test the robustness of the strategy. We accomplish this by using a sequence of overlapping in-sample and out-of-sample periods to evaluate how well the strategy stands up, assuming the parameters are optimized on in-sample periods of varying size and start date and tested of similarly varying out-of-sample periods. A strategy that fails a cluster of such tests is unlikely to prove robust in live trading. A strategy that passes a test cluster at least demonstrates some capability to perform well in different market regimes.
To some extent we might regard such a test as unnecessary, given that the strategy has already been observed to perform well under several different market conditions, encapsulated in the different synthetic price series, in addition to the real historical price series. Nonetheless, we conduct a WFO cluster test to further evaluate the robustness of the strategy.
As the goal of the procedure is not to maximize the theoretical profitability of the strategy, but rather to evaluate its robustness, we select a criterion other than net profit as the factor to optimize. Specifically, we select the sum of the areas of the strategy drawdowns as the quantity to minimize (by maximizing the inverse of the sum of drawdown areas, which amounts to the same thing). This requires a little explanation.
If we look at the strategy drawdown periods of the equity curve, we observe several periods (highlighted in red) in which the strategy was underwater:
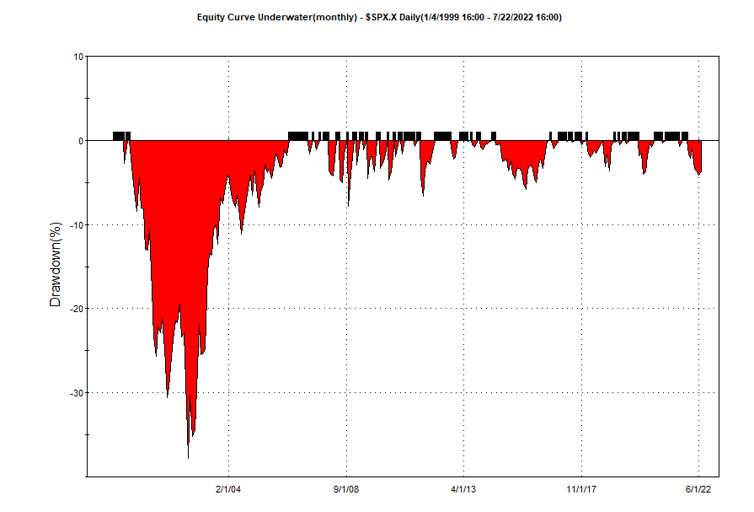
