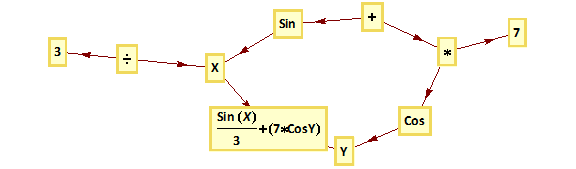
Trading Technologies’ ADL is a visual programming language designed specifically for trading strategy development that is integrated in the company’s flagship XTrader product. 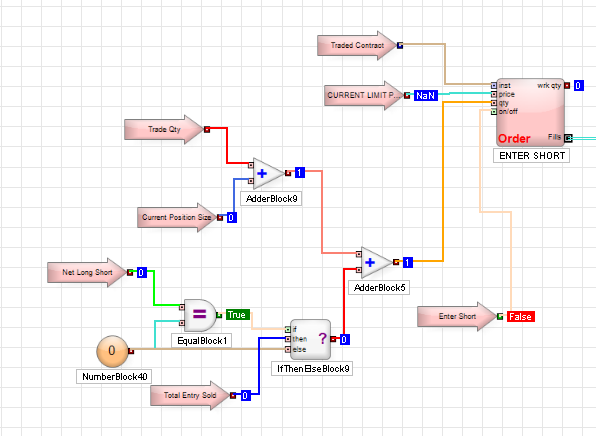 Despite the radically different programming philosophy, my experience of working with ADL has been delightfully easy and strategies that would typically take many months of coding in C++ have been up and running in a matter of days or weeks. An extract of one such strategy, a high frequency scalping trade in the E-Mini S&P 500 futures, is shown in the graphic above. The interface and visual language is so intuitive to a trading system developer that even someone who has never seen ADL before can quickly grasp at least some of what it happening in the code.
Despite the radically different programming philosophy, my experience of working with ADL has been delightfully easy and strategies that would typically take many months of coding in C++ have been up and running in a matter of days or weeks. An extract of one such strategy, a high frequency scalping trade in the E-Mini S&P 500 futures, is shown in the graphic above. The interface and visual language is so intuitive to a trading system developer that even someone who has never seen ADL before can quickly grasp at least some of what it happening in the code.
Strategy Development in Low vs. High-Level Languages
What are the benefits of using a high level language like ADL compared to programming languages like C++/C# or Java that are traditionally used for trading system development? The chief advantage is speed of development: I would say that ADL offers the potential up the development process by at least one order of magnitude. A complex trading system would otherwise take months or even years to code and test in C++ or Java, can be implemented successfully and put into production in a matter of weeks in ADL. In this regard, the advantage of speed of development is one shared by many high level languages, including, for example, Matlab, R and Mathematica. But in ADL’s case the advantage in terms of time to implementation is aided by the fact that, unlike generalist tools such as MatLab, etc, ADL is designed specifically for trading system development. The ADL development environment comes equipped with compiled pre-built blocks designed to accomplish many of the common tasks associated with any trading system such as acquiring market data and handling orders. Even complex spread trades can be developed extremely quickly due to the very comprehensive library of pre-built blocks.

Integrating Research and Development
One of the drawbacks of using a higher level language for building trading systems is that, being interpreted rather than compiled, they are simply too slow – one or more orders of magnitude, typically – to be suitable for high frequency trading. I will come on to discuss the execution speed issue a little later. For now, let me bring up a second major advantage of ADL relative to other high level languages, as I see it. One of the issues that plagues trading system development is the difficulty of communication between researchers, who understand financial markets well, but systems architecture and design rather less so, and developers, whose skill set lies in design and programming, but whose knowledge of markets can often be sketchy. These difficulties are heightened where researchers might be using a high level language and relying on developers to re-code their prototype system to get it into production. Developers typically (and understandably) demand a high degree of specificity about the requirement and if it’s not included in the spec it won’t be in the final deliverable. Unfortunately, developing a successful trading system is a highly non-linear process and a researcher will typically have to iterate around the core idea repeatedly until they find a combination of alpha signal and entry/exit logic that works. In other words, researchers need flexibility, whereas developers require specificity. ADL helps address this issue by providing a development environment that is at once highly flexible and at the same time powerful enough to meet the demands of high frequency trading in a production environment. It means that, in theory, researchers and developers can speak a common language and use a common tool throughout the R&D development cycle. This is likely to reduce the kind of misunderstanding between researchers and developers that commonly arise (often setting back the implementation schedule significantly when they do).
