One of the issues that comes up regularly is how, as an investor or other interested party, one can protect oneself from unscrupulous scam artists posing as professional traders or money managers. This is a particular problem on web sites featuring trader forums, where individuals with unverified track records claiming stellar trading histories use their purported trading “prowess” to try to impress and intimidate other participants, usually impressionable newbies. The purpose of this post is to provide some guidance to help investors, traders and other fellow travelers sort the wheat from the chaff. We’ll be doing some forensic analysis on the track record for a strategy in NG futures that one such character recently posted in one of these forums, as a classic example of the kind of fakery I am describing.
One thing you should understand about scam artists operating on forums, is that they don’t work alone: usually they have a bunch of groupies who will shill for them at every opportunity and who will try to shout down any investigative questioning. Don’t be deterred. These know-it-alls are usually just ignorant dupes, who understand no more about trading than the scam artist. They may just as easily be fellow-scam artists themselves.
THE FIRST BIG RED FLAG: UNWILLINGNESS TO PRODUCE A TRACK RECORD
Anyone claiming to be a CTA or professional money manager (or whose shills claim he is one) has to have a track record that is freely available in the public domain. So how does a scam artist overcome a challenge to produce it? He will claim that he “can’t advertise”, or make some other, similar excuse. Don’t accept that at face value. Ask him to PM it to you. If he won’t, there’s already a high probability he’s a con artist.
THE SECOND BIG RED FLAG: CURVE FITTING
Let’s say our suspect meets the challenge and produces a track record. Ideally this will be an audited P&L statement, but let’s assume for the purposes of this discussion that he produces something along the lines of the Performance Reports produced by a product like Tradestation or MultiCharts, i.e. we are dealing with a simulated back-test.
If your suspect produces a back-test, you can be pretty sure it’s going to look good – otherwise he wouldn’t produce it. The task now is to dig into those reports to spot the red flags that give clues as to whether it might be fake.
Now of course any trading system is going to make assumptions – about fill rates, slippage, commissions, capacity etc. All that is fine, as long as the assumptions are clearly stated. You might want to challenge any or all of the assumptions, and the trader may disagree with you about some or all of them. That’s perfectly ok – it’s an honest, open discussion about a set of investment assumptions that have been revealed at the outset.
But here is what is NOT ok: any opacity about which data was used to build the trading model and which data was used to test it. The former, the in-sample (IS) data set, used to construct the model, must be entirely separate and distinct from the out-of-sample (OOS) data set. It is trivially easy using a tool like Tradestation to produce a trading system that shows stellar results in-sample, but which will immediately crash and burn when it is used in live trading. This is known as curve-fitting. And it’s by far the most common method by which scam artists try to dupe investors.
In order to demonstrate the robustness of the system prior to risking real money, a genuine trader will test his system OOS and show you the results. What you are looking for ideally is congruity between the IS and OOS results. Now by congruity, I don’t mean that they should be identical. Far from it – markets evolve and strategy performance will vary over time. But what you are hoping is that the key performance metrics in the OOS and IS periods, such as annual returns, Sharpe ratio, PNL per contract, profit ratio and win rate, will be comparable. At the very least, you would like to be able to identify some portion of the IS data set for which the strategy performance characteristics are similar to those in the OOS period.
Any – I mean ANY – ambiguity or lack of clarity about which data was used to build the model and which was used for OOS testing is a HUGE red flag. Chances are, your scam artist is already trying to fudge the issue that he curve-fitted the system.
This was the case in the recent forum post we are using as a test case. The trader made no attempt whatsoever to clarify which data was used for model development and which for testing. Immediately, I was suspicious and began looking for other evidence of curve fitting. It didn’t take me long to find it.
