Bao W, Yue J, Rao Y (2017) A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 12(7): e0180944. https://doi.org/10.1371/journal.pone.0180944
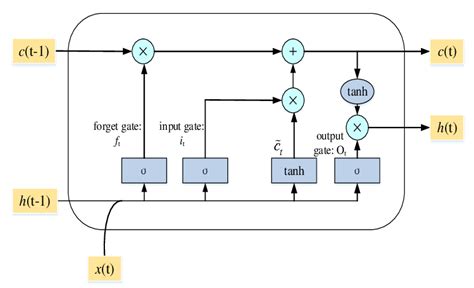
The chief claim by the researchers is that 90% to 95% 1-day ahead forecast accuracy can be achieved for a selection of market indices, including the S&P500 and Dow Jones Industrial Average, using a deep learning network of stacked autoencoders and LSTM layers, acting on data transformed using the Haar Discrete Wavelet Transform. The raw data comprises daily data for the index, around a dozen standard technical indicators, the US dollar index and an interest rate series.
Before we go into any detail let’s just step back and look at the larger picture. We have:
Unknown researchers
A journal from outside the field of finance
A paper replete with pretty colored images, but very skimpy detail on the methodology
A claimed result that lies far beyond the bounds of credibility
There’s enough red flags here to start a stampede at Pamplona. Let’s go through them one by one:
Everyone is unknown at some point in their career. But that’s precisely why you partner with a widely published author. It gives the reader confidence that the paper isn’t complete garbage.
Not everyone gets to publish in the Journal of Finance. I get that. How many of us were regular readers of the Journal of Political Economy before Black and Scholes published their famous paper on option pricing in 1973? Nevertheless, a finance paper published in a medical journal does not inspire great confidence.
Read almost any paper by a well known researcher and you will find copious detail on the methodology. These days, the paper is often accompanied by a Git repo (add 3 stars for this!). Academics producing quality research want readers to be able to replicate and validate their findings. In this paper there are lots of generic, pretty colored graphics of deep learning networks, but no code repo and very little detail on the methodology. If you don’t want to publish details because the methodology is proprietary and potentially valuable, then do what I do: don’t publish at all.
One-day ahead forecasting accuracy of 53%-55% is good (52%-53% in HFT). 60% accuracy is outstanding. 90% – 95% is unbelievable. It’s a license to print money. So what we are being asked to believe is through a combination of data smoothing (which is all DWT is), dimensionality reduction (stacked autoencoders) and long-memory modeling, we can somehow improve forecasting accuracy over, say, a gradient boosted tree baseline, by something like 40%. It simply isn’t credible.
These simple considerations should be enough for any experienced quant to give the paper a wide berth.
Digging into the Methodology
Discrete Wavelet Transform
So we start from a raw dataset with variables that closely match those described in the paper (see headers for details). Of course, I don’t know the parameter values they used for most of the technical indicators, but it possibly doesn’t matter all that much.
Note that I am applying DWT using the Haar wavelet twice: once to the original data and then again to the transformed data. This has the effect of filtering out higher frequency “noise” in the data, which is the object of the exercise. If follow this you will also see that the DWT actually adds noisy fluctuations to the US Dollar index and 13-Week TBill series. So these should be excluded from the de-noising process. You can see how the DWT denoising process removes some of the higher frequency fluctuations from the opening price, for instance:
2. Stacked Autoencoders
First up, we need to produce data for training, validation and testing. I am doing this for just the first batch of data. We would then move the window forward + 3 months, rinse and repeat.
Note that:
(1) The data is being standardized. If you don’t do this the outputs from the autoencoders is mostly just 1s and 0s. Same happens if you use Min/Max scaling.
(2) We use the mean and standard deviation from the training dataset to normalize the test dataset. This is a trap that too many researchers fall into – standardizing the test dataset using the mean and standard deviation of the test dataset is feeding forward information.
The Autoencoder stack uses a hidden layer of size 10 in each encoder. We strip the output layer from the first encoder and use the hidden layer as inputs to the second autoencoder, and so on:
3. Benchmark Model
Before we plow on any further lets do a sanity check. We’ll use the Predict function to see if we’re able to get any promising-looking results. Here we are building a Gradient Boosted Trees predictor that maps the autoencoded training data to the corresponding closing prices of the index, one step ahead.
Next we use the predictor on the test dataset to produce 1-step-ahead forecasts for the closing price of the index.
Finally, we construct a trading model, as described in the paper, in which we go long or short the index depending on whether the forecast is above or below the current index level. The results do not look good (see below).
Now, admittedly, an argument can be made that a properly constructed LSTM model would outperform a simple gradient-boosted tree – but not by the amount that would be required to improve the prediction accuracy from around 50% to nearer 95%, the level claimed in the paper. At most I would expect to see a 1% to 5% improvement in forecast accuracy.
