In this quantitative analysis I explore how, starting from the assumption of a stable, Gaussian distribution in a returns process, we evolve to a system that displays all the characteristics of empirical market data, notably time-dependent moments, high levels of kurtosis and fat tails. As it turns out, the only additional assumption one needs to make is that the market is periodically disturbed by the random arrival of news.
NOTE: if you are unable to see the Mathematica models below, you can download the free Wolfram CDF player and you may also need this plug-in.
You can also download the complete Mathematica CDF file here.
Stationarity
A stationary process is one that evolves over time, but whose probability distribution does not vary with time. As the word implies, such a process is stable. More formally, the moments of the distribution are independent of time.
Let’s assume we are dealing with such a process that have constant mean μ and constant volatility (standard deviation) σ.
Φ=NormalDistribution[μ,σ]
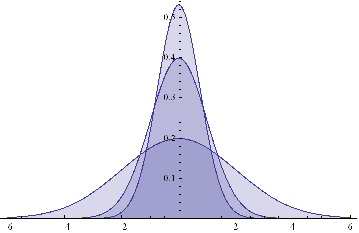
Here are some examples of Normal probability distributions, with constant mean μ = 0 and standard deviation σ ranging from 0.75 to 2
Plot[Evaluate@Table[PDF[Φ,x],{σ,{.75,1,2}}]/.μ→0,{x,-6,6},Filling→Axis]
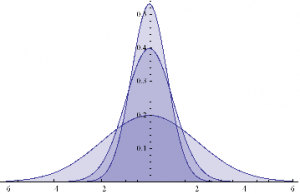
The moments of Φ are given by:
Through[{Mean, StandardDeviation, Skewness, Kurtosis}[Φ]]
{μ, σ, 0, 3}
They, too, are time – independent.
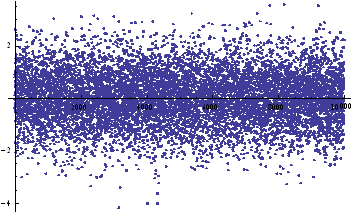
We can simulate some observations from such a process, with, say, mean μ = 0 and standard deviation σ = 1:
ListPlot[sampleData=RandomVariate[Φ /.{μ→0, σ→1},10^4]]
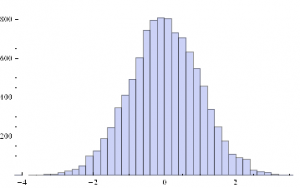
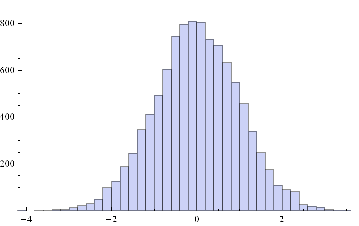
Histogram[sampleData]
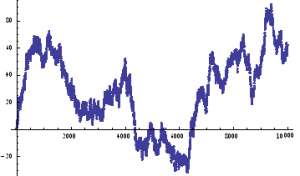
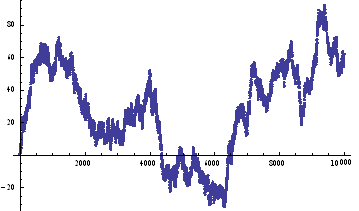