Latency
Of course, at least some of the theoretical benefit of using ADL depends on execution speed. The way the problem is typically addressed with systems developed in high level languages like Matlab or R is to recode the entire system in something like C++, or to recode some of the most critical elements and plug those back into the main Matlab program as dlls. The latter approach works, and preserves the most important benefits of working in both high and low level languages, but the resulting system is likely to be sub-optimal and can be difficult to maintain. The approach taken by Trading Technologies with ADL is very different. Firstly, the component blocks are written in C# and in compiled form should run about as fast as native code. Secondly, systems written in ADL can be deployed immediately on a co-located algo server that is plugged directly into the exchange, thereby reducing latency to an acceptable level. While this is unlikely to sufficient for an ultra-high frequency system operating on the sub-millisecond level, it will probably suffice for high frequency systems that operate at speeds above above a few millisecs, trading up to say, around 100 times a day.
Fill Rate and Toxic Flow
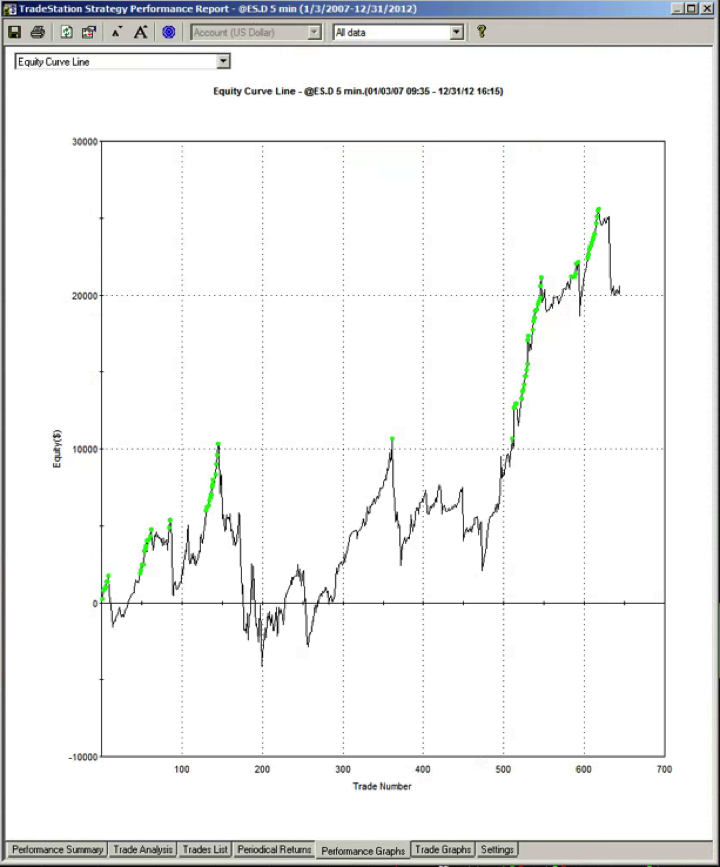
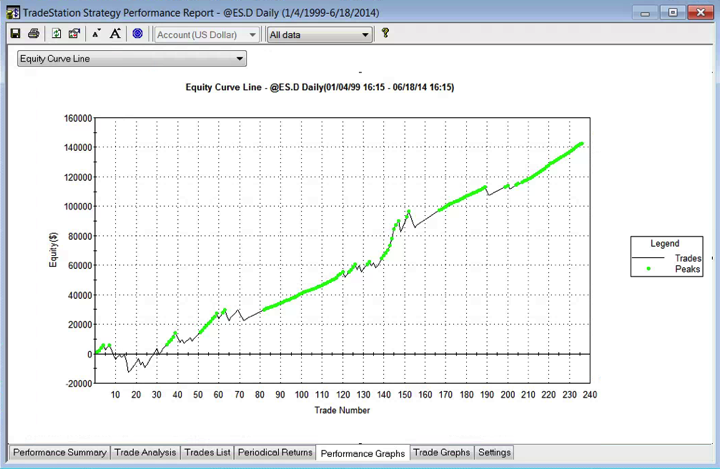
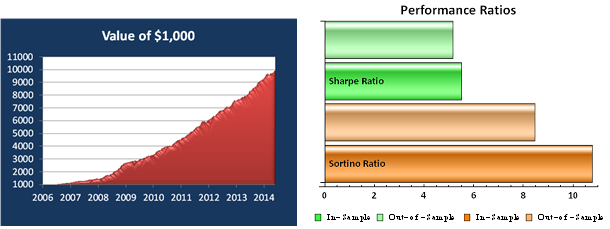
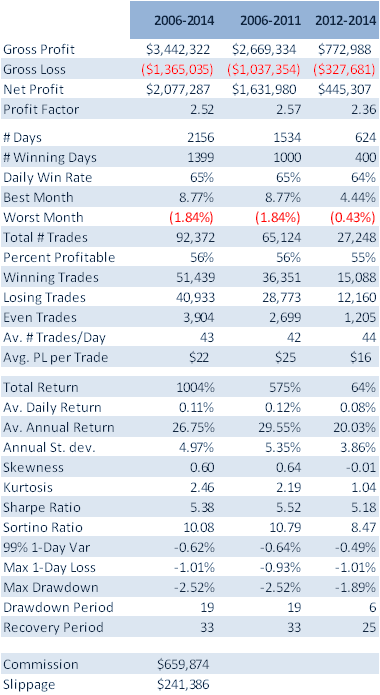
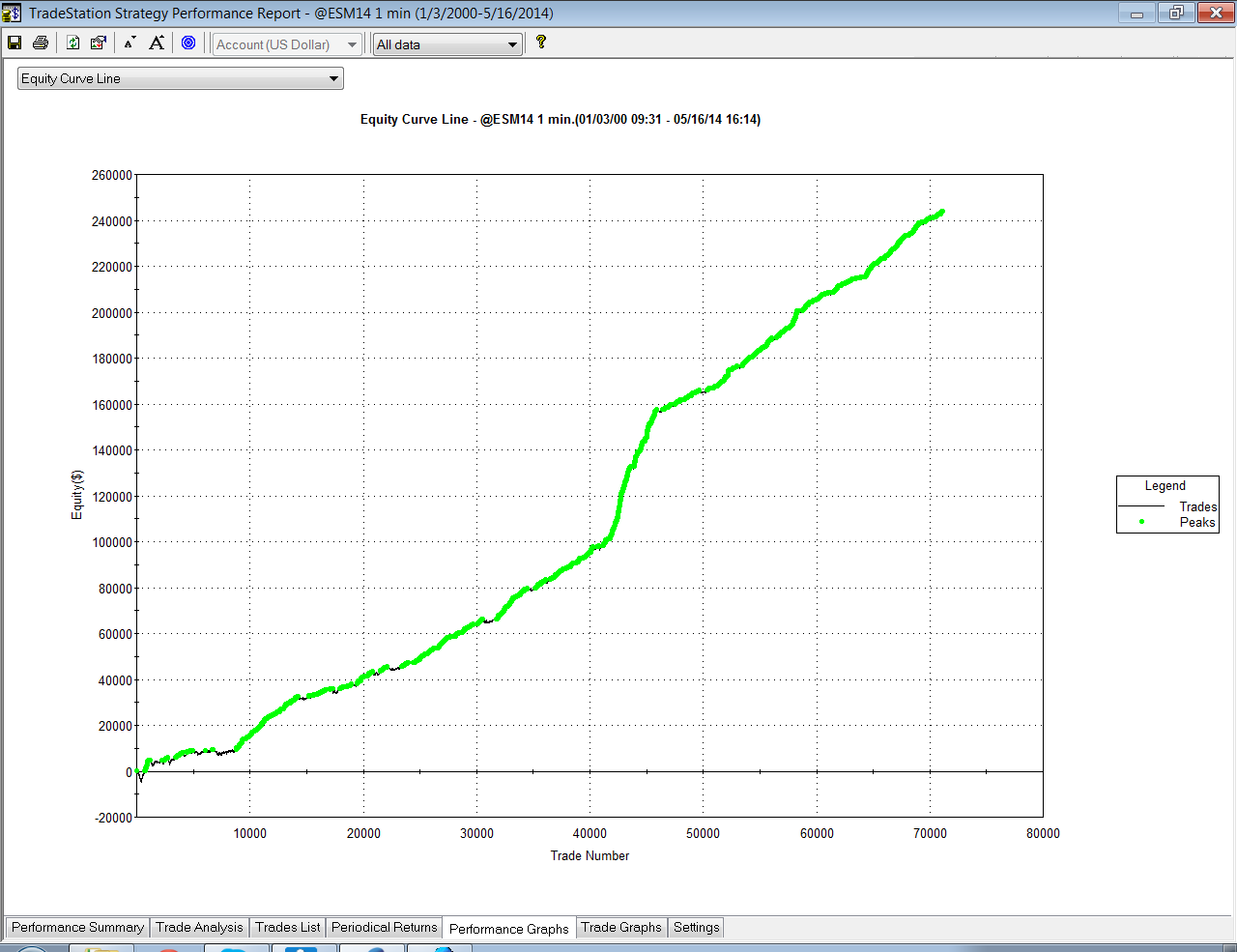
For those not familiar with the HFT territory, let me provide an example of why the issues of execution speed and latency are so important. Below is a simulated performance record for a HFT system in ES futures. The system is designed to enter and exit using limit orders and trades around 120 times a day, with over 98% profitability, if we assume a 100% fill rate. 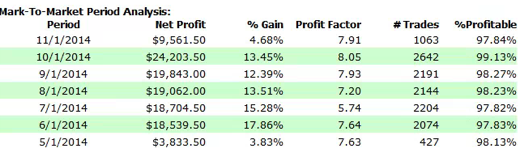
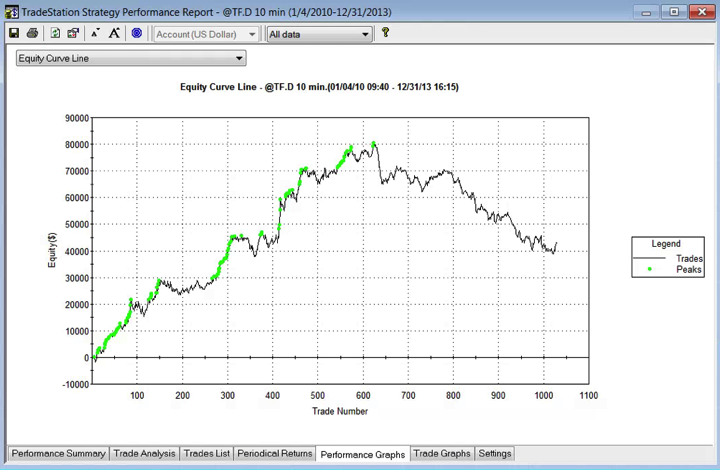
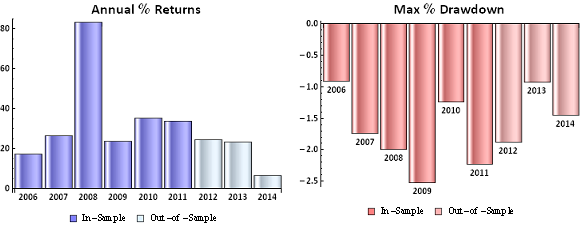
