Decomposing Asset Returns
We can decompose the returns process Rt as follows:
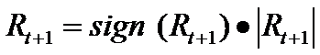
While the left hand side of the equation is essentially unforecastable, both of the right-hand-side components of returns display persistent dynamics and hence are forecastable. Both the signs of returns and magnitude of returns are conditional mean dependent and hence forecastable, but their product is conditional mean independent and hence unforecastable. This is an example of a nonlinear “common feature” in the sense of Engle and Kozicki (1993).
Although asset returns are essentially unforecastable, the same is not true for asset return signs (i.e. the direction-of-change). As long as expected returns are nonzero, one should expect sign dependence, given the overwhelming evidence of volatility dependence. Even in assets where expected returns are zero, sign dependence may be induced by skewness in the asset returns process. Hence market timing ability is a very real possibility, depending on the relationship between the mean of the asset returns process and its higher moments. The highly nonlinear nature of the relationship means that conditional sign dependence is not likely to be found by traditional measures such as signs autocorrelations, runs tests or traditional market timing tests. Sign dependence is likely to be strongest at intermediate horizons of 1-3 months, and unlikely to be important at very low or high frequencies. Empirical tests demonstrate that sign dependence is very much present in actual US equity returns, with probabilities of positive returns rising to 65% or higher at various points over the last 20 years. A simple logit regression model captures the essentials of the relationship very successfully.
Now consider the implications of dependence and hence forecastability in the sign of asset returns, or, equivalently, the direction-of-change. It may be possible to develop profitable trading strategies if one can successfully time the market, regardless of whether or not one is able to forecast the returns themselves.
There is substantial evidence that sign forecasting can often be done successfully. Relevant research on this topic includes Breen, Glosten and Jaganathan (1989), Leitch and Tanner (1991), Wagner, Shellans and Paul (1992), Pesaran and Timmerman (1995), Kuan and Liu (1995), Larsen and Wozniak (10050, Womack (1996), Gencay (1998), Leung Daouk and Chen (1999), Elliott and Ito (1999) White (2000), Pesaran and Timmerman (2000), and Cheung, Chinn and Pascual (2003).
There is also a huge body of empirical research pointing to the conditional dependence and forecastability of asset volatility. Bollerslev, Chou and Kramer (1992) review evidence in the GARCH framework, Ghysels, Harvey and Renault (1996) survey results from stochastic volatility modeling, while Andersen, Bollerslev and Diebold (2003) survey results from realized volatility modeling.
Sign Dynamics Driven By Volatility Dynamics
Let the returns process Rt be Normally distributed with mean m and conditional volatility st.
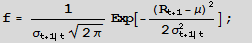
The probability of a positive return Pr[Rt+1 >0] is given by the Normal CDF F=1-Prob[0,f]

For a given mean return, m, the probability of a positive return is a function of conditional volatility st. As the conditional volatility increases, the probability of a positive return falls, as illustrated in Figure 1 below with m = 10% and st = 5% and 15%.
In the former case, the probability of a positive return is greater because more of the probability mass lies to the right of the origin. Despite having the same, constant expected return of 10%, the process has a greater chance of generating a positive return in the first case than in the second. Thus volatility dynamics drive sign dynamics.
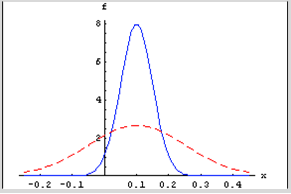
Figure 1
Email me at jkinlay@investment-analytics.com.com for a copy of the complete article.