So what this suggests to me is that the researchers have got something wrong, by somehow allowing forward information to leak into the modeling process. The most likely culprits are:
Applying DWT transforms to the entire dataset, instead of the training and test sets individually
Standardzing the test dataset using the mean and standard deviation of the test dataset, instead of the training data set
A More Complete Attempt to Replicate the Research
There’s a much more complete attempt at replicating the research in this Git repo
As the repo author writes:
My attempts haven’t been succesful so far. Given the very limited comments regarding implementation in the article, it may be the case that I am missing something important, however the results seem too good to be true, so my assumption is that the authors have a bug in their own implementation. I would of course be happy to be proven wrong about this statement 😉
Conclusion
Over time, as one’s experience as a quant deepens, you learn to recognize the signs of shoddy research and save yourself the effort of trying to replicate it. It’s actually easier these days for researchers to fool themselves (and their readers) that they have uncovered something interesting, because of the facility with which complex algorithms can be deployed in an inappropriate way.
Postscript
This paper echos my concerns about the incorrect use of wavelets in a forecasting context:
The incorrect development of these wavelet-based forecasting models occurs during wavelet decomposition (the process of extracting high- and low-frequency information into different sub-time series known as wavelet and scaling coefficients, respectively) and as a result introduces error into the forecast model inputs. The source of this error is due to the boundary condition that is associated with wavelet decomposition (and the wavelet and scaling coefficients) and is linked to three main issues: 1) using ‘future data’ (i.e., data from the future that is not available); 2) inappropriately selecting decomposition levels and wavelet filters; and 3) not carefully partitioning calibration and validation data.
The principal argument in favor of using synthetic data is that it addresses one of the major concerns about using real data series for modelling purposes: i.e. that models designed to fit the historical data produce test results that are unlikely to be replicated, going forward. Such models are not robust to changes that are likely to occur in any dynamical statistical process and will consequently perform poorly out of sample.
By using multiple synthetic data series following a wide range of different price paths, one can hope to build models – both for risk management and investment purposes – that can accommodate a variety of different market scenarios, making them more likely to perform robustly in a live market context.
Producing authentic synthetic data is a significant challenge, one that has eluded researchers for many years. Generating artificial returns series is a considerably simpler task, but even here there are difficulties. For many applications it is simply not sufficient to sample from the empirical distribution, because we want to produce a sequence of returns that closely mirrors the pattern of real returns sequences. In particular, there may be long memory effects (non-zero autocorrelations at long lags) or GARCH effects, in which dependency is introduced into the returns process via the square (or absolute value) of returns. These have the effect of inducing “shocks” to the returns process that persist for some time, causing autocorrelation in the associated volatility process in the process.
But producing a set of synthetic stock price data is even more of a challenge because not only do the above do the above requirements apply, but we also need to ensure that the open, high, low and closing prices are internally consistent, i.e. that on any given bar the High >= {Open, Low and Close) and that the Low <= {Open, Close}. These basic consistency checks have been overlooked in the research thus far.
Econometric Methods
One classical approach to the problem would be to create a Vector Autoregression Model, in which lagged values of the Open, High, Low and Close prices are used to predict the current values (see here for a detailed exposition of the VAR approach). A compelling argument in favor of such models is that, almost by definition, O/H/L/C prices are necessarily cointegrated.
While a VAR model potentially has the ability to model long memory and even GARCH effects, it is unable to produce stock prices that are guaranteed to be consistent, in the sense defined above. Indeed, a failure rate of 35% or higher for basic consistency checks is typical for such a model, making the usefulness of the synthetic prices series highly questionable.
Another approach favored by some researchers is to stitch together sub-samples of the real data series in a varying time-order. This is applicable only to return series and, in any case, can introduce spurious autocorrelations, or overlook important dependencies in the data series. Besides these defects, it is challenging to produce a synthetic series that looks substantially different from the original – both the real and synthetic series exhibit common peaks and troughs, even if they occur in different places in each series.
Deep Learning Generative Adversarial Networks
In a previous post I looked in some detail at TimeGAN, one of the more recent methods for producing synthetic data series introduced in a paper in 2019 by Yoon, et al (link here).
TimeGAN, which applies deep learning Generative Adversarial Networks to create synthetic data series, appears to work quite well for certain types of time series. But in my research I found it be inadequate for the purpose of producing synthetic stock data, for three reasons:
(i) The model produces synthetic data of fixed window lengths and stitching these together to form a single series can be problematic.
(ii) The prices fail a significant percentage of the basic consistency tests, regardless of the number of epochs used to train the model
(iii) The methodology introduces spurious correlations in the associated returns process that do not correspond to anything found in real stock return series and which get more pronounced as training continues.
Another GAN model, DoppleGANger, introduced by Lin, et. al. in 2020 (paper here) seeks to improve on TimeGAN and claims “up to 43% better fidelity than baseline models”, including TimeGAN. However, in my research I found that, while DoppleGANger trains much more quickly than TimeGAN, it produces a consistency test failure rate exceeding 30%, even after training for 500,000 epochs.