THE THIRD BIG RED FLAG: THE EQUITY CURVE
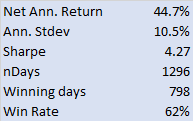
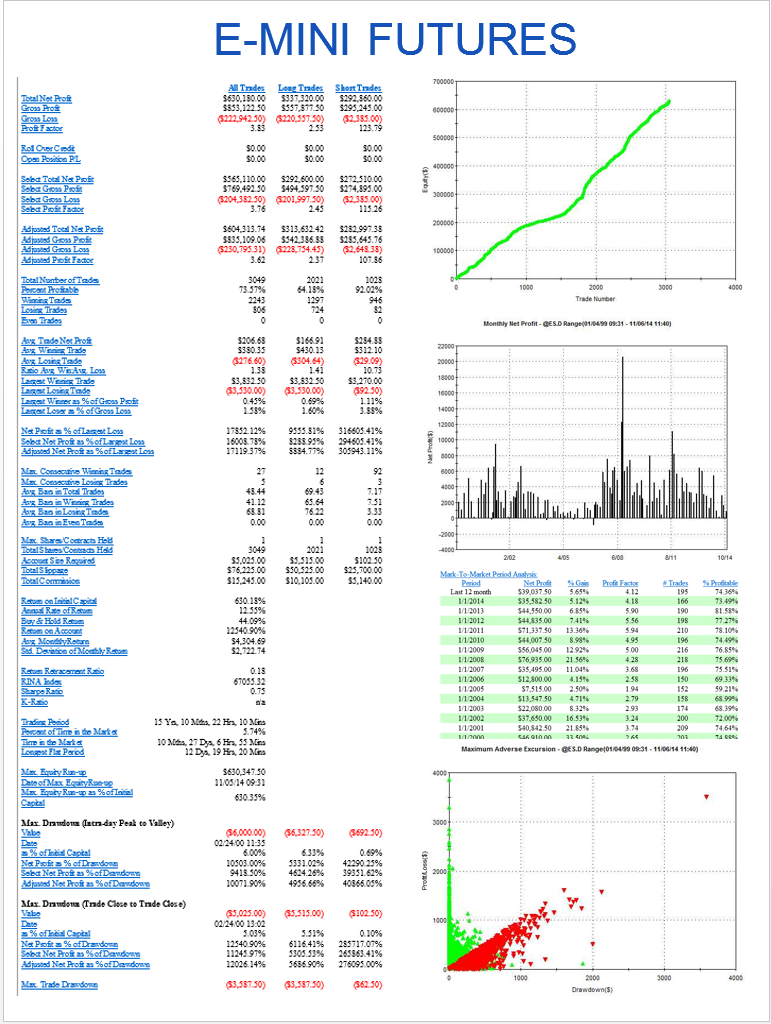
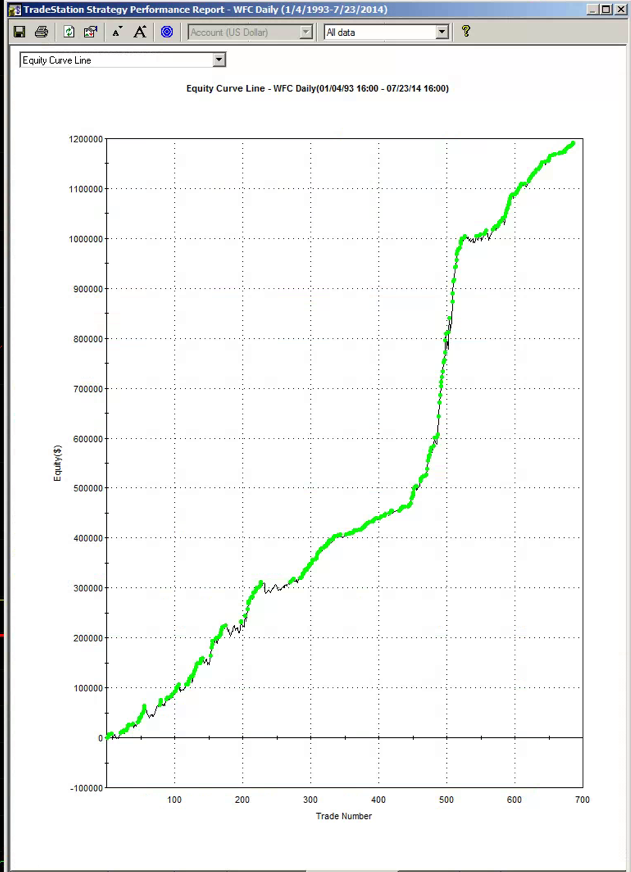
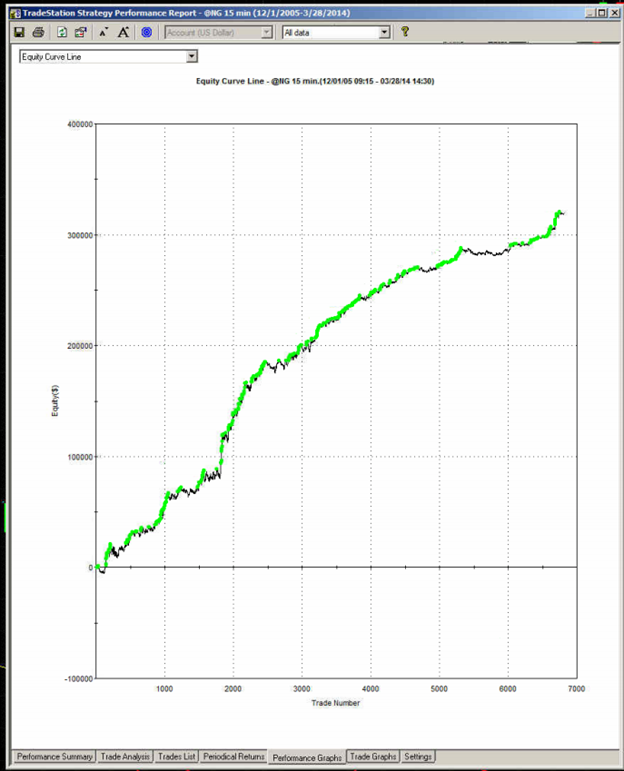
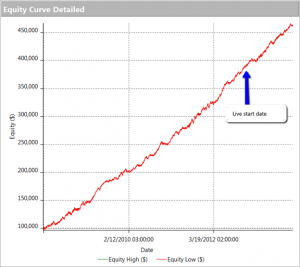
The first item I turned to in the performance reports was the equity curve and I immediately spotted two rather large clues that I was dealing with a fake.
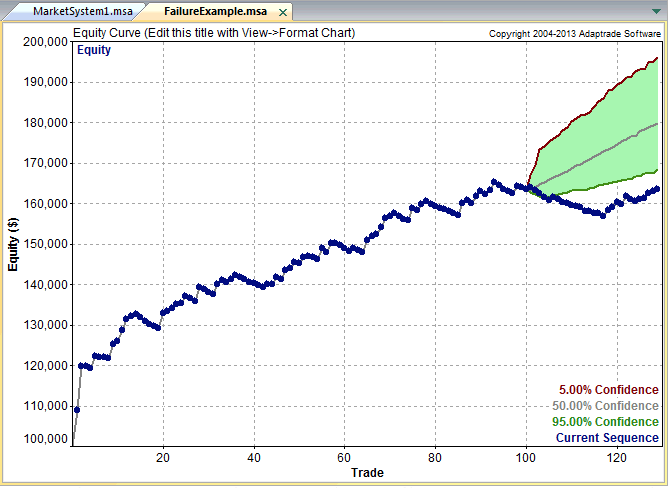
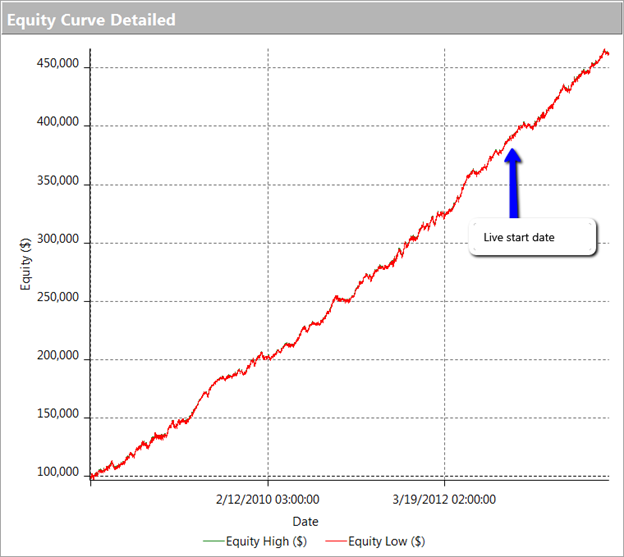
The first clue was the large sign on the chart labelled “live start date”. What does this mean? This is a back-test, so all of the results are theoretical, including those after the supposed “live start date” sometime in 2013. What the faker is trying to do is imply the part of the equity curve shown after that date indicate actual performance results. He doesn’t actually claim this, so he has plausible deniability if you call him on it (“I said it was just a back test”). But he hopes that you won’t, and that, by default, you’ll accept these results are real. But they aren’t.