If we assume for the moment that such a process is an adequate description of an asset returns process, we can simulate the evolution of a price process as follows :
ListPlot[prices=Accumulate[sampleData]]

An Empirical Distribution
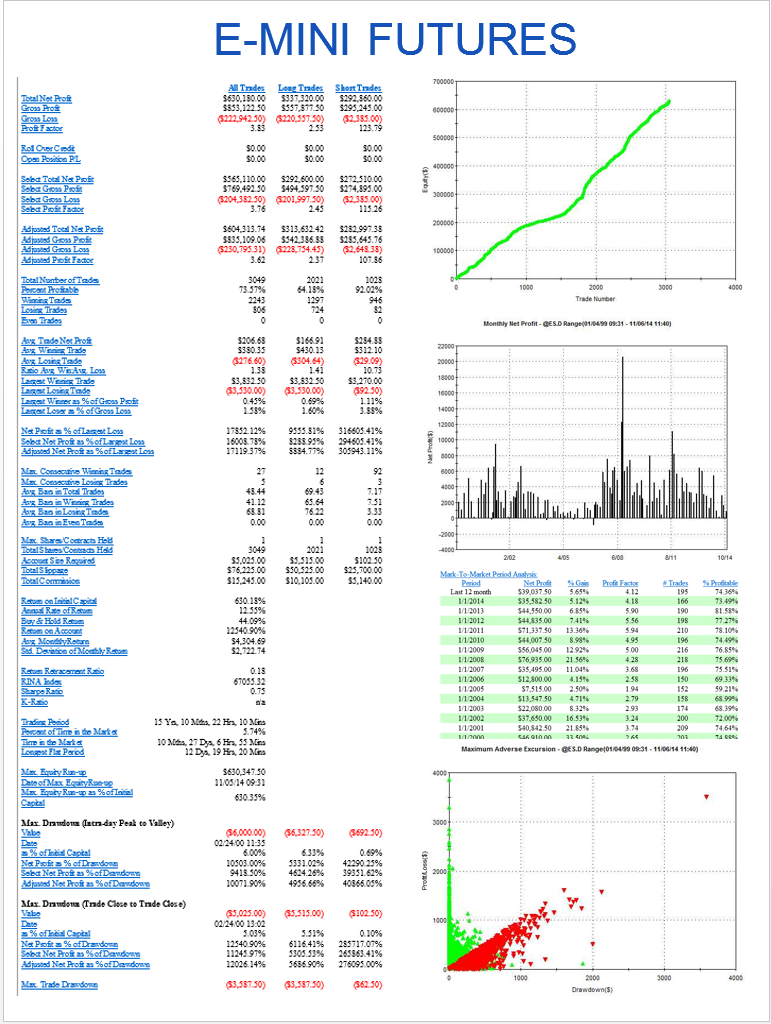
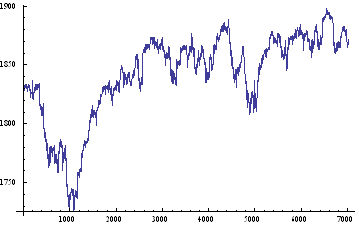
Lets take a look at a real price series, comprising 1 – minute bar data in the June ‘ 14 E – Mini futures contract.
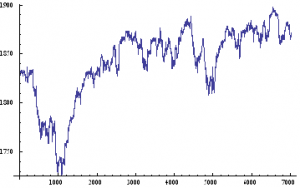
As with our simulated price process, it is clear that the real price process for Emini futures is also non – stationary.
What about the returns process?
ListPlot[returnsES]
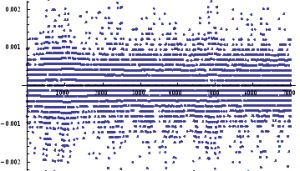
Notice the banding effect in returns, which results from having a fixed, minimum price move of $12 .50, rather than a continuous scale.
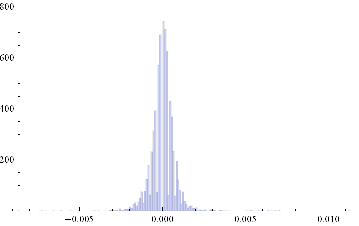
Histogram[returnsES]
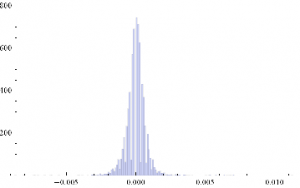
Through[{Min,Max,Mean,Median,StandardDeviation,Skewness,Kurtosis}[returnsES]]
{-0.00867214, 0.0112353, 2.75501×10-6, 0., 0.000780895, 0.35467, 26.2376}
The empirical returns distribution doesn’ t appear to be Gaussian – the distribution is much more peaked than a standard Normal distribution with the same mean and standard deviation. And the higher moments don’t fit the Normal model either – the empirical distribution has positive skew and a kurtosis that is almost 9x greater than a Gaussian distribution. The latter signifies what is often referred to as “fat tails”: the distribution has much greater weight in the tails than a standard Normal distribution, indicating a much greater likelihood of an extreme value than a Normal distribution would predict.
A Quantitative Analysis of Non-Stationarity: Two States
Non – stationarity arises when one or more of the moments of a distribution vary over time. Let’s take a look at how that can arise, and its effects.Suppose we have a Gaussian returns process for which the mean, or drift, or trend, fluctuates over time.