For both TimeGAN and DoppleGANger, the researchers have tended to benchmark performance using classical data science metrics such as TSNE plots rather than the more prosaic consistency checks that a market data specialist would be interested in, while the more advanced requirements such as long memory and GARCH effects are passed by without a mention.
The conclusion is that current methods fail to provide an adequate means of generating synthetic price series for financial assets that are consistent and sufficiently representative to be practically useful.
The Ideal Algorithm for Producing Synthetic Data Series
What are we looking for in the ideal algorithm for generating stock prices? The list would include:
(i) Computational simplicity & efficiency. Important if we are looking to mass-produce synthetic series for a large number of assets, for a variety of different applications. Some deep learning methods would struggle to meet this requirement, even supposing that transfer learning is possible.
(ii) The ability to produce price series that are internally consistent (i.e High > Low, etc) in every case .
(iii) Should be able to produce a range of synthetic series that vary widely in their correspondence to the original price series. In some case we want synthetic price series that are highly correlated to the original; in other cases we might want to test our investment portfolio or risk control systems under extreme conditions never before seen in the market.
(iv) The distribution of returns in the synthetic series should closely match the historical series, being non-Gaussian and with “fat-tails”.
(v) The ability to incorporate long memory effects in the sequence of returns.
(vi) The ability to model GARCH effects in the returns process.
After researching the problem over the course of many years, I have at last succeeded in developing an algorithm that meets these requirements. Before delving into the mechanics, let me begin by illustrating its application.
Application of the Ideal Algorithm
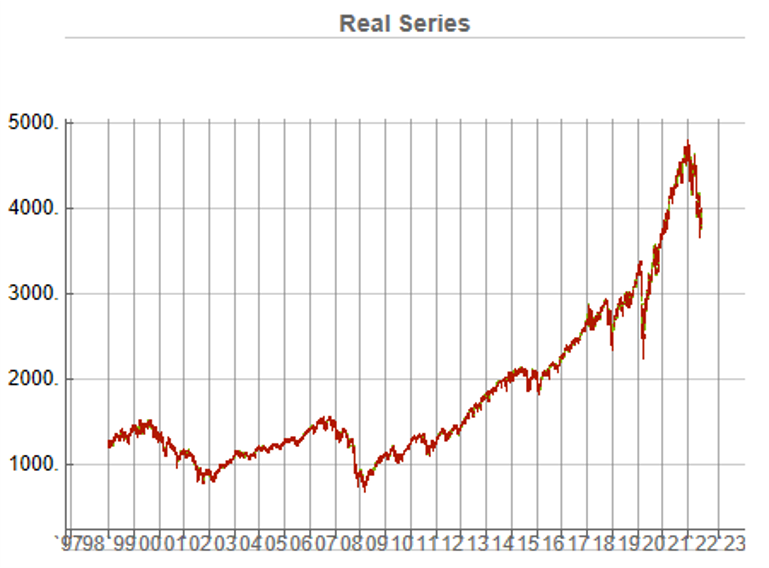
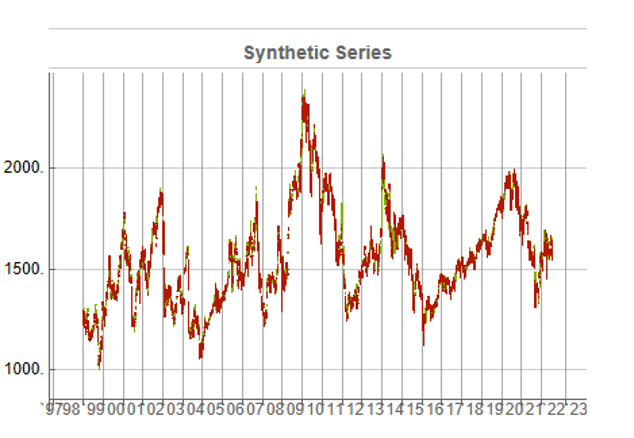
In this demonstration I am using daily O/H/L/C prices for the S&P 500 index for the period from Jan 1999 to July 2022, comprising four price series over 5,297 daily periods.
Synthetic Price Series
Generating ten synthetic series using the algorithm takes around 2 seconds with parallelization. I chose to generate series of the same length as the original, although I could just as easily have produced shorter, or longer sequences.
The first task is to confirm that the synthetic data are internally consistent, and indeed is guaranteed to be so because of the way the algorithm is designed. For example, here are the first few daily bars from the first synthetic series:
This means, of course, that we can immediately plot the synthetic series in a candlestick chart, just as we did with the real data series, above.