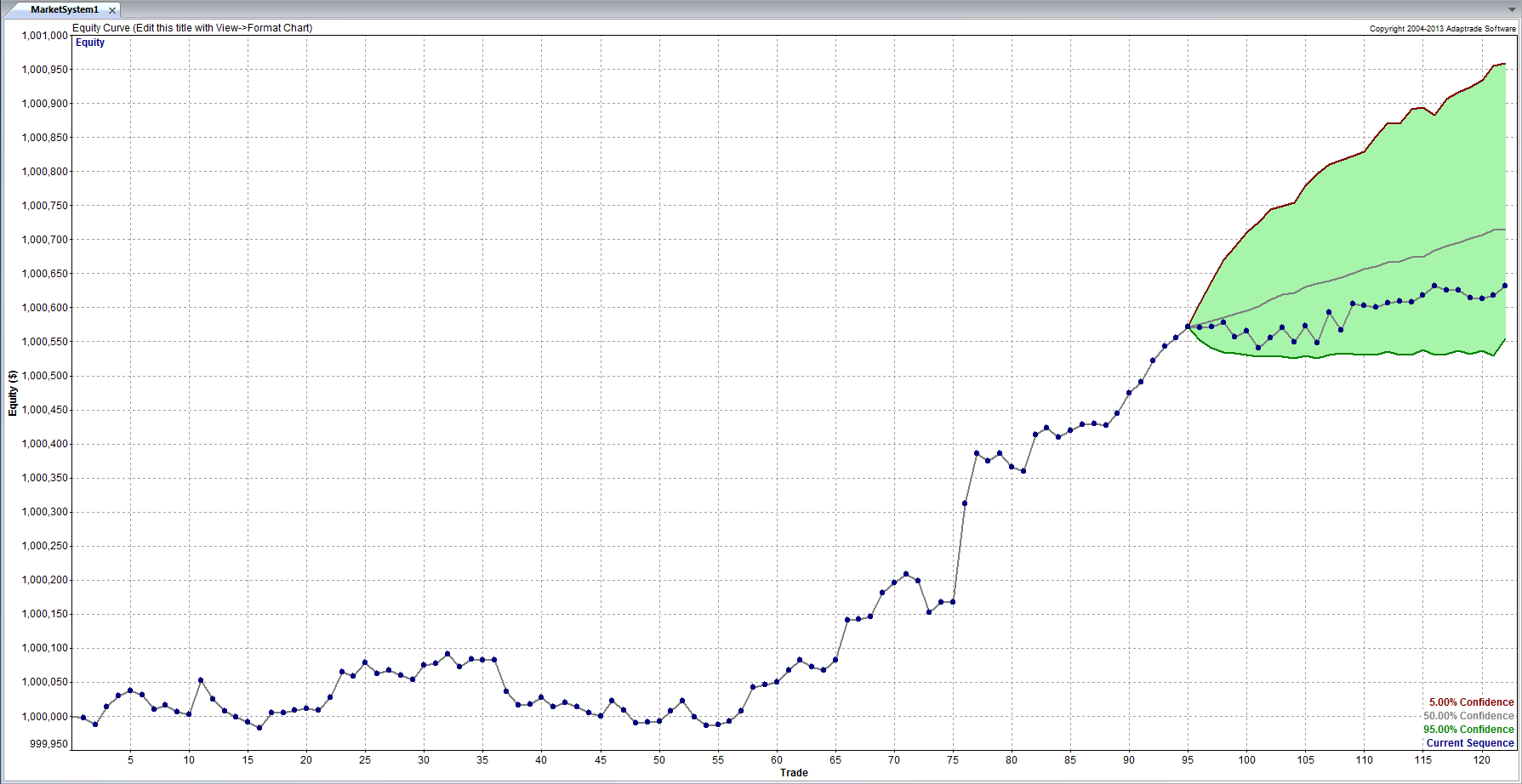
The second clue of fakery is much more important: the equity curve itself. When someone shows you and equity curve like the one reported by this trader, rising in a straight line from the lower left to upper right quadrants, you can be 99% confident that you are dealing with a fake.
You see, in finance there are almost never any straight lines. They are as rare as unicorns. Especially when it comes to strategy performance. They only time you will EVER see an equity curve like this is when you are looking at the equity curve of (i) a high frequency market making trading system or (ii) a fake, produced by curve fitting a strategy to the ENTIRE data set.
And this strategy was not high frequency – as we shall see, it operated on 15 minute bars, holding positions overnight.
THE FOURTH BIG RED FLAG: GOD’s EQUITY CURVE
I said that straight line equity curve were extremely rare. In fact, even God’s equity curve isn’t often a straight line. What does that mean?