Let’s consider a simple example where the process drift is μ1 and volatility σ1 for most of the time and then for some proportion of time k, we get addition drift μ2 and volatility σ2. In other words we have:
Φ1=NormalDistribution[μ1,σ1]
Through[{Mean,StandardDeviation,Skewness,Kurtosis}[Φ1]]
{μ1, σ1, 0, 3}
Φ2=NormalDistribution[μ2,σ2]
Through[{Mean,StandardDeviation,Skewness,Kurtosis}[Φ2]]
{μ2, σ2, 0, 3}
This simple model fits a scenario in which we suppose that the returns process spends most of its time in State 1, in which is Normally distributed with drift is μ1 and volatility σ1, and suffers from the occasional “shock” which propels the systems into a second State 2, in which its distribution is a combination of its original distribution and a new Gaussian distribution with different mean and volatility.
Let’ s suppose that we sample the combined process y = Φ1 + k Φ2. What distribution would it have? We can represent this is follows :
y=TransformedDistribution[(x1+k x2),{x1~Φ1,x2~Φ2}]
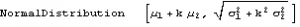
Through[{Mean,StandardDeviation,Skewness,Kurtosis}[y]]
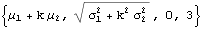
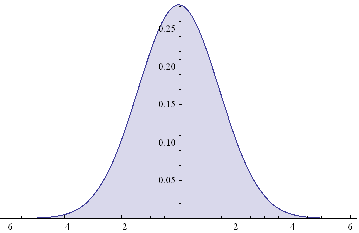
Plot[PDF[y,x]/.{μ1→0,μ2→0,σ1 →1,σ2 →2, k→0.5},{x,-6,6},Filling→Axis]
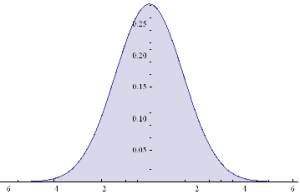
The result is just another Normal distribution. Depending on the incidence k, y will follow a Gaussian distribution whose mean and variance depend on the mean and variance of the two Normal distributions being mixed. The resulting distribution in State 2 may have higher or lower drift and volatility, but it is still Gaussian, with constant kurtosis of 3.
In other words, the system y will be non-stationary, because the first and second moments change over time, depending on what state it is in. But the form of the distribution is unchanged – it is still Gaussian. There are no fat-tails.
Non – Stationarity : Random States
In the above example the system moved between states in a known, predictable way. The “shocks” to the system were not really shocks, but transitions. But that’s not how financial markets behave: markets move from one state to another in an unpredictable way, with the arrival of news.
We can simulate this situation as follows. Using the former model as a starting point, lets now relax the assumption that the incidence of the second state, k, is a constant. Instead, let’ s assume that k is itself a random variable. In other words we are going to now assume that our system changes state in a random way. How does this alter the distribution?
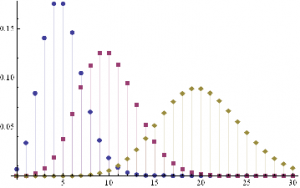
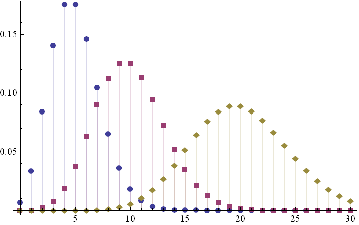
An appropriate model for λ might be a Poisson process, which is often used as a model for unpredictable, discrete events, ranging from bus arrivals to earthquakes. PDFs of Poisson distributions with means λ=5, 10 and 20 are shown in the chart below. These represent probability distributions for processes that have mean arrivals of 5, 10 or 20 events.
DiscretePlot[Evaluate@Table[PDF[PoissonDistribution[λ],k],{λ,{5,10,20}}],{k,0,30},PlotRange→All,PlotMarkers→Automatic]
Our new model now looks like this :
y=TransformedDistribution[{x1+k*x2},{x1⎡Φ1,x2⎡Φ2,k⎡PoissonDistribution[λ]}]
The first two moments of the distribution are as follows :
Through[{Mean,StandardDeviation}[y]]
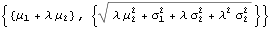
As before, the mean and standard deviation of the distribution are going to vary, depending on the state of the system, and the mean arrival rate of shocks, . But what about kurtosis? Is it still constant?