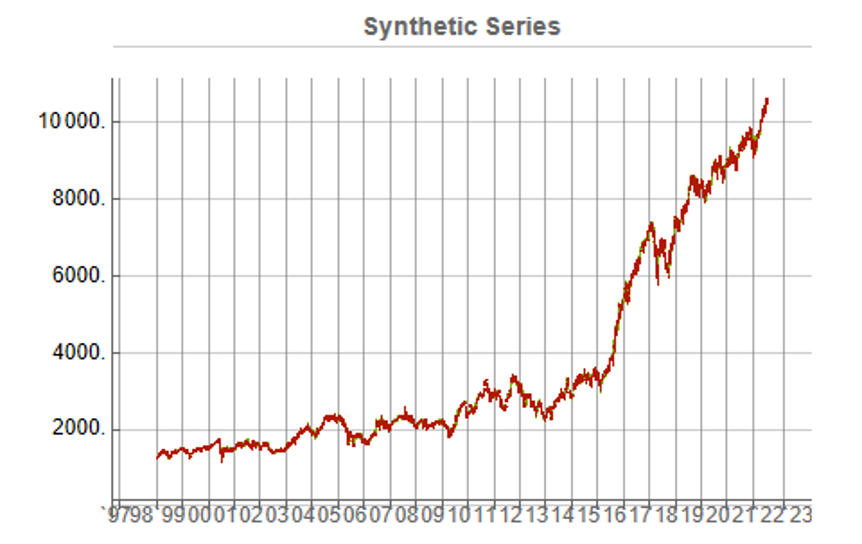
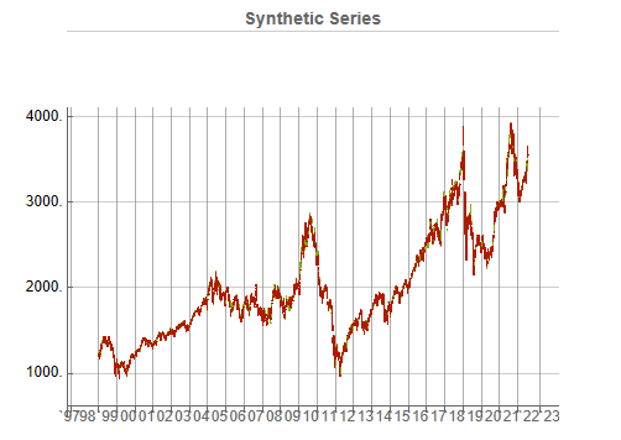
While the real and synthetic series are clearly different, the pattern of peaks and troughs somehow looks recognizably familiar. So, too, is the upward drift in the series, which is this case carries the synthetic S&P 500 Index to a high above 10,000 in 2022. Obviously this is a much more bullish scenario that we have seen in reality. But in fact this is just one example taken from the more “optimistic” end of the spectrum of possibilities. An illustration from the opposite end of the spectrum is shown in the chart below, in which the Index moves sideways over the entire 23 year span, with several very large drawdowns of -20% or more:
A more typical scenario might look something like our third chart, below. Here, too, we see several very large drawdowns, especially in the period from 2010-2011, but there is also a general upward drift in the process that enables the Index to reach levels comparable to those achieved by the real series:
Price Correlations
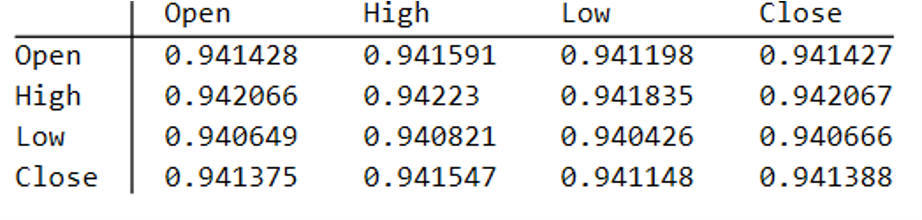
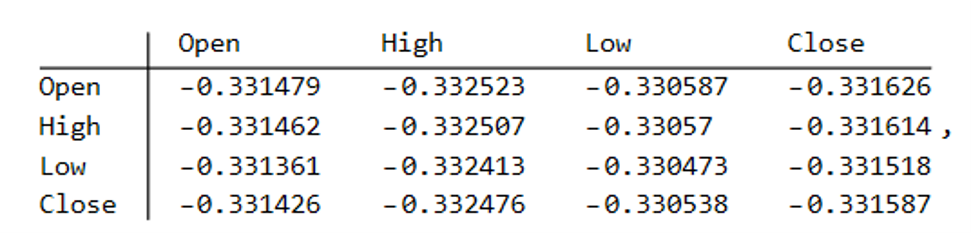
Reflecting these very different price path evolutions, we observe large variation in the correlations between the real and synthetic price series. For example:
As these tables indicate, the algorithm is capable of producing replica series that either mimic the original, real price series very closely, or which show completely different behavior, as in the second example.