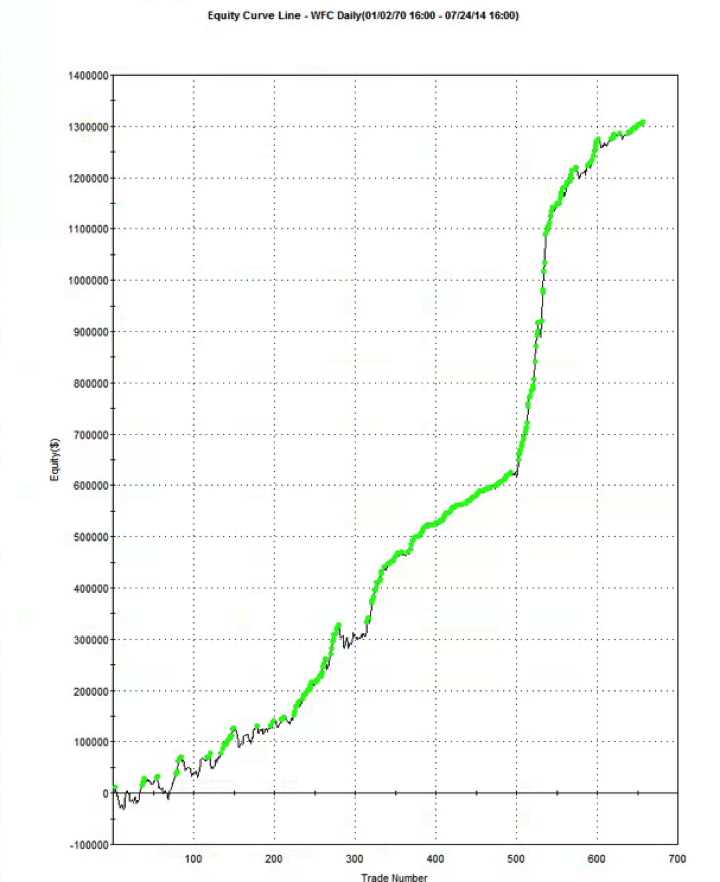
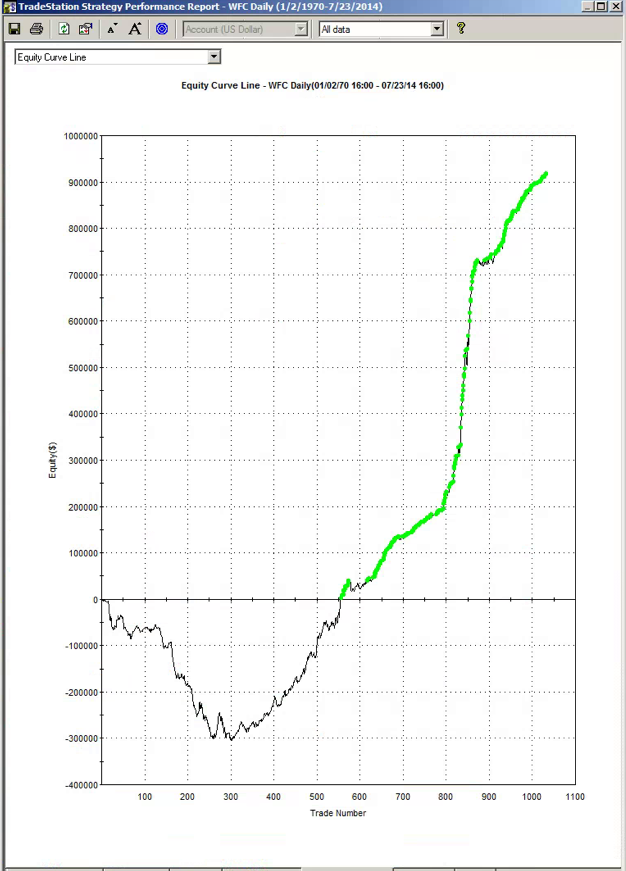
Suppose you had a strategy that could predict with 100% accuracy whether the market would go up or down over the next bar (whether you are using daily bars, or 15 minute bars, as in our example). The system would buy (or hold) when the market was forecast to rise, and sell when the market was predicted to fall. What would the performance of such a perfect system look like? Pretty stellar, obviously. And most people would guess that the system’s equity curve would be a straight line, or maybe even exponential in shape. In fact that’s typically not the case. God’s equity curve will be sloped and kinked, just like any other equity curve. And if your suspect’s equity curve is real, it should show some commonality with God’s equity curve, by which I mean it should show changes in slope and level that reflect those seen in the perfect equity curve.