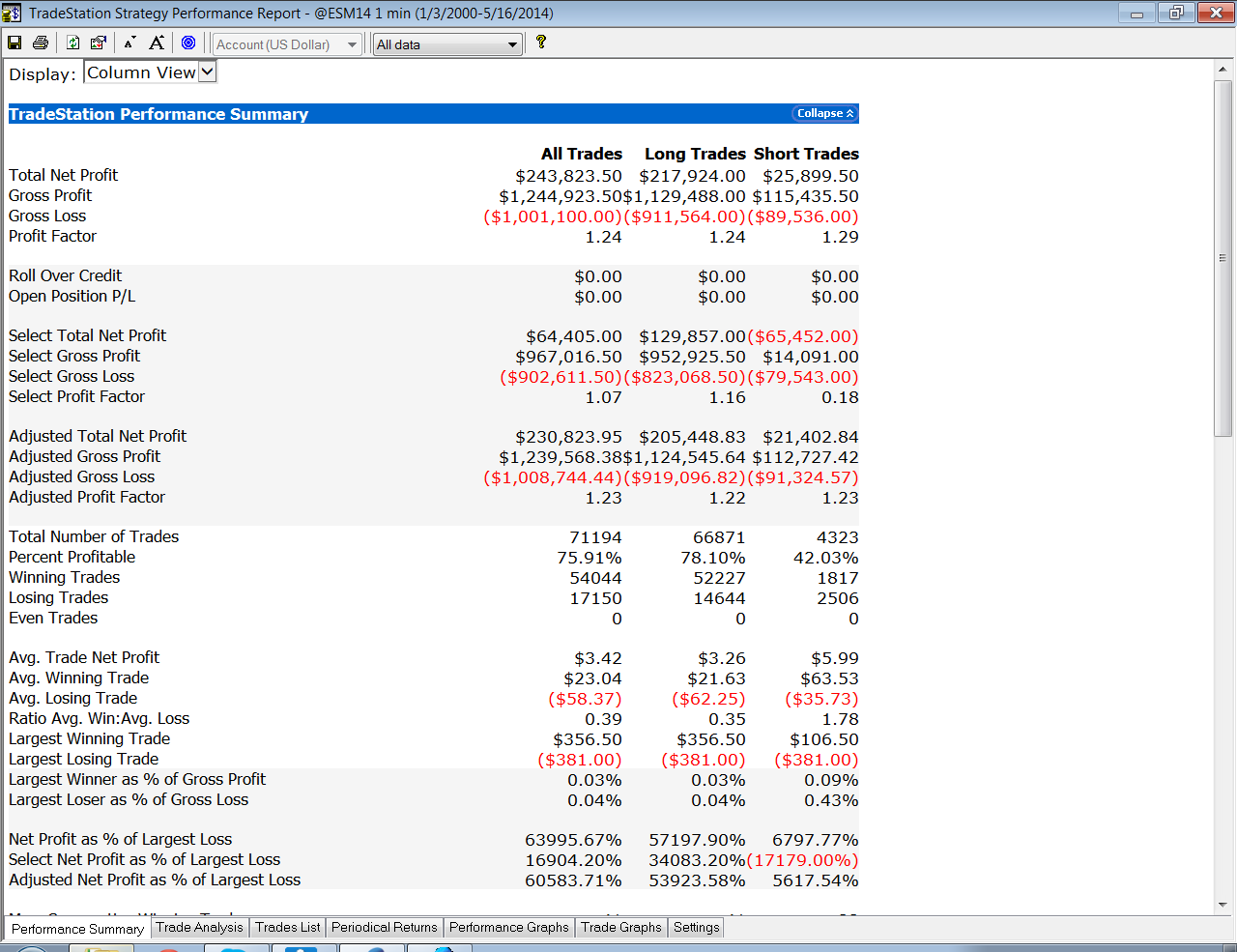
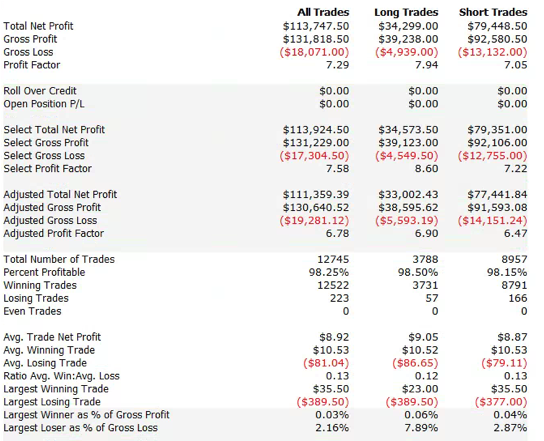 So far so good. But a 100% fill rate is clearly unrealistic. Let’s look at a pessimistic scenario: what if we got filled on orders only when the limit price was exceeded? (For those familiar with the jargon, we are assuming a high level of flow toxicity) The outcome is rather different:
So far so good. But a 100% fill rate is clearly unrealistic. Let’s look at a pessimistic scenario: what if we got filled on orders only when the limit price was exceeded? (For those familiar with the jargon, we are assuming a high level of flow toxicity) The outcome is rather different: 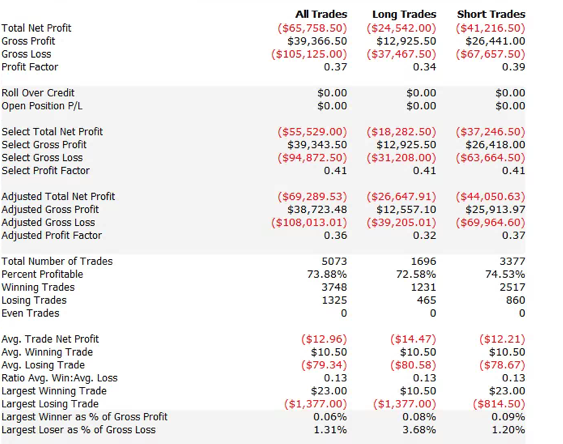 Neither scenario is particularly realistic, but the outcome is much more likely to be closer to the second scenario rather than the first if we our execution speed is slow, or if we are using a retail platform such as Interactive Brokers or Tradestation, with long latency wait times. The