The area of each drawdown represents the length and magnitude of the drawdown and our goal here is to minimize the sum of these areas, so that we reduce both the total duration and severity of strategy drawdowns.
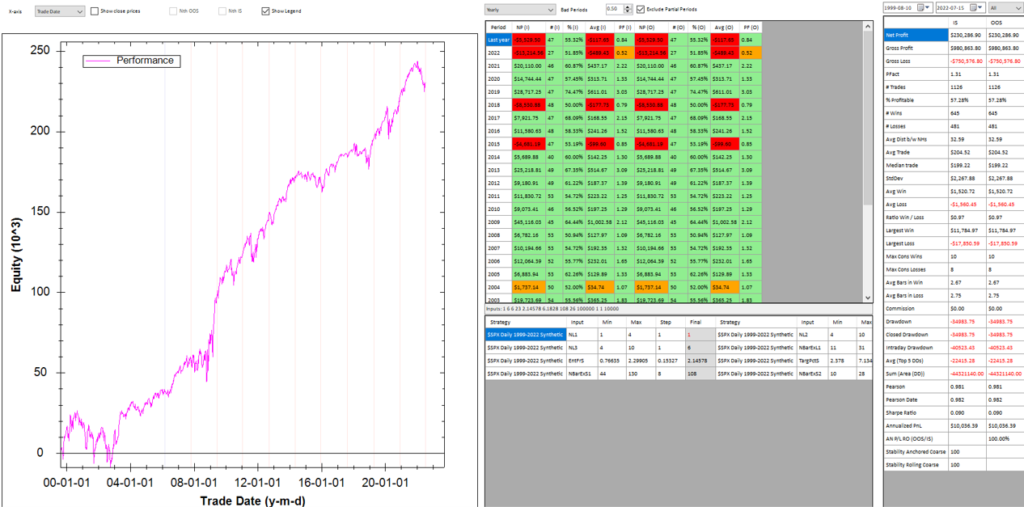
In each WFO test we use different % of OOS data and a different number of runs, assessing the performance of the strategy on a battery of different criteria:
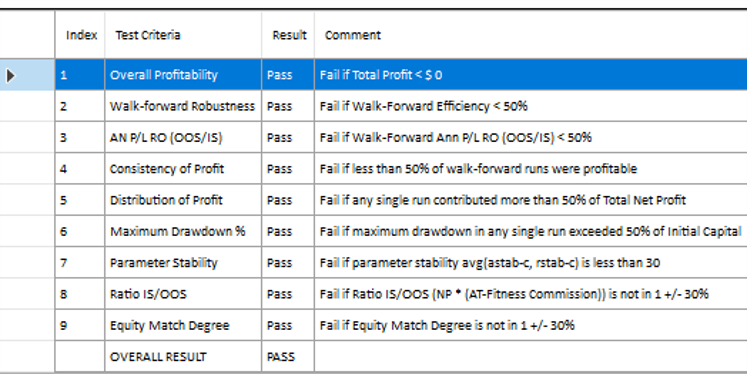
These criteria not only include overall profitability, but also factors such as parameter stability, profit consistency in each test, the ratio of in-sample to out-of-sample profits, etc. In other words, this WFO cluster analysis is not about profit maximization, but robustness evaluation, as assessed by these several different metrics. And in this case the strategy passes every test with flying colors:
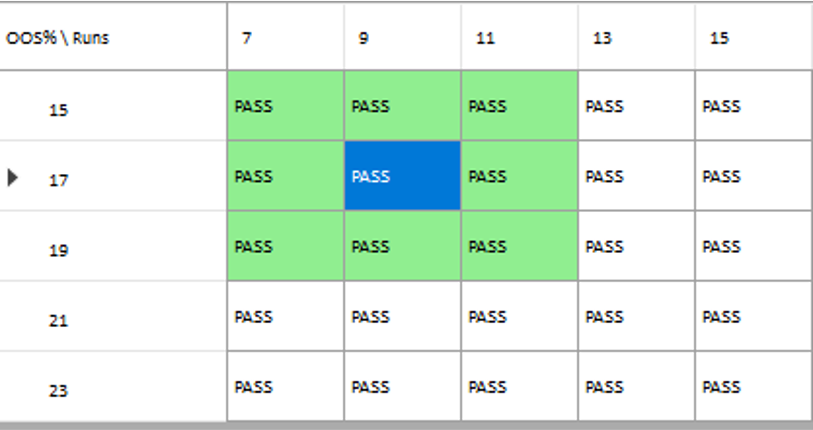
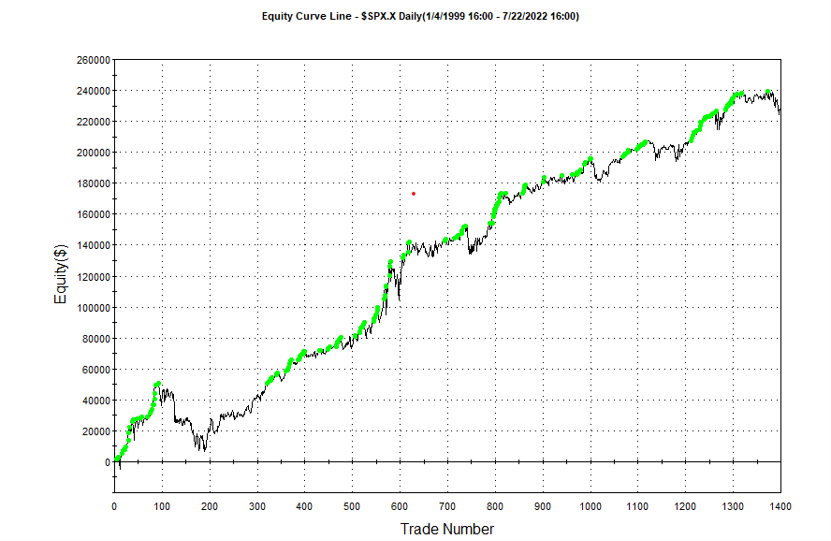
Other than validating the robustness of the strategy’s performance, the overall effect of the procedure is to slightly improve the equity curve by diminishing the magnitude and duration of the drawdown periods:
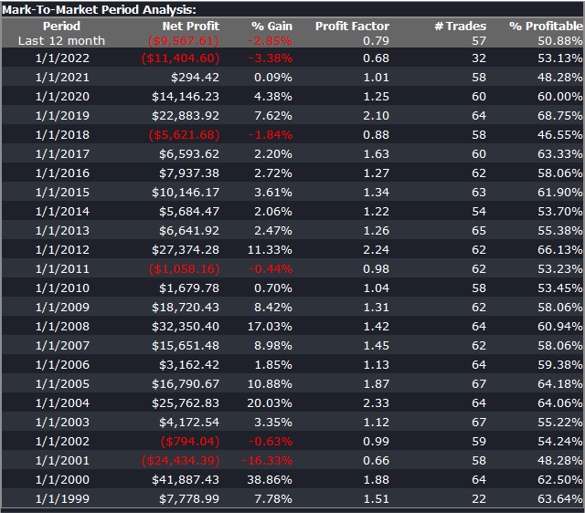
Conclusion
We have shown how, by using synthetic price series, we can build a robust trading strategy that performs well under a variety of different market conditions, including on previously “unseen” historical market data. Further analysis using cluster WFO tests strengthens the assessment of the strategy’s robustness.