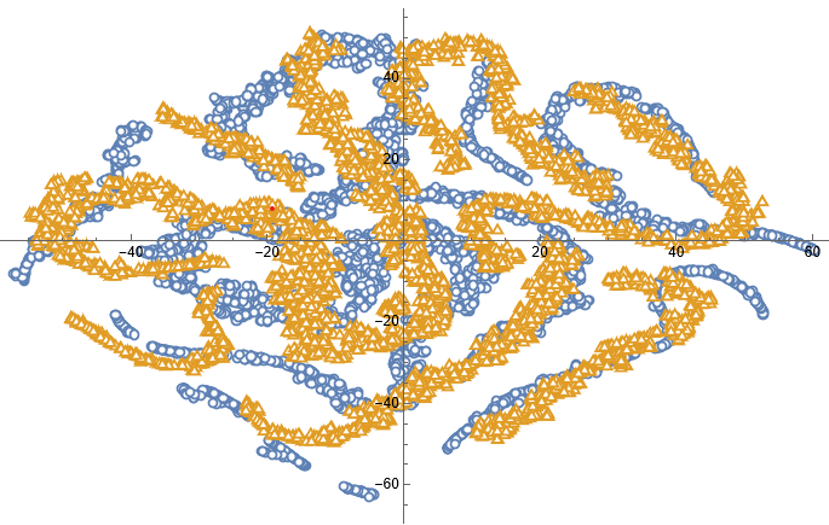
Dimensionality Reduction
For completeness, as have previous researchers, we apply t-SNE dimensionality reduction and plot the two-factor weightings for both real (yellow) and synthetic data (blue). We observe that while there is considerable overlap in reduced dimensional space, it is not as pronounced as for the synthetic data produced by TimeGAN, for instance. However, as previously explained, we are less concerned by this than we are about the tests previously described, which in our view provide a more appropriate analysis benchmark, so far as market data is concerned. Furthermore, for the reasons previously given, we want synthetic market data that in some cases tracks well beyond the range seen in historical price series.
Returns Distributions
Moving on, we next consider the characteristics of the returns in the synthetic series in comparison to the real data series, where returns are measured as the differences in the Log-Close prices, in the usual way.
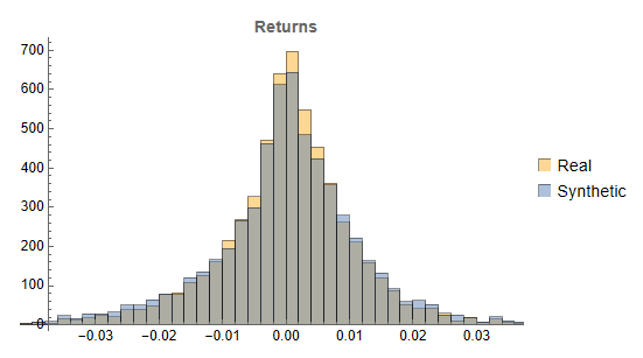
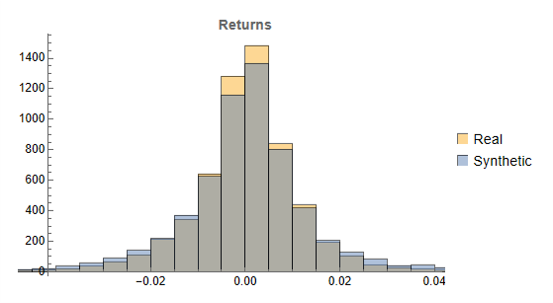
Histograms of the returns for the most “optimistic” and “pessimistic” scenarios charted previously are shown below:
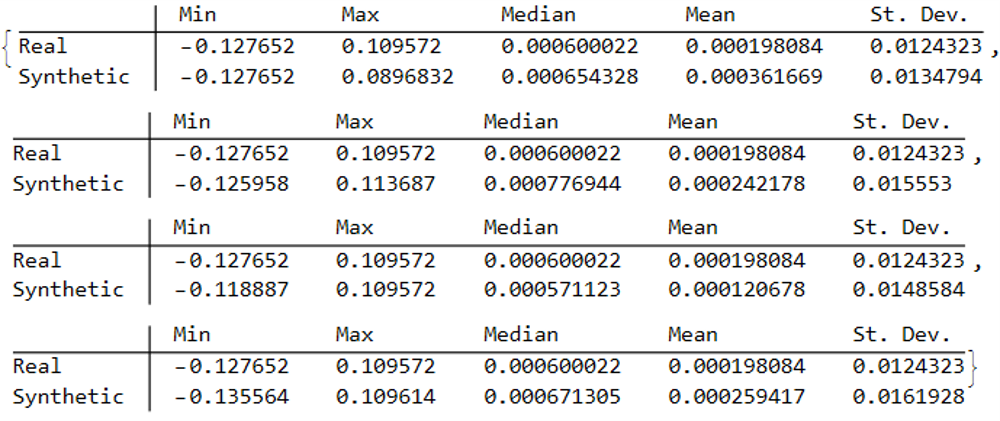
In both cases the distribution of returns in the synthetic series closely matches that of the real returns process and are clearly non-Gaussian, with an over-weighting in the distribution tails. A more detailed look at the distribution characteristics for the first four synthetic series indicates that there is a very good match to the real returns process in each case (the results for other series are very similar):
We observe that the minimum and maximum returns of the synthetic series sometimes exceed those of the real series, which can be a useful characteristic for risk management applications. The median and mean of the real and synthetic series are broadly similar, sometimes higher, in other cases lower. Only for the standard deviation of returns do we observe a systematic pattern, in which returns volatility in the synthetic series is consistently higher than in the real series.