Kurtosis[y]
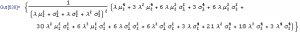
Emphatically not! The fourth moment of the distribution is now dependent on the drift in the second state, the volatilities of both states and the mean arrival rate of shocks, λ.
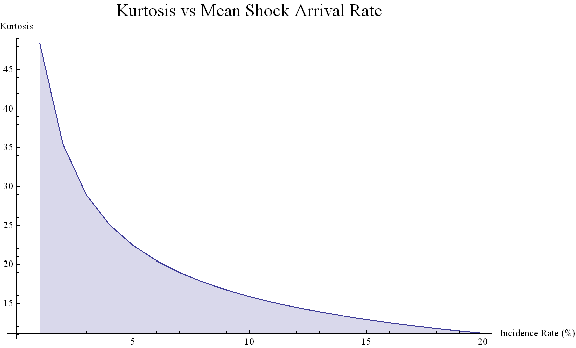
Let’ s look at a specific example. Assume that in State 1 the process has volatility of 7.5 %, with zero drift, and that the shock distribution also has zero drift with volatility of 65 %. If the mean incidence rate of shocks λ = 10 %, the distribution kurtosis is close to that seen in the empirical distribution for the E-Mini.
Kurtosis[y] /.{σ1→0.075,μ2→0,σ2→0.65,λ→0.1}
{35.3551}
More generally :
ListLinePlot[Flatten[Kurtosis[y]/.Table[{σ1→0.075,μ2→0,σ2→0.65,λ→i/20},{i,1,20}]],PlotLabel→Style[“Kurtosis vs Mean Shock Arrival Rate”, FontSize→18],AxesLabel->{“Incidence Rate (%)”, “Kurtosis”},Filling→Axis, ImageSize→Large]
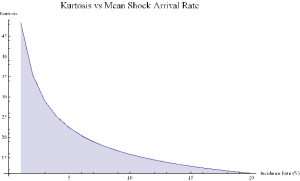
Thus we can see how, even if the underlying returns distribution is Gaussian in form, the random arrival of news “shocks” to the system can induce non – stationarity in overall drift and volatility. It can also result in fat tails. More specifically, if the arrival of news is stochastic in nature, rather than deterministic, the process may exhibit far higher levels of kurtosis than in its original Gaussian state, in which the fourth moment was a constant level of 3.
Quantitative Analysis of a Jump Diffusion Process
Nobel – prize winning economist Robert Merton extended this basic concept to the realm of stochastic calculus.
In Merton’s jump diffusion model, the stock price follows the random process
∂St / St =μdt + σdWt+(J-1)dNt
The first two terms are familiar from the Black–Scholes model : drift rate μ, volatility σ, and random walk Wt (Wiener process).The last term represents the jumps :J is the jump size as a multiple of stock price, while Nt is the number of jump events that have occurred up to time t.is assumed to follow the Poisson process.
PDF[PoissonDistribution[λt]]
where λ is the average frequency with which jumps occur.
The jump size J follows a log – normal distribution
PDF[LogNormalDistribution[m, ν], s]
where m is the average jump size and v is the volatility of the jump size.
In the jump diffusion model, the stock price St follows the random process dSt/St=μ dt+σ dWt+(J-1) dN(t), which comprises, in order, drift, diffusive, and jump components. The jumps occur according to a Poisson distribution and their size follows a log-normal distribution. The model is characterized by the diffusive volatility σ, the average jump size J (expressed as a fraction of St), the frequency of jumps λ, and the volatility of jump size ν.
The Volatility Smile
The “implied volatility” corresponding to an option price is the value of the volatility parameter for which the Black-Scholes model gives the same price. A well-known phenomenon in market option prices is the “volatility smile”, in which the implied volatility increases for strike values away from the spot price. The jump diffusion model is a generalization of Black–Scholes in which the stock price has randomly occurring jumps in addition to the random walk behavior. One of the interesting properties of this model is that it displays the volatility smile effect. In this Demonstration, we explore the Black–Scholes implied volatility of option prices (equal for both put and call options) in the jump diffusion model. The implied volatility is modeled as a function of the ratio of option strike price to spot price.




















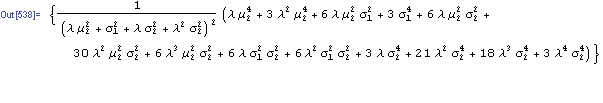
{kind=link}