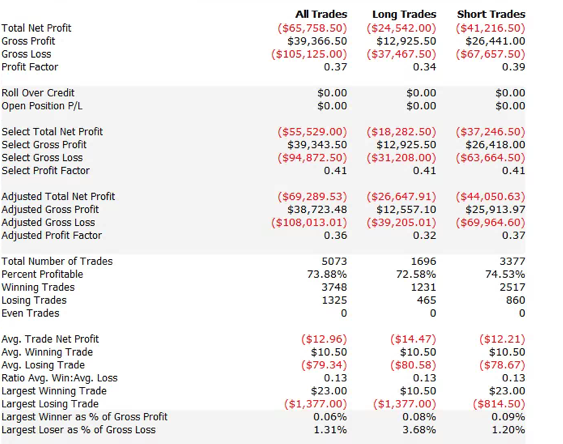
Move over C++: Modern Programming Languages Combine Productivity and Efficiency
Like many in the field of quantitative research, I have programmed in several different languages over the years: Assembler, Fortran, Algol, Pascal, APL, VB, C, C++, C#, Matlab, R, Mathematica. There is an even longer list of languages I have never bothered with: Cobol, Java, Python, to name but three.
In general, the differences between many of these are much fewer than their similarities: they reserve memory; they have operators; they loop. Several have ghastly syntax requiring random punctuation that supposedly makes the code more intelligible, but in practice does precisely the opposite. Some, like Objective C, are so ugly and poorly designed they should have been strangled at birth. The ubiquity of C is due, not to its elegance, but to the fact that it was one of the first languages distributed for free to impecunious students. The greatest benefit of most languages is that they compile to machine code that executes quickly. But the task of coding in them is often an unpleasant, inefficient process that typically involves reinvention of the wheel multiple times over and massive amounts of tedious debugging. Who, after all, doesn’t enjoy unintelligible error messages like “parsec error in dynamic memory heap allocator” – when the alternative, comprehensible version would be so prosaic: “in line 51 you missed one of those curly brackets we insist on for no good reason”.
There have been relatively few steps forward that actually have had any real significance. Most times, the software industry operates rather like the motor industry: while the consumer pines for, say, a new kind of motor that will do 1,000 miles to the gallon without looking like an electric golf cart, manufacturers announce, to enormous fanfare, trivia like heated wing mirrors.

The first language I came across that seemed like a material advance was APL, a matrix-based language that offers lots of built-in functionality, very much like MatLab. Achieving useful end-results in a matter of days or weeks, rather than months, remains one of the great benefits of such high-level languages. Unfortunately, like all high-level languages that are weakly typed, APL, MatLab, R, etc, are interpreted rather than compiled. And so I learned about the perennial trade-off that has plagued systems development over the last 30 years: programming productivity vs. execution efficiency. The great divide between high level, interpreted languages and lower-level, compiled languages, would remain forever, programming language experts assured us, because of the lack of type-specificity in the former.
High-level language designers did what they could, offering ever-larger collections of sophisticated, built-in operators and libraries that use efficient machine-code instructions, as well as features such as parallel processing, to speed up execution. But, while it is now feasible to develop smaller applications in a few lines of Matlab or Mathematica that have perfectly acceptable performance characteristics, major applications (trading platforms, for example) seemed ordained to languish forever in the province of languages whose chief characteristic appears to be the lack of intelligibility of their syntax.
I was always suspicious of this thesis. It seemed to me that it should not be beyond the wit of man to design a programming language that offers straightforward, type-agnostic syntax that can be compiled. And lo: this now appears to have come true.
Of the multitude of examples that will no doubt be offered up over the next several years I want to mention two – not because I believe them to be the “final word” on this important topic, but simply as exemplars of what is now possible, as well as harbingers of what is to come.
Trading Technologies ADL
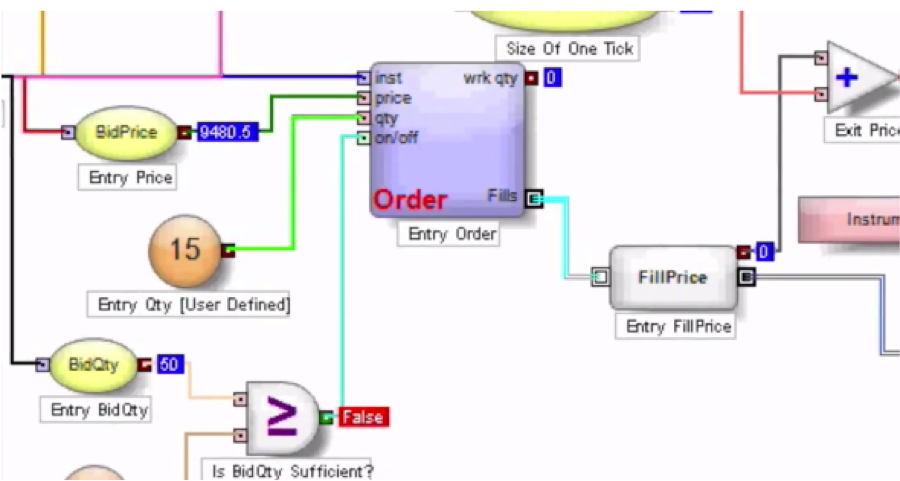
The first, Trading Technologies’ ADL, I have written about at length already. In essence, ADL is a visual programming language focused on trading system development. ADL allows the programmer to deploy highly-efficient, pre-built code blocks as icons that are dragged and dropped onto a programming canvass and assembled together using logic connections represented by lines drawn on the canvass. From my experience, ADL outpaces any other high-level development tool by at least an order of magnitude, but without sacrificing (much) efficiency in execution, firstly because the code blocks are written in native C#, and secondly, because completed systems are deployed on an algo server with a sub-millisecond connectivity to the exchange.