This feature, I would argue, is both appropriate and useful. Standard deviations should generally be higher, because there is indeed greater uncertainty about the prices and returns in artificially generated synthetic data, compared to the real series. Moreover, this characteristic is useful, because it will impose a greater stress-test burden on risk management systems compared to simply drawing from the distribution of real returns using Monte Carlo simulation. Put simply, there will be a greater number of more extreme tail events in scenarios using synthetic data, and this will cause risk control parameters to be set more conservatively than they otherwise might. This same characteristic – the greater variation in prices and returns – will also pose a tougher challenge for AI systems that attempt to create trading strategies using genetic programming, meaning that any such strategies are more likely to perform robustly in a live trading environment. I will be returning to this issue in a follow-up post.
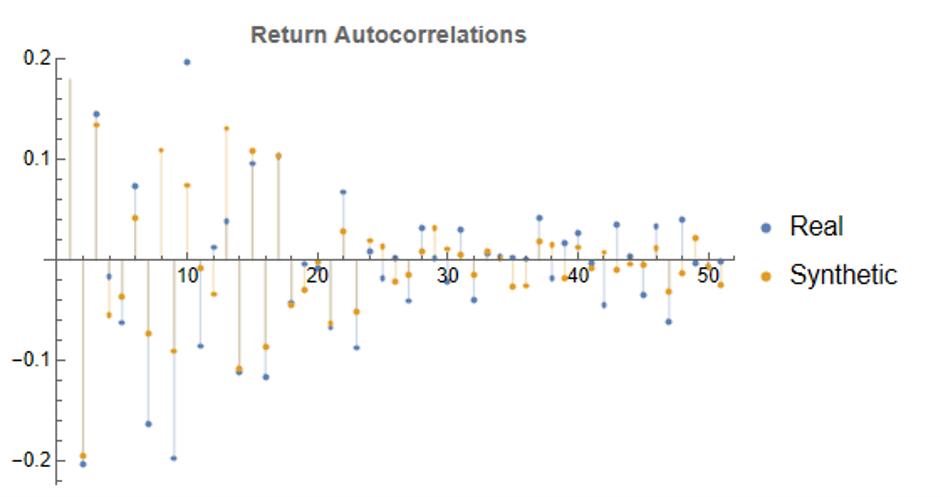
Returns Process Characteristics
In the following plot we take a look at the autocorrelations in the returns process for a typical synthetic series. These compare closely with the autocorrelations in the real returns series up to 50 lags, which means that any long memory effects are likely to be conserved.
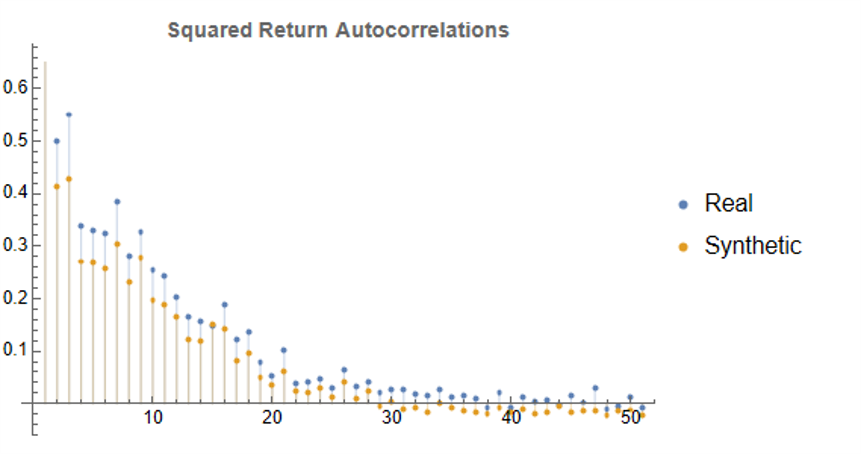
Finally, when we come to consider the autocorrelations in the square of the returns, we observe slowly decaying coefficients over long lags – evidence of so-called GARCH effects – for both real and synthetic series:
Summary
Overall, we observe that the algorithm is capable of generating consistent stock price series that correlate highly with the real price series. It is also capable of generating price series that have low, or even negative, correlation, a feature that may have important applications in the context of risk management. The distribution of returns in the synthetic series closely match those of the real returns process, and moreover retain important features such as long memory and GARCH effects.