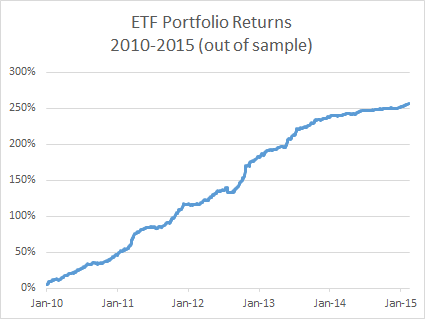
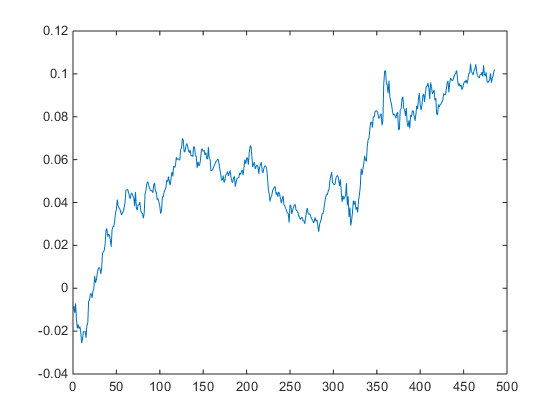
What does God’s Equity Curve look like in NG futures?
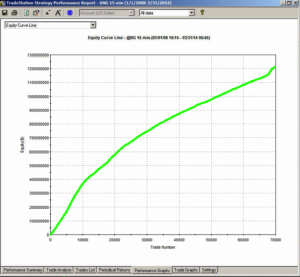
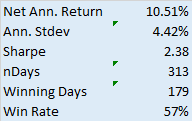
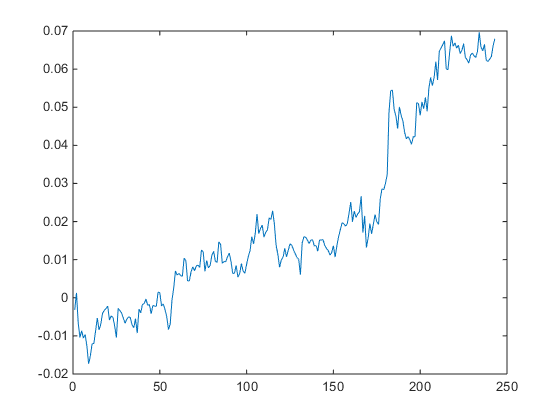
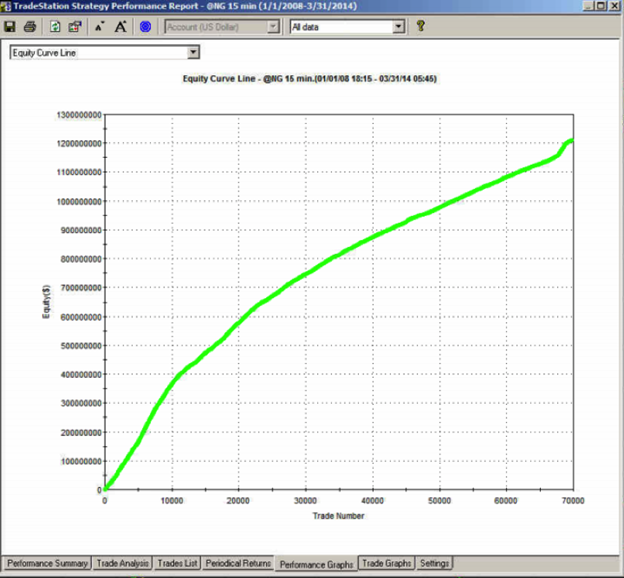
As you can see it’s not straight. In fact it’s concave. So a REAL equity curve should have similar characteristics, like this one, for example:
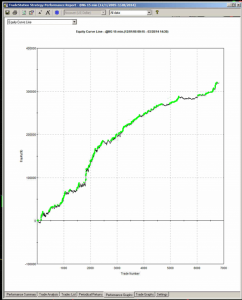
As you can see, the equity curve of the real trading system track’s God’s Equity Curve, albeit at a much lower level. It’s concave, with an upswing during the final few months of trading, just like God’s. That’s a good sign that the strategy back-test is very likely genuine (which it is – I produced it).