The second example is a language called Julia, which you can find out more about here. To quote from the web site:
“Julia is a high-level, high-performance dynamic programming language for technical computing. Julia features optional typing, multiple dispatch, and good performance, achieved using type inference and just-in-time (JIT) compilation, implemented using LLVM”
The language syntax is indeed very straightforward and logical. As to performance, the evidence appears to be that it is possible to achieve execution speeds that match or even exceed those achieved by languages like Java or C++.
How High Level Programming Languages Match Up
The following micro-benchmark results, provided on the Julia web site, were obtained on a single core (serial execution) on an Intel® Xeon® CPU E7-8850 2.00GHz CPU with 1TB of 1067MHz DDR3 RAM, running Linux:
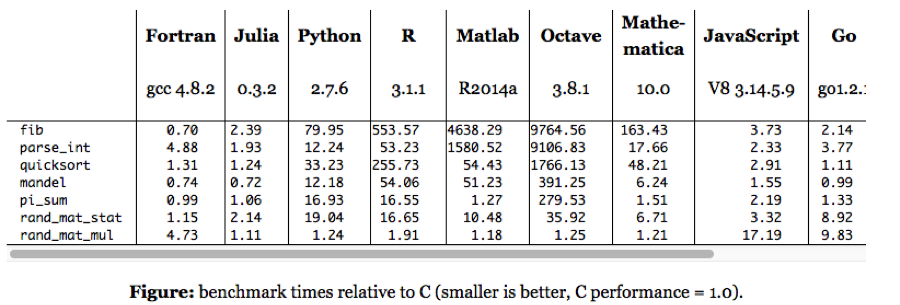
We need not pretend that this represents any kind of comprehensive speed test of Julia or its competitors. Still, it’s worth dwelling on a few of the salient results. The first thing that strikes me is how efficient Fortran, the grand-daddy of programming languages, remains in comparison to more modern alternatives, including the C benchmark. The second result I find striking is how slow the much-touted Python is compared to Julia, Go and C. The third result is how poorly MatLab, Octave and R perform on several of the tests. Finally, and in some ways the greatest surprise at all is the execution efficiency of Mathematica relative to other high-level languages like MatLab and R. It appears that Wolfram has made enormous progress in improving the speed of Mathematica, presumably through the vast expansion of highly efficient built-in operators and functions that have been added in recent releases (see chart below).
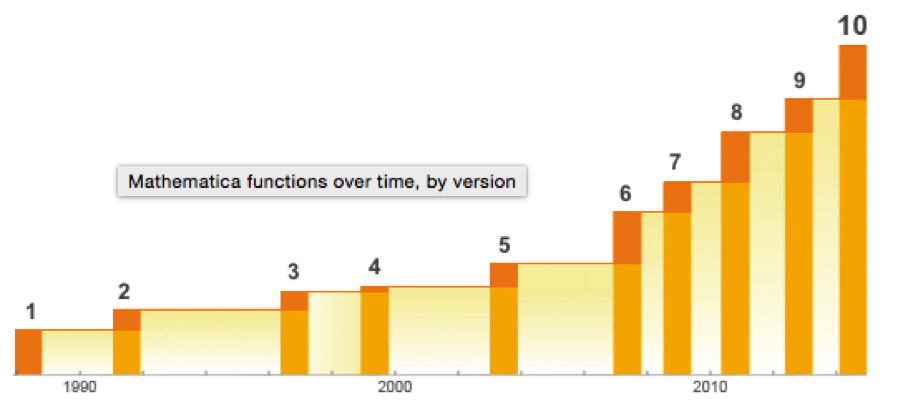
Source: Wolfram
Mathematica even compares favorably to Python on several of the tests. Given that, why would anyone spend time learning a language like Python, which offers neither the development advantages of Mathematica, nor the speed advantages of C (or Fortran, Java or Julia)?
In any event, the main point is this: it appears that, in 2015, we can finally look forward to dispensing with legacy programing languages and their primitive syntax and instead develop large, scalable systems that combine programming productivity and execution efficiency. And that is reason enough for any self-respecting quant to rejoice.
My best wishes to you all for the New Year.