One of the frustrating aspects of research and development of trading systems is that there is never enough time to investigate all of the interesting trading ideas one would like to explore. In the early 1970’s, when a moving average crossover system was considered state of the art, it was relatively easy to develop profitable strategies using simple technical indicators. Indeed, research has shown that the profitability of simple trading rules persisted in foreign exchange and other markets for a period of decades. But, coincident with the advent of the PC in the late 1980’s, such simple strategies began to fail. The widespread availability of data, analytical tools and computing power has, arguably, contributed to the increased efficiency of financial markets and complicated the search for profitable trading ideas. We are now at a stage where is can take a team of 5-6 researchers/developers, using advanced research techniques and computing technologies, as long as 12-18 months, and hundreds of thousands of dollars, to develop a prototype strategy. And there is no guarantee that the end result will produce the required investment returns.
The lengthening lead times and rising cost and risk of strategy research has obliged trading firms to explore possibilities for accelerating the R&D process. One such approach is Genetic Programming.
Early Experiences with Genetic Programming
I first came across the GP approach to investment strategy in the late 1990s, when I began to work with Haftan Eckholdt, then head of neuroscience at Yeshiva University in New York. Haftan had proposed creating trading strategies by applying the kind of techniques widely used to analyze voluminous and highly complex data sets in genetic research. I was extremely skeptical of the idea and spent the next 18 months kicking the tires very hard indeed, of behalf of an interested investor. Although Haftan’s results seemed promising, I was fairly sure that they were the product of random chance and set about devising tests that would demonstrate that.

One of the challenges I devised was to create data sets in which real and synthetic stock series were mixed together and given to the system evaluate. To the human eye (or analyst’s spreadsheet), the synthetic series were indistinguishable from the real thing. But, in fact, I had “planted” some patterns within the processes of the synthetic stocks that made them perform differently from their real-life counterparts. Some of the patterns I created were quite simple, such as introducing a drift component. But other patterns were more nuanced, for example, using a fractal Brownian motion generator to induce long memory in the stock volatility process.
It was when I saw the system detect and exploit the patterns buried deep within the synthetic series to create sensible, profitable strategies that I began to pay attention. A short time thereafter Haftan and I joined forces to create what became the Proteom Fund.
That Proteom succeeded at all was a testament not only to Haftan’s ingenuity as a researcher, but also to his abilities as a programmer and technician. Processing such large volumes of data was a tremendous challenge at that time and required a cluster of 50 cpu’s networked together and maintained with a fair amount of patch cable and glue. We housed the cluster in a rat-infested warehouse in Brooklyn that had a very pleasant view of Manhattan, but no a/c. The heat thrown off from the cluster was immense, and when combined with very loud rap music blasted through the walls by the neighboring music studios, the effect was debilitating. As you might imagine, meetings with investors were a highly unpredictable experience. Fortunately, Haftan’s intellect was matched by his immense reserves of fortitude and patience and we were able to attract investments from several leading institutional investors.
The Genetic Programming Approach to Building Trading Models
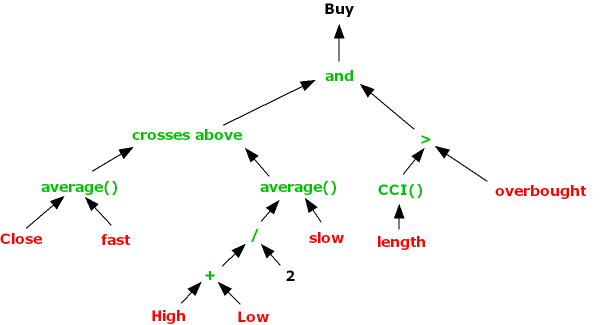
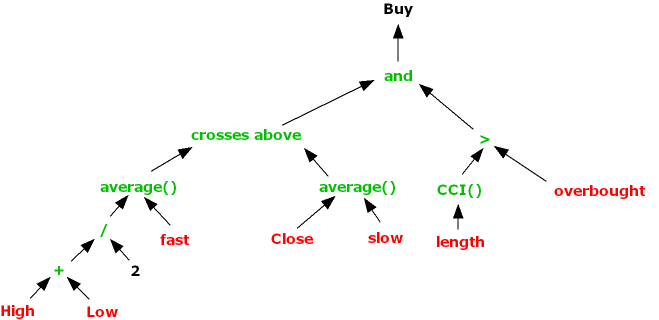
Genetic programming is an evolutionary-based algorithmic methodology which can be used in a very general way to identify patterns or rules within data structures. The GP system is given a set of instructions (typically simple operators like addition and subtraction), some data observations and a fitness function to assess how well the system is able to combine the functions and data to achieve a specified goal.