Objections to the Use of Synthetic Data
Criticism of synthetic market data (including from myself) has hitherto focused on the inadequacy of such data in terms of representing important characteristics of real data series. Now that such technical issues have been addressed, I will try to anticipate some of the additional concerns that are likely to surface, going forward.
The Synthetic Data is “Unrealistic”
What is meant here is that there is no plausible set of real, economic factors that would be likely to combine in a way to produce the pattern of prices shown in some of the synthetic data series. The idea that, as observed in one of the artificial scenarios above, the Fed would stand idly by while the market plunged by 50% to 60%, seems highly implausible. Equally unlikely is a scenario in which the market moves sideways for an extended period of a decade, or longer.
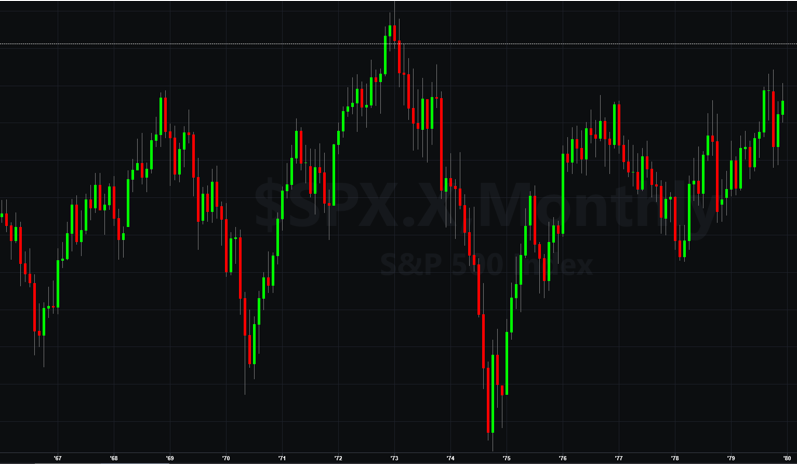
To a limited extent, I would agree with this. However, just because such scenarios are currently unlikely doesn’t mean they can never happen. For instance, take a look at the performance of the S&P 500 Index over the period from 1966 through 1979:
The market index barely made any progress throughout the entire 13-year period, which was characterized by a vicious bout of stagflation. Note, too, the precipitous drop in the index following the oil shock in 1973.
So to say that such scenarios – however implausible they may appear to be – can never happen is simply mistaken.
Finally, let’s not forget that, while the focus of this article is on the US market index, there are many economies, such as Mexico, Brazil or Argentina, for which such adverse developments are much more credible than they might currently be for the United States. We may wish to produce synthetic data for the markets in such economies for modelling purposes, in which case we will want to generate synthetic data capturing the full range of possible market outcomes, including some of the worst-case scenarios.
2. Extreme Scenarios Occur Too Frequently in Synthetic Data
Actually this is not the case – the generator tends to produce extreme scenarios with a frequency that is plausible, given the history and characteristics of the underlying, real price process. But there can be good reasons for wanting to control the frequency of such scenarios.
For instance, an investment manager may be looking to develop a “long-only” investment portfolio because, given his investment remit, that is the only type of investment strategy permitted. He would likely want to limit his focus to the more benign market outcomes for two reasons: (i) his investment thesis is that the market is likely to perform well, going forward (or else how does he pitch his strategy to investors?) and (ii) while he accepts that he may be wrong, it is not his job to hedge a possible market downturn – the responsibility for dealing with an adverse outcome falls to his risk manager, or to the investor.
Conversely, a risk manager is much more likely to be interested in adverse scenarios and, if anything, is likely to want to see such outcomes over-represented in a sample of synthetic data.
The point is, there is no “correct” answer: one has to decide which types of scenarios best suit the application one has in mind and sample the data accordingly. This can be done in a variety of ways such as setting a minimum required correlation between the synthetic and real price series, or designing a system of stratified sampling in which the desired outcomes are sampled according to a stipulated frequency distribution.
3. Synthetic Data Does Not Prevent Data Snooping and Curve Fitting
A critic might argue that, in fact, the real market data is “unseen” only in a theoretical sense, since its essential attributes have been baked into the synthetic series produced by the generator. This applies to an even greater extent if the synthetic series are sampled in some way, as described above.
I think this is a fair point. To take an extreme scenario, one could choose to select only synthetic series for which the correlation with the real data is 99.9%, or higher. Clearly this runs counter to the spirit of what one is trying to achieve with synthetic data and one might just as well use real data for modelling purposes. In practice, of course, even where a sampling methodology is applied, it is unlikely to be as crudely biased as in this example.
But, in any case, what is the alternative? The only option I can see is one in which a pure mathematical model is used to produce synthetic data, without any reference to the underlying real series. But, in that case, how would one assess the validity of the model assumptions, or how representative the synthetic series it produces might be?