reason is simple: our orders will always arrive late and join the limit order book at the back of the queue. In most cases the orders ahead of ours will exhaust demand at the specified limit price and the market will trade away without filling our order. At other times the market will fill our order whenever there is a large flow against us (i.e. a surge of sell orders into our limit buy), i.e. when there is significant toxic flow. The proposition is that, using ADL and the its high-speed trading infrastructure, we can hope to avoid the latter outcome. While we will never come close to achieving a 100% fill rate, we may come close enough to offset the inevitable losses from toxic flow and produce a decent return. Whether ADL is capable of fulfilling that potential remains to be seen.
Neither scenario is particularly realistic, but the outcome is much more likely to be closer to the second scenario rather than the first if we our execution speed is slow, or if we are using a retail platform such as Interactive Brokers or Tradestation, with long latency wait times. The reason is simple: our orders will always arrive late and join the limit order book at the back of the queue. In most cases the orders ahead of ours will exhaust demand at the specified limit price and the market will trade away without filling our order. At other times the market will fill our order whenever there is a large flow against us (i.e. a surge of sell orders into our limit buy), i.e. when there is significant toxic flow. The proposition is that, using ADL and the its high-speed trading infrastructure, we can hope to avoid the latter outcome. While we will never come close to achieving a 100% fill rate, we may come close enough to offset the inevitable losses from toxic flow and produce a decent return. Whether ADL is capable of fulfilling that potential remains to be seen.
More on ADL
For more information on ADL go here.