In the trading strategy context the data observations might include not only price data, but also price volatility, moving averages and a variety of other technical indicators. The fitness function could be something as simple as net profit, but might represent alternative measures of profitability or risk, with factors such as PL per trade, win rate, or maximum drawdown. In order to reduce the danger of over-fitting, it is customary to limit the types of functions that the system can use to simple operators (+,-,/,*), exponents, and trig functions. The length of the program might also be constrained in terms of the maximum permitted lines of code.
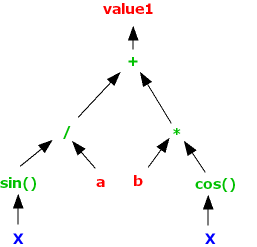
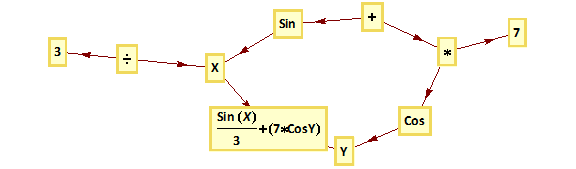
We can represent what is going on using a tree graph:
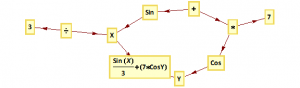
In this example the GP system is combining several simple operators with the Sin and Cos trig functions to create a signal comprising an expression in two variables, X and Y, which may be, for example, stock prices, moving averages, or technical indicators of momentum or mean reversion.
The “evolutionary” aspect of the GP process derives from the idea that an existing signal or model can be mutated by replacing nodes in a branch of a tree, or even an entire branch by another. System performance is re-evaluated using the fitness function and the most profitable mutations are retained for further generation.
The resulting models are often highly non-linear and can be very general in form.
A GP Daytrading Strategy