There is no alternative but to have recourse to the real data at some point in the modelling process. In this procedure, however, the impact of snooping bias or curve fitting, even though it can never be totally extinguished, is very much diminished and it plays a less central role in model development.
Conclusion
It is now possible to produce synthetic data series that have all of the hallmark characteristics of real price data. This permits the analyst to investigate market models without direct recourse to the real price series, thereby minimizing data snooping and curve fitting bias. Models developed using synthetic data describing many different price path evolutions are more likely to prove robust across a wider range of plausible market scenarios in the real world.
In the next, follow-up post I will illustrate the application of synthetic data to the development of a robust investment strategy.
Building a deep learning neural network is a complicated and time-consuming task. For some problems it can be easier to re-purpose an existing deep learning model, making minor adjustments to a small number of layers to achieve desired architecture.
In his new book Introduction to Machine Learning, Etienne Bernard gives a nice example of the technique.
We begin with a dataset comprising images of two types of mushroom, with the aim of building a specialized image classifier.
Using a Neural Network for Feature Extraction
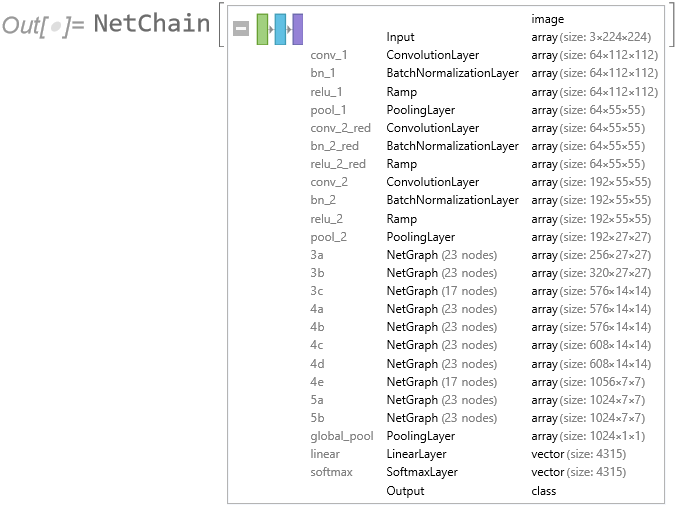
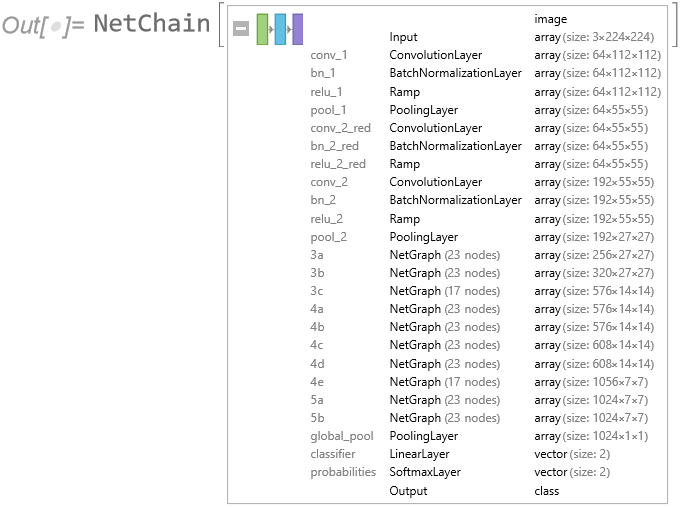
We start from the Wolfram ImageIdentify net, which is a 24-layer convolutional neural network trained on around 4000 image types.
net=NetModel[“Wolfram ImageIdentify Net V1”]
In its current form the net is too generalized for our task:
Mushroom
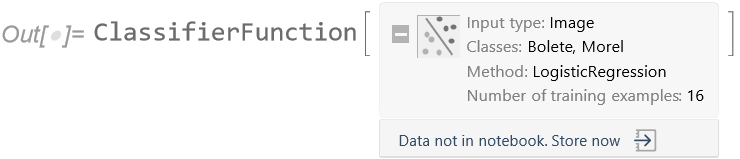
So instead of using the net in raw form, we use the first 22 layers as a feature extractor. This will preprocess each image to obtain features that are semantically richer than simple pixel values. We can then train a classifier on top of these new features, producing a logistic regression model:
This is much better than training directly on the underlying pixel values, which would result in an accuracy of around 44%, worse than random guessing.
Neural Network Transfer Learning
Moving on from Etienne’s feature extraction approach, we next try creating a new neural network by re-using the first 22 layers of the ImageIdentify network, adding two new layers (a LinearLayer and SoftmaxLayer) for mushroom classification:
We re-train the new network using the mushroom training dataset, holding the weights for the first 22 layers at their existing values (i.e. only training the last two, new layers):