Why is Gods’ Equity Curve the shape it is? The answer will vary from market to market. In the case of NG, the suggestion is that the market is becoming more efficient: simple trading strategies based on technical indicators work less well than they did five years ago. We have seen something very similar in F/X markets. During the 1970’s and 1980’s when Soros was active in the field, simple strategies like moving average crossovers made great returns, but these entirely dissipated in the 1990’s, with the advent of widely available computing power.
THE FIFTH BIG RED FLAG: THE SHILL SHOUTDOWN
When I posted my analysis, which clearly indicated fakery by this well known forum participant, I was immediately flamed by one of his supporters who shouted something to the effect that (i) everyone knows that the downward slope of God’s Equity Curve was caused by volatility and (ii) the star trader, unlike God, or me, knows about position sizing.
This attempt at misdirection in the face of awkward facts is a classic sign of fakery. What distinguishes the shill post is:
(i) Immediacy – clearly no attempt has been made to evaluate the argument or analysis. The shill simply attempts to drown out the critic with a lot of noise, as quickly as possible.
(ii) Plausibility – shills will throw around terms that lend plausibility to their objection, but which after a moment’s reflection are entirely irrelevant or, as in this case, detrimental to their own cause.
(iii) Invective – the more intemperate the post, the more likely the shill is simply trying to provide cover for the faker.
So let’s take a moment to dispose of the plausible sounding objections posted by the shill in this example.
I am going to take it as read that everyone understands that trading profitability is positively correlated with volatility. There is a huge amount of empirical research supporting that finding, but to keep it simple we can appeal to one of the cornerstones of modern finance: risk and return. The higher the volatility, i.e. the greater the risk, the greater the return traders and investors in the markets will require on their capital. This is a principle of modern financial theory that even a graduate of the Scranton college of fine art should be expected to appreciate.
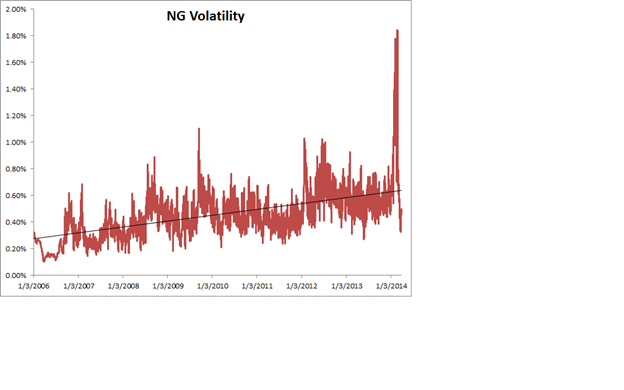
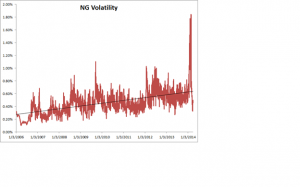
So what’s the story with NG volatility? You can see the time series of NG volatility in the chart below. One feature stands out above all others: the upward slope of the curve. NG volatility has RISEN over the sample period from 2008 to 2014. Consequently, returns from trading NG futures should also have RISEN rather than fallen. One thing we can say for sure, whatever caused the concave shape in God’s Equity Curve in NG futures, it was NOT volatility!
Turning to the shill’s next, plausible sounding, but dubious “explanation”, position sizing: this really is completely irrelevant. Because, as we shall see from an examination of the performance report, the track record was created by trading a constant one-lot! So this was just an attempt to sound “sophisticated” by someone trying to misdirect the reader away from the increasingly obvious evidence of fakery.
THE SIXTH BIG RED FLAG: LOW DRAWDOWNS AND OVERNIGHT GAP RISK
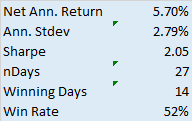
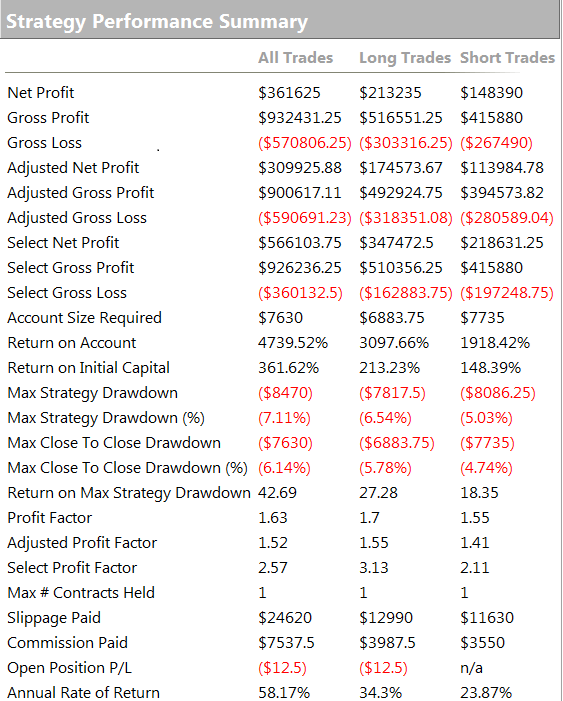
One of the highly unusual features of our faker’s equity curve is it’s exceptional smoothness. Low volatility in the equity curve is, in and of itself, an indicator the track record results from curve fitting. But we can get even more insight by digging into the performance report, shown below.