The last fifteen years has seen tremendous advances in the field of genetic programming, in terms of the theory as well as practice. Using a single hyper-threaded CPU, it is now possible for a GP system to generate signals at a far faster rate than was possible on Proteom’s cluster of 50 networked CPUs. A researcher can develop and evaluate tens of millions of possible trading algorithms with the space of a few hours. Implementing a thoroughly researched and tested strategy is now feasible in a matter of weeks. There can be no doubt of GP’s potential to produce dramatic reductions in R&D lead times and costs. But does it work?
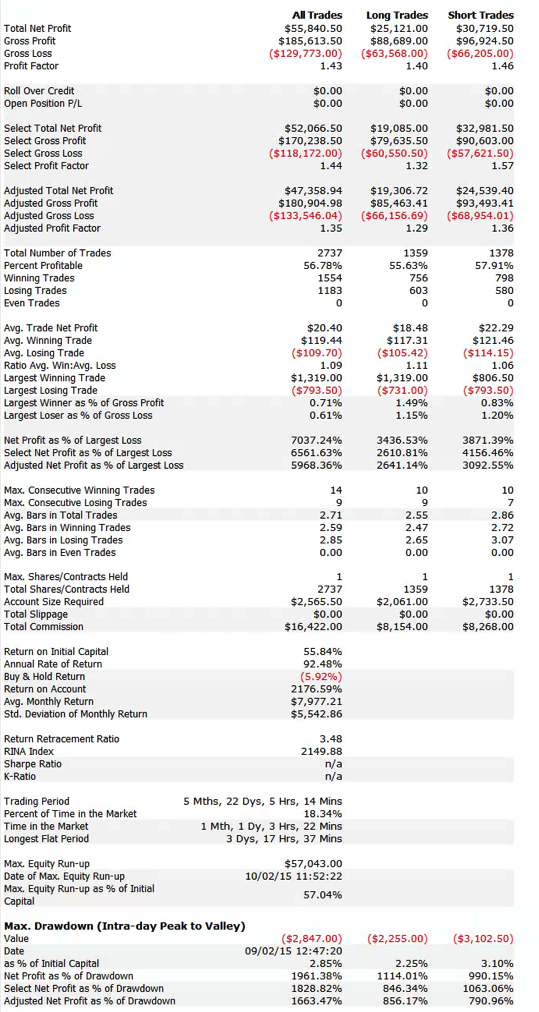
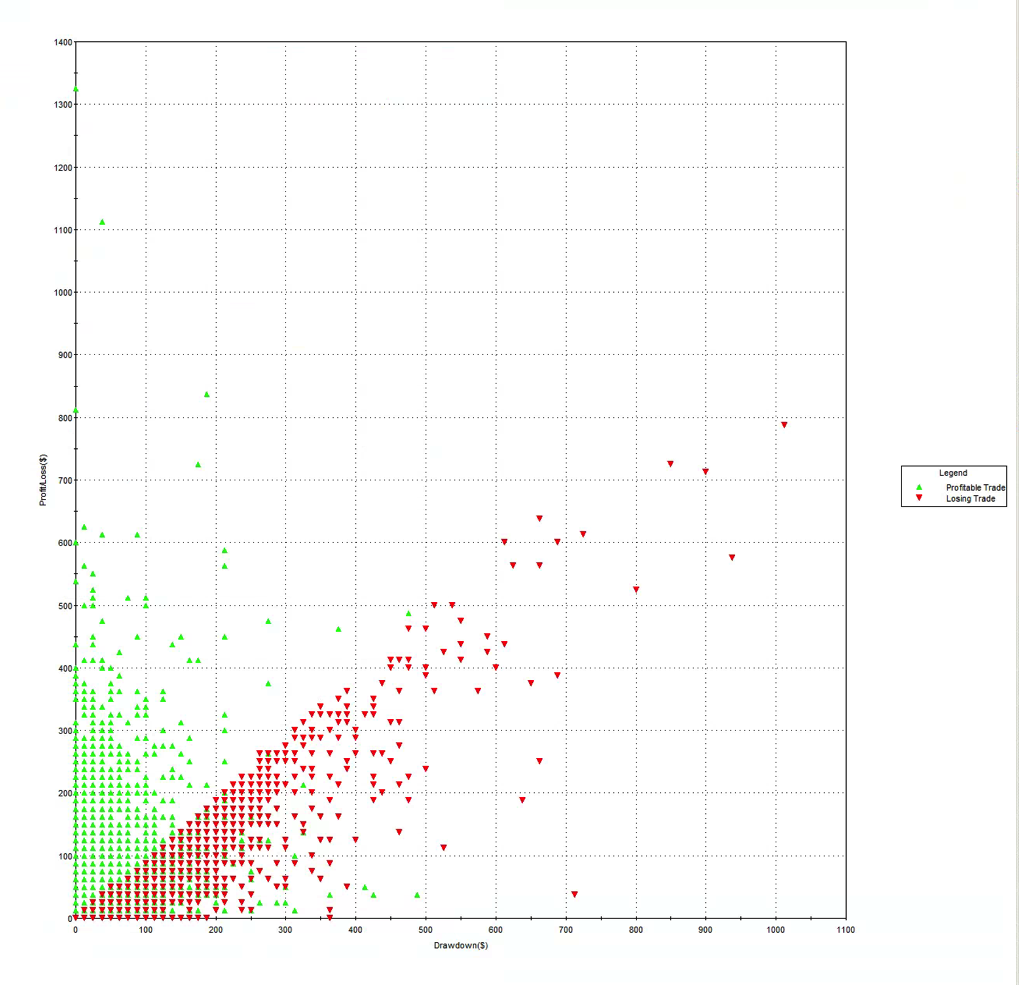
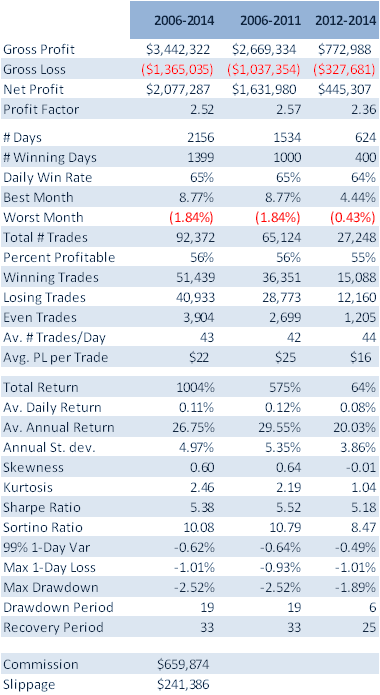
To address that question I have summarized below the performance results from a GP-developed daytrading system that trades nine different futures markets: Crude Oil (CL), Euro (EC), E-Mini (ES), Gold (GC), Heating Oil (HO), Coffee (KC), Natural gas (NG), Ten Year Notes (TY) and Bonds (US). The system trades a single contract in each market individually, going long and short several times a day. Only the most liquid period in each market is traded, which typically coincides with the open-outcry session, with any open positions being exited at the end of the session using market orders. With the exception of the NG and HO markets, which are entered using stop orders, all of the markets are entered and exited using standard limit orders, at prices determined by the system
The system was constructed using 15-minute bar data from Jan 2006 to Dec 2011 and tested out-of-sample of data from Jan 2012 to May 2014. The in-sample span of data was chosen to cover periods of extreme market stress, as well as less volatile market conditions. A lengthy out-of-sample period, almost half the span of the in-sample period, was chosen in order to evaluate the robustness of the system.
Out-of-sample testing was “double-blind”, meaning that the data was not used in the construction of the models, nor was out-of-sample performance evaluated by the system before any model was selected.
Performance results are net of trading commissions of $6 per round turn and, in the case of HO and NG, additional slippage of 2 ticks per round turn.
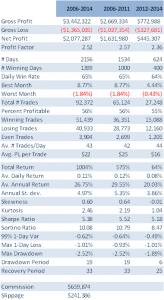
(click on the table for a higher definition view)
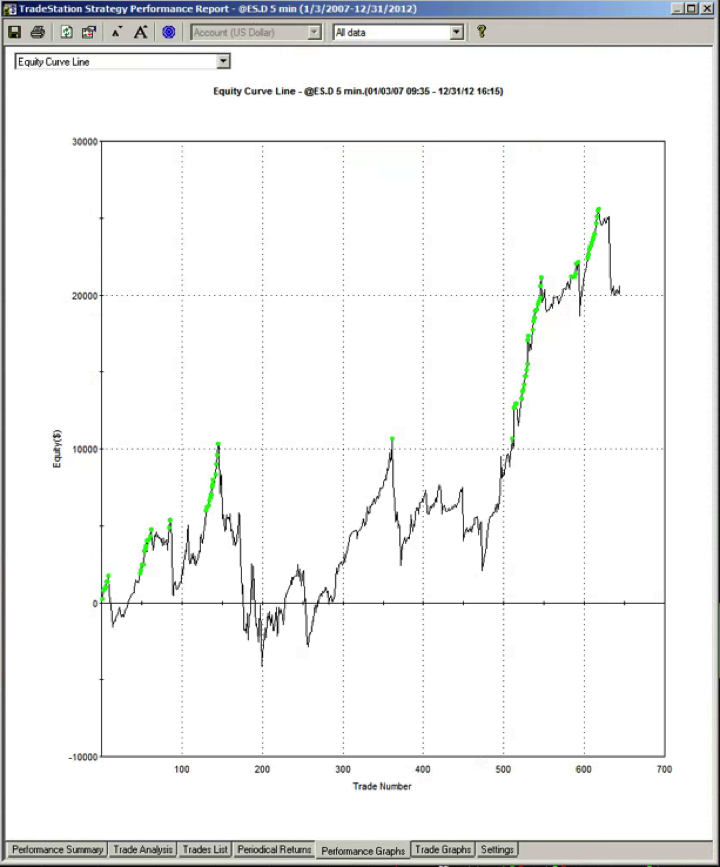
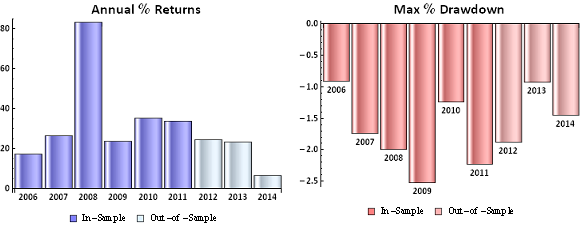
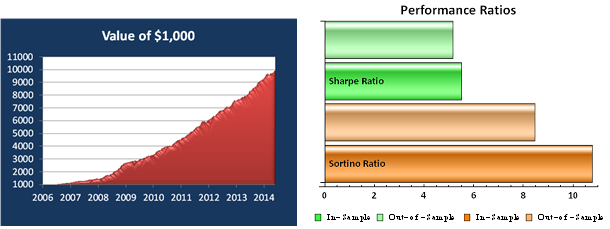
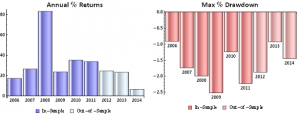
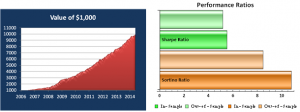
The most striking feature of the strategy is the high rate of risk-adjusted returns, as measured by the Sharpe ratio, which exceeds 5 in both in-sample and out-of-sample periods. This consistency is a reflection of the fact that, while net returns fall from an annual average of over 29% in sample to around 20% in the period from 2012, so, too, does the strategy volatility decline from 5.35% to 3.86% in the respective periods. The reduction in risk in the out-of-sample period is also reflected in lower Value-at-Risk and Drawdown levels.