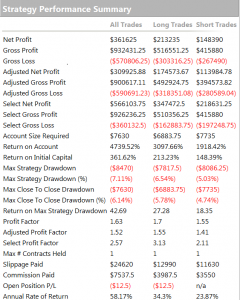
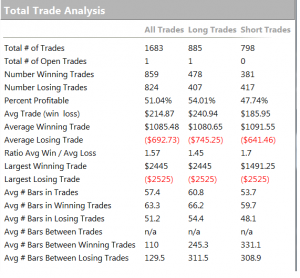
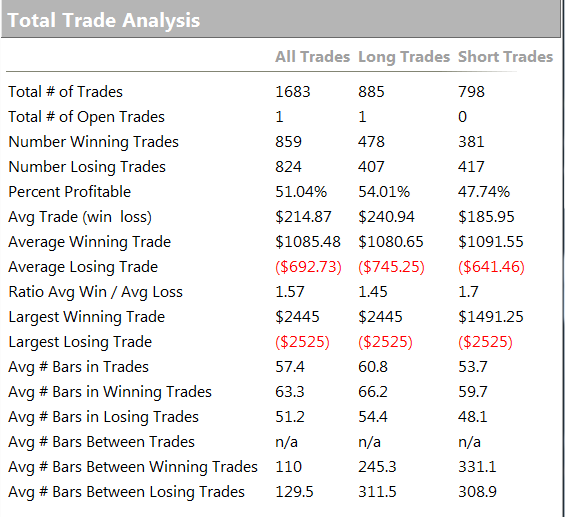
As you can see from the second page of the report, the strategy holds positions for an average of 57 15-minute bars, equivalent to slightly over 14 hours. So this is a low frequency strategy that takes overnight risk. Now, as any trader will know, overnight gap risk in a product like NG can be very significant and likely to be produce much larger drawdowns over a 5 year period than the $8,470 reported here.
The only other possible explanation is that the strategy is traded continuously through both day and night sessions. But this is not only itself improbable, it gives rise to another implausibility: liquidity in the overnight session is so poor that the strategy is unlikely to be able to trade more than 1-2 contracts, at most. This would be of little value to a CTA, or its customers, whatever the star trader’s protestations that his “clients are happy”.
There is no plausible way to resolve the disconnection between the low drawdown, overnight gap risk and market illiquidity. The most plausible explanation: the back-test is a curve fitting exercise.
THE SEVENTH AN FINAL BIG RED FLAG: INCONSISTENCY BETWEEN PERFORMANCE METRICS
As any experienced strategy developer knows, you can get some of the things you want, but you can never achieve all of them. Amongst the desirable features to be maximized are
• Profit factor
• Average PNL per contract
• Percentage win rate
There is a trade-off between the features. A high PNL per contract typically means you are trading less frequently, with longer hold periods, and consequently the percentage win rate tends to be lower. Alternatively, you can increase the win rate, at the cost of lowering the average PNL per contract and/or the profit factor. And so on.
This strategy purports to have it all: a high average PNL per contract resulting from low frequency trading, coupled with good percentage win rate of over 50% and profit factor. A win rate of much over 40% is highly unusual for a momentum strategy entering and exiting with market or stop orders – and its almost inconceivable for a strategy with a PNL per contract and profit factor as large as suggested here.
CONCLUSION
This back-test fails the sniff test on so many levels, I would rate the chance of it being real as less than 1 in 1000.
The final, conclusive proof of fakery is that the “star trader” responsible for producing the report was unable and/or unwilling to attempt to answer even a single one of the criticisms.
So, be warned. If you see forum members banding about track records like this one, you can be sure that they and their strategies are likely to be fake, and not to be trusted.