A decline in the average PL per trade from $25 to $16 in offset to some degree by a slight increase in the rate of trading, from 42 to 44 trades per day, on average, while daily win rate and percentage profitable trades remain consistent at around 65% and 56%, respectively.
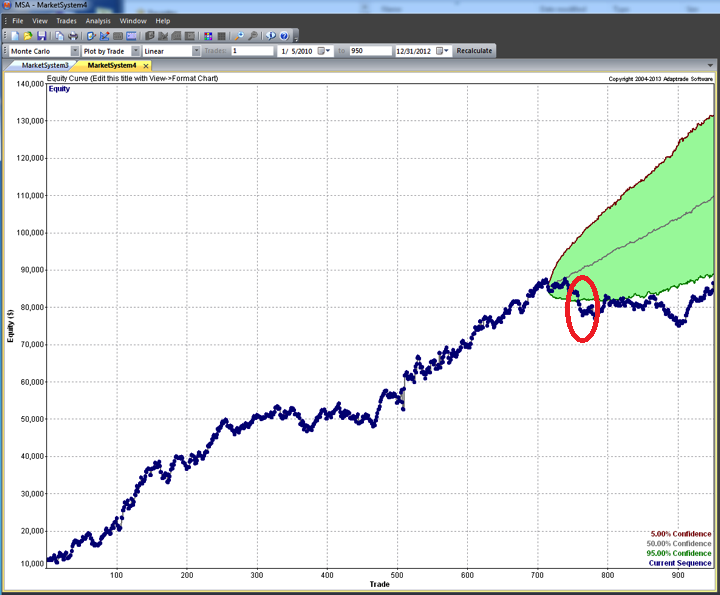
Overall, the system appears to be not only highly profitable, but also extremely robust. This is impressive, given that the models were not updated with data after 2011, remaining static over a period almost half as long as the span of data used in their construction. It is reasonable to expect that out-of-sample performance might be improved by allowing the models to be updated with more recent data.
Benefits and Risks of the GP Approach to Trading System Development
The potential benefits of the GP approach to trading system development include speed of development, flexibility of design, generality of application across markets and rapid testing and deployment.
What about the downside? The most obvious concern is the risk of over-fitting. By allowing the system to develop and test millions of models, there is a distinct risk that the resulting systems may be too closely conditioned on the in-sample data, and will fail to maintain performance when faced with new market conditions. That is why, of course, we retain a substantial span of out-of-sample data, in order to evaluate the robustness of the trading system. Even so, given the enormous number of models evaluated, there remains a significant risk of over-fitting.
Another drawback is that, due to the nature of the modelling process, it can be very difficult to understand, or explain to potential investors, the “market hypothesis” underpinning any specific model. “We tested it and it works” is not a particularly enlightening explanation for investors, who are accustomed to being presented with a more articulate theoretical framework, or investment thesis. Not being able to explain precisely how a system makes money is troubling enough in good times; but in bad times, during an extended drawdown, investors are likely to become agitated very quickly indeed if no explanation is forthcoming. Unfortunately, evaluating the question of whether a period of poor performance is temporary, or the result of a breakdown in the model, can be a complicated process.
Finally, in comparison with other modeling techniques, GP models suffer from an inability to easily update the model parameters based on new data as it become available. Typically, as GP model will be to rebuilt from scratch, often producing very different results each time.
Conclusion
Despite the many limitations of the GP approach, the advantages in terms of the speed and cost of researching and developing original trading signals and strategies have become increasingly compelling.
Given the several well-documented successes of the GP approach in fields as diverse as genetics and physics, I think an appropriate position to take with respect to applications within financial market research would be one of cautious optimism.




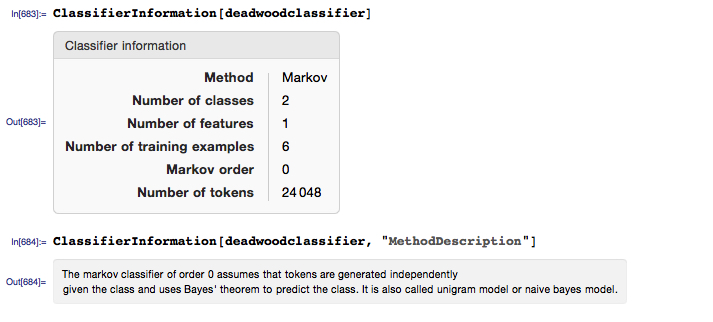
 For testing purposes, let’s download a sample of classic works by other authors:
For testing purposes, let’s download a sample of classic works by other authors: